 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Multi-Modal LLMs Reasoning via Difficulty-Aware Group Normalization
Feb 26, 2026Reinforcement Learning with Verifiable Rewards (RLVR) and Group Relative Policy Optimization (GRPO) have significantly advanced the reasoning capabilities of large language models. Extending these methods to multimodal settings, however, faces a critical challenge: the instability of std-based normalization, which is easily distorted by extreme samples with nearly positive or negative rewards. Unlike pure-text LLMs, multimodal models are particularly sensitive to such distortions, as both perceptual and reasoning errors influence their responses. To address this, we characterize each sample by its difficulty, defined through perceptual complexity (measured via visual entropy) and reasoning uncertainty (captured by model confidence). Building on this characterization, we propose difficulty-aware group normalization (Durian), which re-groups samples by difficulty levels and shares the std within each group. Our approach preserves GRPO's intra-group distinctions while eliminating sensitivity to extreme cases, yielding significant performance gains across multiple multimodal reasoning benchmarks.
A Novel Dual-pooling Attention Module for UAV Vehicle Re-identification
Jun 25, 2023Vehicle re-identification (Re-ID) involves identifying the same vehicle captured by other cameras, given a vehicle image. It plays a crucial role in the development of safe cities and smart cities. With the rapid growth and implementation of unmanned aerial vehicles (UAVs) technology, vehicle Re-ID in UAV aerial photography scenes has garnered significant attention from researchers. However, due to the high altitude of UAVs, the shooting angle of vehicle images sometimes approximates vertical, resulting in fewer local features for Re-ID. Therefore, this paper proposes a novel dual-pooling attention (DpA) module, which achieves the extraction and enhancement of locally important information about vehicles from both channel and spatial dimensions by constructing two branches of channel-pooling attention (CpA) and spatial-pooling attention (SpA), and employing multiple pooling operations to enhance the attention to fine-grained information of vehicles. Specifically, the CpA module operates between the channels of the feature map and splices features by combining four pooling operations so that vehicle regions containing discriminative information are given greater attention. The SpA module uses the same pooling operations strategy to identify discriminative representations and merge vehicle features in image regions in a weighted manner. The feature information of both dimensions is finally fused and trained jointly using label smoothing cross-entropy loss and hard mining triplet loss, thus solving the problem of missing detail information due to the high height of UAV shots. The proposed method's effectiveness is demonstrated through extensive experiments on the UAV-based vehicle datasets VeRi-UAV and VRU.
Bridging CLIP and StyleGAN through Latent Alignment for Image Editing
Oct 10, 2022

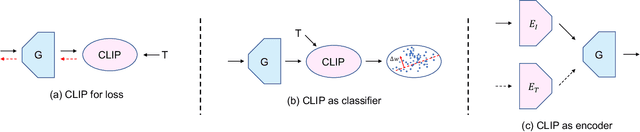
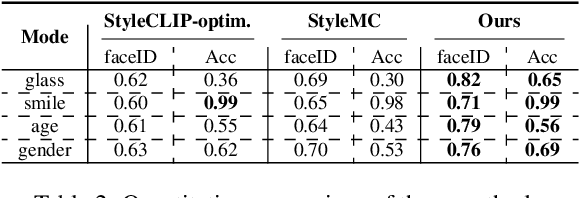
Text-driven image manipulation is developed since the vision-language model (CLIP) has been proposed. Previous work has adopted CLIP to design a text-image consistency-based objective to address this issue. However, these methods require either test-time optimization or image feature cluster analysis for single-mode manipulation direction. In this paper, we manage to achieve inference-time optimization-free diverse manipulation direction mining by bridging CLIP and StyleGAN through Latent Alignment (CSLA). More specifically, our efforts consist of three parts: 1) a data-free training strategy to train latent mappers to bridge the latent space of CLIP and StyleGAN; 2) for more precise mapping, temporal relative consistency is proposed to address the knowledge distribution bias problem among different latent spaces; 3) to refine the mapped latent in s space, adaptive style mixing is also proposed. With this mapping scheme, we can achieve GAN inversion, text-to-image generation and text-driven image manipulation. Qualitative and quantitative comparisons are made to demonstrate the effectiveness of our method.
