 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRhd
Papers and Code
Detection and Mitigation of Hallucination in Large Reasoning Models: A Mechanistic Perspective
May 19, 2025Large Reasoning Models (LRMs) have shown impressive capabilities in multi-step reasoning tasks. However, alongside these successes, a more deceptive form of model error has emerged--Reasoning Hallucination--where logically coherent but factually incorrect reasoning traces lead to persuasive yet faulty conclusions. Unlike traditional hallucinations, these errors are embedded within structured reasoning, making them more difficult to detect and potentially more harmful. In this work, we investigate reasoning hallucinations from a mechanistic perspective. We propose the Reasoning Score, which quantifies the depth of reasoning by measuring the divergence between logits obtained from projecting late layers of LRMs to the vocabulary space, effectively distinguishing shallow pattern-matching from genuine deep reasoning. Using this score, we conduct an in-depth analysis on the ReTruthQA dataset and identify two key reasoning hallucination patterns: early-stage fluctuation in reasoning depth and incorrect backtracking to flawed prior steps. These insights motivate our Reasoning Hallucination Detection (RHD) framework, which achieves state-of-the-art performance across multiple domains. To mitigate reasoning hallucinations, we further introduce GRPO-R, an enhanced reinforcement learning algorithm that incorporates step-level deep reasoning rewards via potential-based shaping. Our theoretical analysis establishes stronger generalization guarantees, and experiments demonstrate improved reasoning quality and reduced hallucination rates.
Fourier Amplitude and Correlation Loss: Beyond Using L2 Loss for Skillful Precipitation Nowcasting
Oct 30, 2024



Deep learning approaches have been widely adopted for precipitation nowcasting in recent years. Previous studies mainly focus on proposing new model architectures to improve pixel-wise metrics. However, they frequently result in blurry predictions which provide limited utility to forecasting operations. In this work, we propose a new Fourier Amplitude and Correlation Loss (FACL) which consists of two novel loss terms: Fourier Amplitude Loss (FAL) and Fourier Correlation Loss (FCL). FAL regularizes the Fourier amplitude of the model prediction and FCL complements the missing phase information. The two loss terms work together to replace the traditional $L_2$ losses such as MSE and weighted MSE for the spatiotemporal prediction problem on signal-based data. Our method is generic, parameter-free and efficient. Extensive experiments using one synthetic dataset and three radar echo datasets demonstrate that our method improves perceptual metrics and meteorology skill scores, with a small trade-off to pixel-wise accuracy and structural similarity. Moreover, to improve the error margin in meteorological skill scores such as Critical Success Index (CSI) and Fractions Skill Score (FSS), we propose and adopt the Regional Histogram Divergence (RHD), a distance metric that considers the patch-wise similarity between signal-based imagery patterns with tolerance to local transforms. Code is available at https://github.com/argenycw/FACL
Mitigating Entity-Level Hallucination in Large Language Models
Jul 12, 2024



The emergence of Large Language Models (LLMs) has revolutionized how users access information, shifting from traditional search engines to direct question-and-answer interactions with LLMs. However, the widespread adoption of LLMs has revealed a significant challenge known as hallucination, wherein LLMs generate coherent yet factually inaccurate responses. This hallucination phenomenon has led to users' distrust in information retrieval systems based on LLMs. To tackle this challenge, this paper proposes Dynamic Retrieval Augmentation based on hallucination Detection (DRAD) as a novel method to detect and mitigate hallucinations in LLMs. DRAD improves upon traditional retrieval augmentation by dynamically adapting the retrieval process based on real-time hallucination detection. It features two main components: Real-time Hallucination Detection (RHD) for identifying potential hallucinations without external models, and Self-correction based on External Knowledge (SEK) for correcting these errors using external knowledge. Experiment results show that DRAD demonstrates superior performance in both detecting and mitigating hallucinations in LLMs. All of our code and data are open-sourced at https://github.com/oneal2000/EntityHallucination.
