 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Reasoning with Vision-Language Models for Estimating Long-Horizon Embodied Task Progress
Mar 18, 2026Accurately estimating task progress is critical for embodied agents to plan and execute long-horizon, multi-step tasks. Despite promising advances, existing Vision-Language Models (VLMs) based methods primarily leverage their video understanding capabilities, while neglecting their complex reasoning potential. Furthermore, processing long video trajectories with VLMs is computationally prohibitive for real-world deployment. To address these challenges, we propose the Recurrent Reasoning Vision-Language Model ($\text{R}^2$VLM). Our model features a recurrent reasoning framework that processes local video snippets iteratively, maintaining a global context through an evolving Chain of Thought (CoT). This CoT explicitly records task decomposition, key steps, and their completion status, enabling the model to reason about complex temporal dependencies. This design avoids the high cost of processing long videos while preserving essential reasoning capabilities. We train $\text{R}^2$VLM on large-scale, automatically generated datasets from ALFRED and Ego4D. Extensive experiments on progress estimation and downstream applications, including progress-enhanced policy learning, reward modeling for reinforcement learning, and proactive assistance, demonstrate that $\text{R}^2$VLM achieves strong performance and generalization, achieving a new state-of-the-art in long-horizon task progress estimation. The models and benchmarks are publicly available at \href{https://huggingface.co/collections/zhangyuelin/r2vlm}{huggingface}.
ReconDrive: Fast Feed-Forward 4D Gaussian Splatting for Autonomous Driving Scene Reconstruction
Mar 08, 2026High-fidelity visual reconstruction and novel-view synthesis are essential for realistic closed-loop evaluation in autonomous driving. While 4D Gaussian Splatting (4DGS) offers a promising balance of accuracy and efficiency, existing per-scene optimization methods require costly iterative refinement, rendering them unscalable for extensive urban environments. Conversely, current feed-forward approaches often suffer from degraded photometric quality. To address these limitations, we propose ReconDrive, a feed-forward framework that leverages and extends the 3D foundation model VGGT for rapid, high-fidelity 4DGS generation. Our architecture introduces two core adaptations to tailor the foundation model to dynamic driving scenes: (1) Hybrid Gaussian Prediction Heads, which decouple the regression of spatial coordinates and appearance attributes to overcome the photometric deficiencies inherent in generalized foundation features; and (2) a Static-Dynamic 4D Composition strategy that explicitly captures temporal motion via velocity modeling to represent complex dynamic environments. Benchmarked on nuScenes, ReconDrive significantly outperforms existing feed-forward baselines in reconstruction, novel-view synthesis, and 3D perception. It achieves performance competitive with per-scene optimization while being orders of magnitude faster, providing a scalable and practical solution for realistic driving simulation.
Beyond Benchmarks of IUGC: Rethinking Requirements of Deep Learning Methods for Intrapartum Ultrasound Biometry from Fetal Ultrasound Videos
Feb 13, 2026A substantial proportion (45\%) of maternal deaths, neonatal deaths, and stillbirths occur during the intrapartum phase, with a particularly high burden in low- and middle-income countries. Intrapartum biometry plays a critical role in monitoring labor progression; however, the routine use of ultrasound in resource-limited settings is hindered by a shortage of trained sonographers. To address this challenge, the Intrapartum Ultrasound Grand Challenge (IUGC), co-hosted with MICCAI 2024, was launched. The IUGC introduces a clinically oriented multi-task automatic measurement framework that integrates standard plane classification, fetal head-pubic symphysis segmentation, and biometry, enabling algorithms to exploit complementary task information for more accurate estimation. Furthermore, the challenge releases the largest multi-center intrapartum ultrasound video dataset to date, comprising 774 videos (68,106 frames) collected from three hospitals, providing a robust foundation for model training and evaluation. In this study, we present a comprehensive overview of the challenge design, review the submissions from eight participating teams, and analyze their methods from five perspectives: preprocessing, data augmentation, learning strategy, model architecture, and post-processing. In addition, we perform a systematic analysis of the benchmark results to identify key bottlenecks, explore potential solutions, and highlight open challenges for future research. Although encouraging performance has been achieved, our findings indicate that the field remains at an early stage, and further in-depth investigation is required before large-scale clinical deployment. All benchmark solutions and the complete dataset have been publicly released to facilitate reproducible research and promote continued advances in automatic intrapartum ultrasound biometry.