Lower Difficulty and Better Robustness: A Bregman Divergence Perspective for Adversarial Training
Aug 26, 2022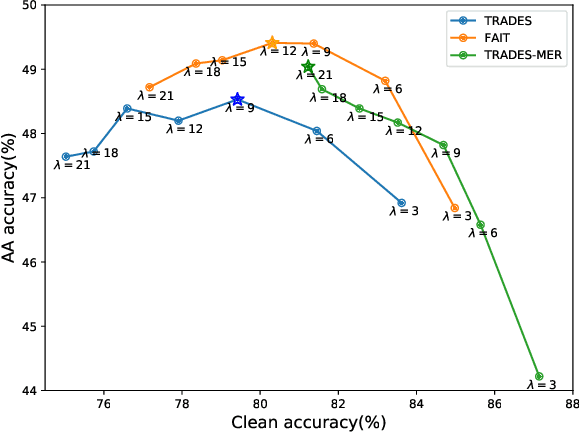
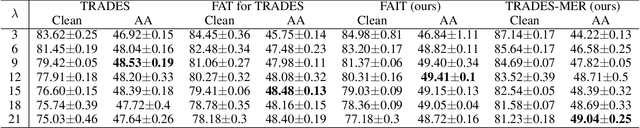
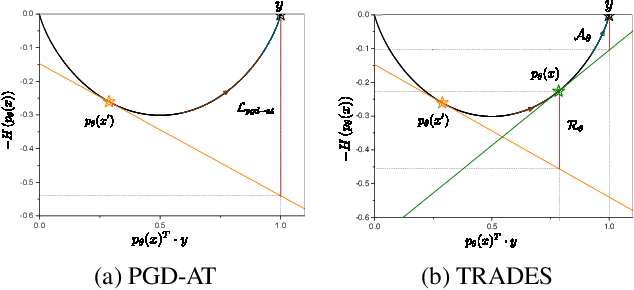
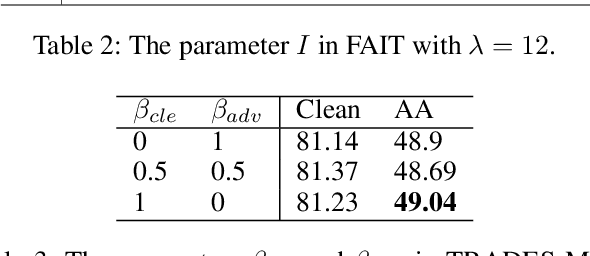
In this paper, we investigate on improving the adversarial robustness obtained in adversarial training (AT) via reducing the difficulty of optimization. To better study this problem, we build a novel Bregman divergence perspective for AT, in which AT can be viewed as the sliding process of the training data points on the negative entropy curve. Based on this perspective, we analyze the learning objectives of two typical AT methods, i.e., PGD-AT and TRADES, and we find that the optimization process of TRADES is easier than PGD-AT for that TRADES separates PGD-AT. In addition, we discuss the function of entropy in TRADES, and we find that models with high entropy can be better robustness learners. Inspired by the above findings, we propose two methods, i.e., FAIT and MER, which can both not only reduce the difficulty of optimization under the 10-step PGD adversaries, but also provide better robustness. Our work suggests that reducing the difficulty of optimization under the 10-step PGD adversaries is a promising approach for enhancing the adversarial robustness in AT.