Image-free Domain Generalization via CLIP for 3D Hand Pose Estimation
Oct 30, 2022



RGB-based 3D hand pose estimation has been successful for decades thanks to large-scale databases and deep learning. However, the hand pose estimation network does not operate well for hand pose images whose characteristics are far different from the training data. This is caused by various factors such as illuminations, camera angles, diverse backgrounds in the input images, etc. Many existing methods tried to solve it by supplying additional large-scale unconstrained/target domain images to augment data space; however collecting such large-scale images takes a lot of labors. In this paper, we present a simple image-free domain generalization approach for the hand pose estimation framework that uses only source domain data. We try to manipulate the image features of the hand pose estimation network by adding the features from text descriptions using the CLIP (Contrastive Language-Image Pre-training) model. The manipulated image features are then exploited to train the hand pose estimation network via the contrastive learning framework. In experiments with STB and RHD datasets, our algorithm shows improved performance over the state-of-the-art domain generalization approaches.
Short Duration Traffic Flow Prediction Using Kalman Filtering
Aug 06, 2022The research examined predicting short-duration traffic flow counts with the Kalman filtering technique (KFT), a computational filtering method. Short-term traffic prediction is an important tool for operation in traffic management and transportation system. The short-term traffic flow value results can be used for travel time estimation by route guidance and advanced traveler information systems. Though the KFT has been tested for homogeneous traffic, its efficiency in heterogeneous traffic has yet to be investigated. The research was conducted on Mirpur Road in Dhaka, near the Sobhanbagh Mosque. The stream contains a heterogeneous mix of traffic, which implies uncertainty in prediction. The propositioned method is executed in Python using the pykalman library. The library is mostly used in advanced database