Consensus-Aligned Neuron Efficient Fine-Tuning Large Language Models for Multi-Domain Machine Translation
Feb 05, 2026Multi-domain machine translation (MDMT) aims to build a unified model capable of translating content across diverse domains. Despite the impressive machine translation capabilities demonstrated by large language models (LLMs), domain adaptation still remains a challenge for LLMs. Existing MDMT methods such as in-context learning and parameter-efficient fine-tuning often suffer from domain shift, parameter interference and limited generalization. In this work, we propose a neuron-efficient fine-tuning framework for MDMT that identifies and updates consensus-aligned neurons within LLMs. These neurons are selected by maximizing the mutual information between neuron behavior and domain features, enabling LLMs to capture both generalizable translation patterns and domain-specific nuances. Our method then fine-tunes LLMs guided by these neurons, effectively mitigating parameter interference and domain-specific overfitting. Comprehensive experiments on three LLMs across ten German-English and Chinese-English translation domains evidence that our method consistently outperforms strong PEFT baselines on both seen and unseen domains, achieving state-of-the-art performance.
Baseline Method of the Foundation Model Challenge for Ultrasound Image Analysis
Feb 01, 2026Ultrasound (US) imaging exhibits substantial heterogeneity across anatomical structures and acquisition protocols, posing significant challenges to the development of generalizable analysis models. Most existing methods are task-specific, limiting their suitability as clinically deployable foundation models. To address this limitation, the Foundation Model Challenge for Ultrasound Image Analysis (FM\_UIA~2026) introduces a large-scale multi-task benchmark comprising 27 subtasks across segmentation, classification, detection, and regression. In this paper, we present the official baseline for FM\_UIA~2026 based on a unified Multi-Head Multi-Task Learning (MH-MTL) framework that supports all tasks within a single shared network. The model employs an ImageNet-pretrained EfficientNet--B4 backbone for robust feature extraction, combined with a Feature Pyramid Network (FPN) to capture multi-scale contextual information. A task-specific routing strategy enables global tasks to leverage high-level semantic features, while dense prediction tasks exploit spatially detailed FPN representations. Training incorporates a composite loss with task-adaptive learning rate scaling and a cosine annealing schedule. Validation results demonstrate the feasibility and robustness of this unified design, establishing a strong and extensible baseline for ultrasound foundation model research. The code and dataset are publicly available at \href{https://github.com/lijiake2408/Foundation-Model-Challenge-for-Ultrasound-Image-Analysis}{GitHub}.
FUGC: Benchmarking Semi-Supervised Learning Methods for Cervical Segmentation
Jan 22, 2026Accurate segmentation of cervical structures in transvaginal ultrasound (TVS) is critical for assessing the risk of spontaneous preterm birth (PTB), yet the scarcity of labeled data limits the performance of supervised learning approaches. This paper introduces the Fetal Ultrasound Grand Challenge (FUGC), the first benchmark for semi-supervised learning in cervical segmentation, hosted at ISBI 2025. FUGC provides a dataset of 890 TVS images, including 500 training images, 90 validation images, and 300 test images. Methods were evaluated using the Dice Similarity Coefficient (DSC), Hausdorff Distance (HD), and runtime (RT), with a weighted combination of 0.4/0.4/0.2. The challenge attracted 10 teams with 82 participants submitting innovative solutions. The best-performing methods for each individual metric achieved 90.26\% mDSC, 38.88 mHD, and 32.85 ms RT, respectively. FUGC establishes a standardized benchmark for cervical segmentation, demonstrates the efficacy of semi-supervised methods with limited labeled data, and provides a foundation for AI-assisted clinical PTB risk assessment.
Multilingual Generative Retrieval via Cross-lingual Semantic Compression
Oct 09, 2025



Generative Information Retrieval is an emerging retrieval paradigm that exhibits remarkable performance in monolingual scenarios.However, applying these methods to multilingual retrieval still encounters two primary challenges, cross-lingual identifier misalignment and identifier inflation. To address these limitations, we propose Multilingual Generative Retrieval via Cross-lingual Semantic Compression (MGR-CSC), a novel framework that unifies semantically equivalent multilingual keywords into shared atoms to align semantics and compresses the identifier space, and we propose a dynamic multi-step constrained decoding strategy during retrieval. MGR-CSC improves cross-lingual alignment by assigning consistent identifiers and enhances decoding efficiency by reducing redundancy. Experiments demonstrate that MGR-CSC achieves outstanding retrieval accuracy, improving by 6.83% on mMarco100k and 4.77% on mNQ320k, while reducing document identifiers length by 74.51% and 78.2%, respectively.