modeling in the KFT framework, which addresses uncertainty. The data was derived from a three-hour traffic count of the vehicle. According to the Geometric Design Standards Manual published by Roads and Highways Division (RHD), Bangladesh in 2005, the heterogeneous traffic flow value was translated into an equivalent passenger car unit (PCU). The PCU obtained from five-minute aggregation was then utilized as the suggested model's dataset. The propositioned model has a mean absolute percent error (MAPE) of 14.62, indicating that the KFT model can forecast reasonably well. The root mean square percent error (RMSPE) shows an 18.73% accuracy which is less than 25%; hence the model is acceptable. The developed model has an R2 value of 0.879, indicating that it can explain 87.9 percent of the variability in the dataset. If the data were collected over a more extended period of time, the R2 value could be closer to 1.0.
End-to-end Weakly-supervised Multiple 3D Hand Mesh Reconstruction from Single Image
Apr 18, 2022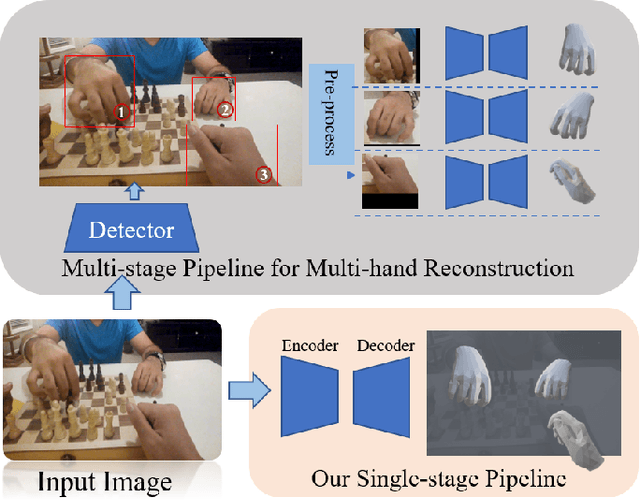
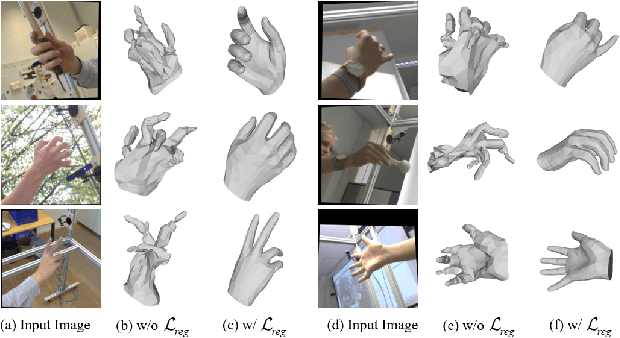

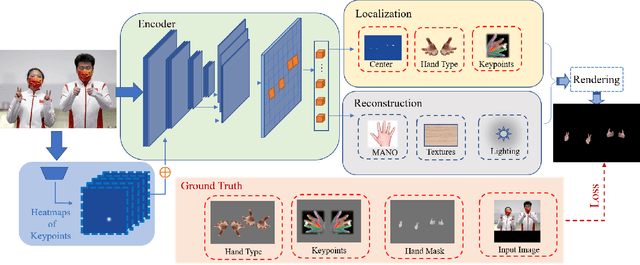
In this paper, we consider the challenging task of simultaneously locating and recovering multiple hands from single 2D image. Previous studies either focus on single hand reconstruction or solve this problem in a multi-stage way. Moreover, the conventional two-stage pipeline firstly detects hand areas, and then estimates 3D hand pose from each cropped patch. To reduce the computational redundancy in preprocessing and feature extraction, we propose a concise but efficient single-stage pipeline. Specifically, we design a multi-head auto-encoder structure for multi-hand reconstruction, where each head network shares the same feature map and outputs the hand center, pose and texture, respectively. Besides, we adopt a weakly-supervised scheme to alleviate the burden of expensive 3D real-world data annotations. To this end, we propose a series of losses optimized by a stage-wise training scheme, where a multi-hand dataset with 2D annotations is generated based on the publicly available single hand datasets. In order to further improve the accuracy of the weakly supervised model, we adopt several feature consistency constraints in both single and multiple hand settings. Specifically, the keypoints of each hand estimated from local features should be consistent with the re-projected points predicted from global features. Extensive experiments on public benchmarks including FreiHAND, HO3D, InterHand2.6M and RHD demonstrate that our method outperforms the state-of-the-art model-based methods in both weakly-supervised and fully-supervised manners.
MobRecon: Mobile-Friendly Hand Mesh Reconstruction from Monocular Image
Dec 06, 2021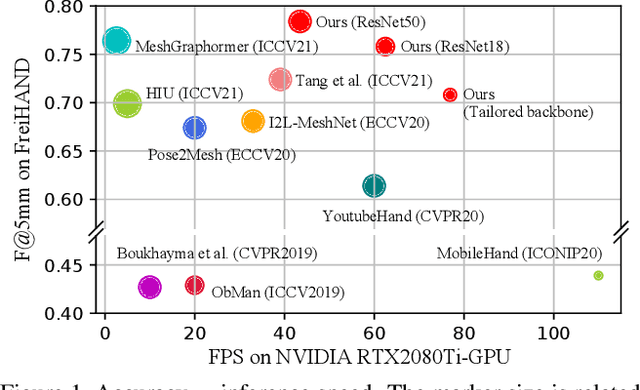
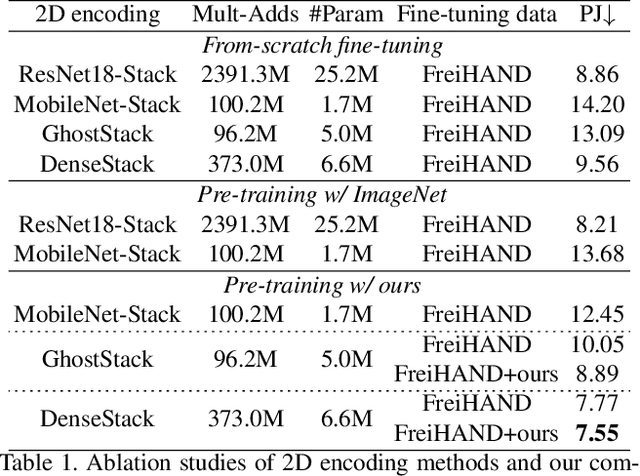


In this work, we propose a framework for single-view hand mesh reconstruction, which can simultaneously achieve high reconstruction accuracy, fast inference speed, and temporal coherence. Specifically, for 2D encoding, we propose lightweight yet effective stacked structures. Regarding 3D decoding, we provide an efficient graph operator, namely depth-separable spiral convolution. Moreover, we present a novel feature lifting module for bridging the gap between 2D and 3D representations. This module starts with a map-based position regression (MapReg) block to integrate the merits of both heatmap encoding and position regression paradigms to improve 2D accuracy and temporal coherence. Furthermore, MapReg is followed by pose pooling and pose-to-vertex lifting approaches, which transform 2D pose encodings to semantic features of 3D vertices. Overall, our hand reconstruction framework, called MobRecon, comprises affordable computational costs and miniature model size, which reaches a high inference speed of 83FPS on Apple A14 CPU. Extensive experiments on popular datasets such as FreiHAND, RHD, and HO3Dv2 demonstrate that our MobRecon achieves superior performance on reconstruction accuracy and temporal coherence. Our code is publicly available at https://github.com/SeanChenxy/HandMesh.
Camera-Space Hand Mesh Recovery via Semantic Aggregation and Adaptive 2D-1D Registration
Mar 31, 2021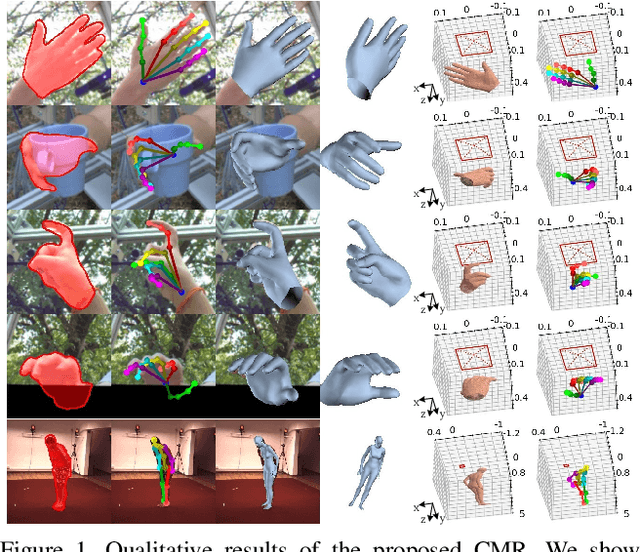
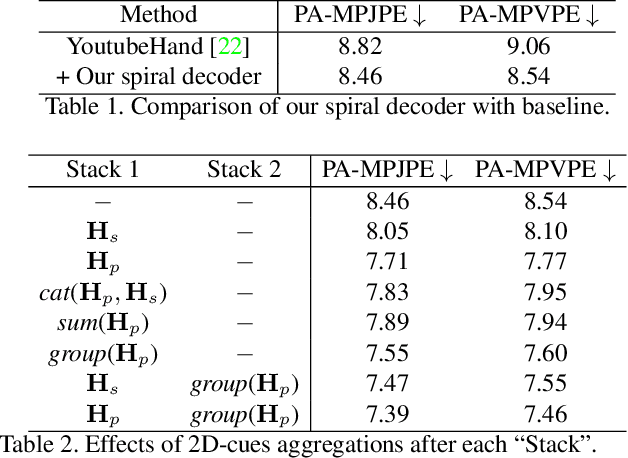