SageLM: A Multi-aspect and Explainable Large Language Model for Speech Judgement
Aug 28, 2025Speech-to-Speech (S2S) Large Language Models (LLMs) are foundational to natural human-computer interaction, enabling end-to-end spoken dialogue systems. However, evaluating these models remains a fundamental challenge. We propose \texttt{SageLM}, an end-to-end, multi-aspect, and explainable speech LLM for comprehensive S2S LLMs evaluation. First, unlike cascaded approaches that disregard acoustic features, SageLM jointly assesses both semantic and acoustic dimensions. Second, it leverages rationale-based supervision to enhance explainability and guide model learning, achieving superior alignment with evaluation outcomes compared to rule-based reinforcement learning methods. Third, we introduce \textit{SpeechFeedback}, a synthetic preference dataset, and employ a two-stage training paradigm to mitigate the scarcity of speech preference data. Trained on both semantic and acoustic dimensions, SageLM achieves an 82.79\% agreement rate with human evaluators, outperforming cascaded and SLM-based baselines by at least 7.42\% and 26.20\%, respectively.
ReconVLA: Reconstructive Vision-Language-Action Model as Effective Robot Perceiver
Aug 14, 2025



Recent advances in Vision-Language-Action (VLA) models have enabled robotic agents to integrate multimodal understanding with action execution. However, our empirical analysis reveals that current VLAs struggle to allocate visual attention to target regions. Instead, visual attention is always dispersed. To guide the visual attention grounding on the correct target, we propose ReconVLA, a reconstructive VLA model with an implicit grounding paradigm. Conditioned on the model's visual outputs, a diffusion transformer aims to reconstruct the gaze region of the image, which corresponds to the target manipulated objects. This process prompts the VLA model to learn fine-grained representations and accurately allocate visual attention, thus effectively leveraging task-specific visual information and conducting precise manipulation. Moreover, we curate a large-scale pretraining dataset comprising over 100k trajectories and 2 million data samples from open-source robotic datasets, further boosting the model's generalization in visual reconstruction. Extensive experiments in simulation and the real world demonstrate the superiority of our implicit grounding method, showcasing its capabilities of precise manipulation and generalization. Our project page is https://zionchow.github.io/ReconVLA/.
CEED-VLA: Consistency Vision-Language-Action Model with Early-Exit Decoding
Jun 16, 2025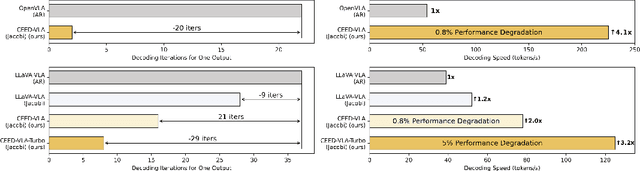

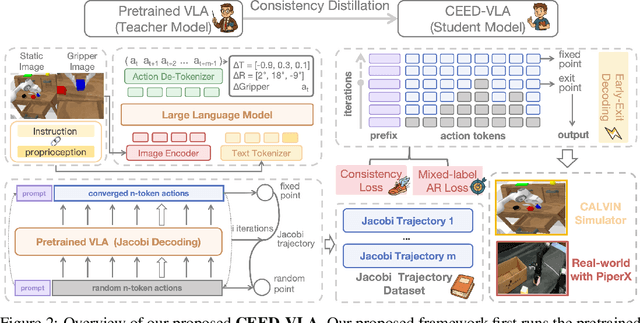
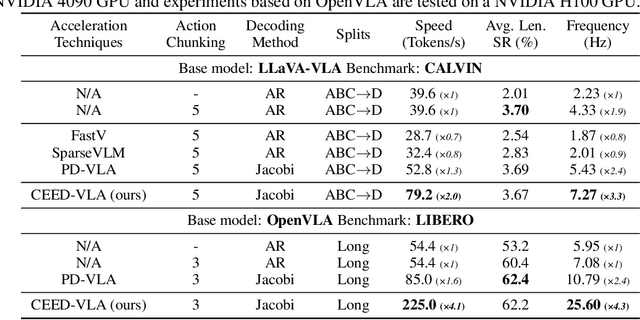
In recent years, Vision-Language-Action (VLA) models have become a vital research direction in robotics due to their impressive multimodal understanding and generalization capabilities. Despite the progress, their practical deployment is severely constrained by inference speed bottlenecks, particularly in high-frequency and dexterous manipulation tasks. While recent studies have explored Jacobi decoding as a more efficient alternative to traditional autoregressive decoding, its practical benefits are marginal due to the lengthy iterations. To address it, we introduce consistency distillation training to predict multiple correct action tokens in each iteration, thereby achieving acceleration. Besides, we design mixed-label supervision to mitigate the error accumulation during distillation. Although distillation brings acceptable speedup, we identify that certain inefficient iterations remain a critical bottleneck. To tackle this, we propose an early-exit decoding strategy that moderately relaxes convergence conditions, which further improves average inference efficiency. Experimental results show that the proposed method achieves more than 4 times inference acceleration across different baselines while maintaining high task success rates in both simulated and real-world robot tasks. These experiments validate that our approach provides an efficient and general paradigm for accelerating multimodal decision-making in robotics. Our project page is available at https://irpn-eai.github.io/CEED-VLA/.