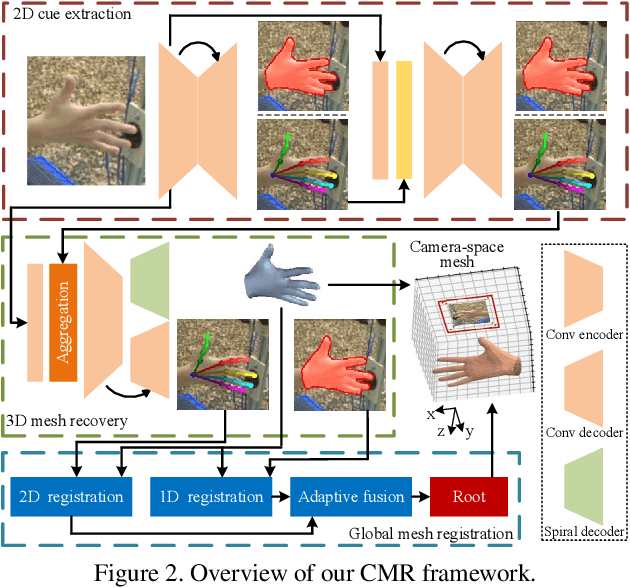
Recent years have witnessed significant progress in 3D hand mesh recovery. Nevertheless, because of the intrinsic 2D-to-3D ambiguity, recovering camera-space 3D information from a single RGB image remains challenging. To tackle this problem, we divide camera-space mesh recovery into two sub-tasks, i.e., root-relative mesh recovery and root recovery. First, joint landmarks and silhouette are extracted from a single input image to provide 2D cues for the 3D tasks. In the root-relative mesh recovery task, we exploit semantic relations among joints to generate a 3D mesh from the extracted 2D cues. Such generated 3D mesh coordinates are expressed relative to a root position, i.e., wrist of the hand. In the root recovery task, the root position is registered to the camera space by aligning the generated 3D mesh back to 2D cues, thereby completing cameraspace 3D mesh recovery. Our pipeline is novel in that (1) it explicitly makes use of known semantic relations among joints and (2) it exploits 1D projections of the silhouette and mesh to achieve robust registration. Extensive experiments on popular datasets such as FreiHAND, RHD, and Human3.6M demonstrate that our approach achieves stateof-the-art performance on both root-relative mesh recovery and root recovery. Our code is publicly available at https://github.com/SeanChenxy/HandMesh.
DGGAN: Depth-image Guided Generative Adversarial Networks for Disentangling RGB and Depth Images in 3D Hand Pose Estimation
Dec 06, 2020
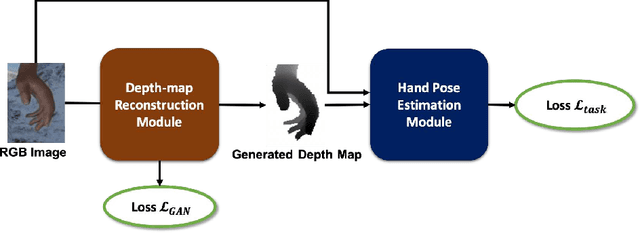
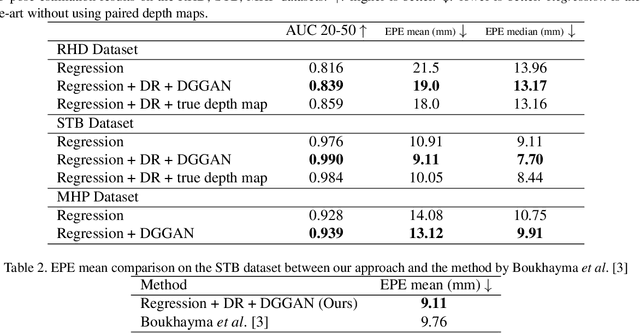
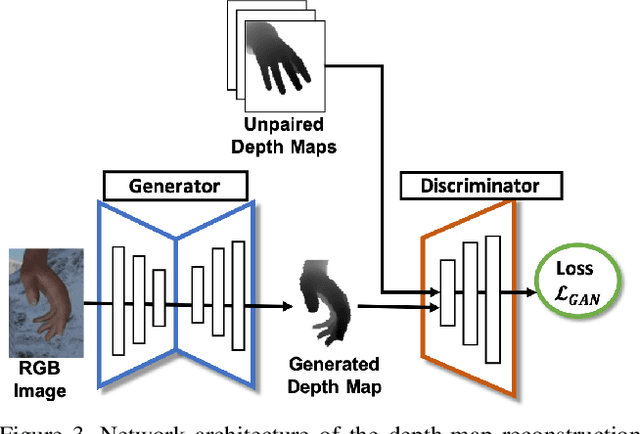
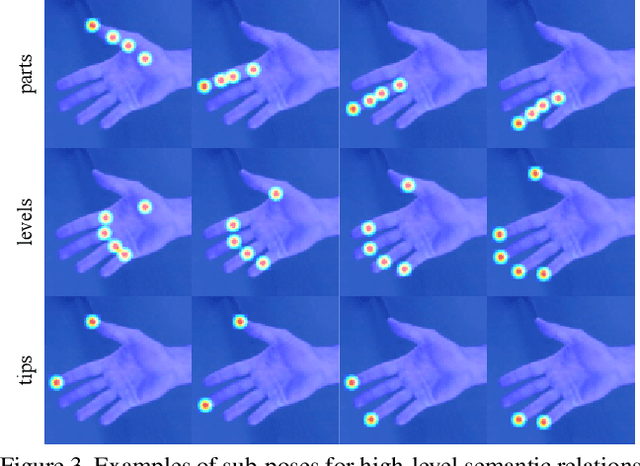
Estimating3D hand poses from RGB images is essentialto a wide range of potential applications, but is challengingowing to substantial ambiguity in the inference of depth in-formation from RGB images. State-of-the-art estimators ad-dress this problem by regularizing3D hand pose estimationmodels during training to enforce the consistency betweenthe predicted3D poses and the ground-truth depth maps.However, these estimators rely on both RGB images and thepaired depth maps during training. In this study, we proposea conditional generative adversarial network (GAN) model,called Depth-image Guided GAN (DGGAN), to generate re-alistic depth maps conditioned on the input RGB image, anduse the synthesized depth maps to regularize the3D handpose estimation model, therefore eliminating the need forground-truth depth maps. Experimental results on multiplebenchmark datasets show that the synthesized depth mapsproduced by DGGAN are quite effective in regularizing thepose estimation model, yielding new state-of-the-art resultsin estimation accuracy, notably reducing the mean3D end-point errors (EPE) by4.7%,16.5%, and6.8%on the RHD,STB and MHP datasets, respectively.
BiHand: Recovering Hand Mesh with Multi-stage Bisected Hourglass Networks
Aug 12, 20203D hand estimation has been a long-standing research topic in computer vision. A recent trend aims not only to estimate the 3D hand joint locations but also to recover the mesh model. However, achieving those goals from a single RGB image remains challenging. In this paper, we introduce an end-to-end learnable model, BiHand, which consists of three cascaded stages, namely 2D seeding stage, 3D lifting stage, and mesh generation stage. At the output of BiHand, the full hand mesh will be recovered using the joint rotations and shape parameters predicted from the network. Inside each stage, BiHand adopts a novel bisecting design which allows the networks to encapsulate two closely related information (e.g. 2D keypoints and silhouette in 2D seeding stage, 3D joints, and depth map in 3D lifting stage, joint rotations and shape parameters in the mesh generation stage) in a single forward pass. As the information represents different geometry or structure details, bisecting the data flow can facilitate optimization and increase robustness. For quantitative evaluation, we conduct experiments on two public benchmarks, namely the Rendered Hand Dataset (RHD) and the Stereo Hand Pose Tracking Benchmark (STB). Extensive experiments show that our model can achieve superior accuracy in comparison with state-of-the-art methods, and can produce appealing 3D hand meshes in several severe conditions.