MobRecon: Mobile-Friendly Hand Mesh Reconstruction from Monocular Image
Dec 06, 2021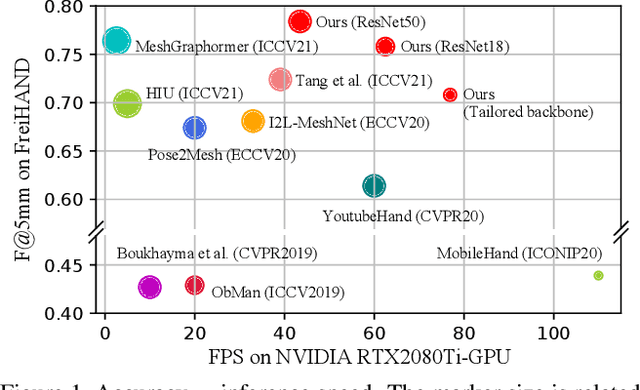
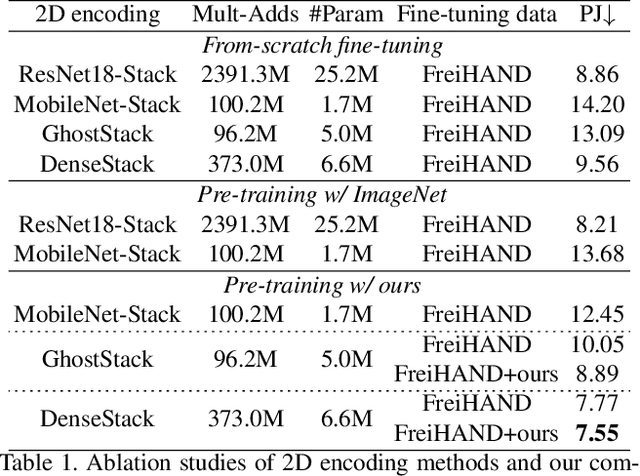


In this work, we propose a framework for single-view hand mesh reconstruction, which can simultaneously achieve high reconstruction accuracy, fast inference speed, and temporal coherence. Specifically, for 2D encoding, we propose lightweight yet effective stacked structures. Regarding 3D decoding, we provide an efficient graph operator, namely depth-separable spiral convolution. Moreover, we present a novel feature lifting module for bridging the gap between 2D and 3D representations. This module starts with a map-based position regression (MapReg) block to integrate the merits of both heatmap encoding and position regression paradigms to improve 2D accuracy and temporal coherence. Furthermore, MapReg is followed by pose pooling and pose-to-vertex lifting approaches, which transform 2D pose encodings to semantic features of 3D vertices. Overall, our hand reconstruction framework, called MobRecon, comprises affordable computational costs and miniature model size, which reaches a high inference speed of 83FPS on Apple A14 CPU. Extensive experiments on popular datasets such as FreiHAND, RHD, and HO3Dv2 demonstrate that our MobRecon achieves superior performance on reconstruction accuracy and temporal coherence. Our code is publicly available at https://github.com/SeanChenxy/HandMesh.
Improving Robustness for Pose Estimation via Stable Heatmap Regression
May 08, 2021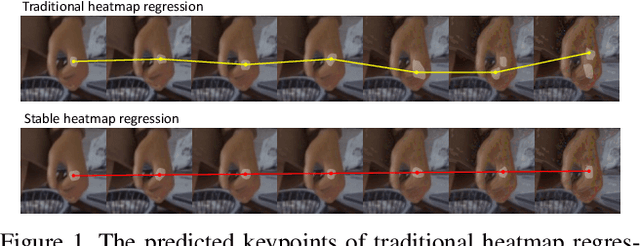

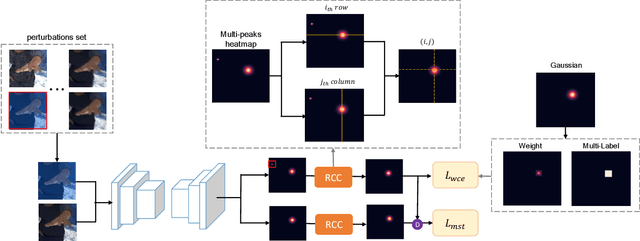

Deep learning methods have achieved excellent performance in pose estimation, but the lack of robustness causes the keypoints to change drastically between similar images. In view of this problem, a stable heatmap regression method is proposed to alleviate network vulnerability to small perturbations. We utilize the correlation between different rows and columns in a heatmap to alleviate the multi-peaks problem, and design a highly differentiated heatmap regression to make a keypoint discriminative from surrounding points. A maximum stability training loss is used to simplify the optimization difficulty when minimizing the prediction gap of two similar images. The proposed method achieves a significant advance in robustness over state-of-the-art approaches on two benchmark datasets and maintains high performance.
Camera-Space Hand Mesh Recovery via Semantic Aggregation and Adaptive 2D-1D Registration
Mar 31, 2021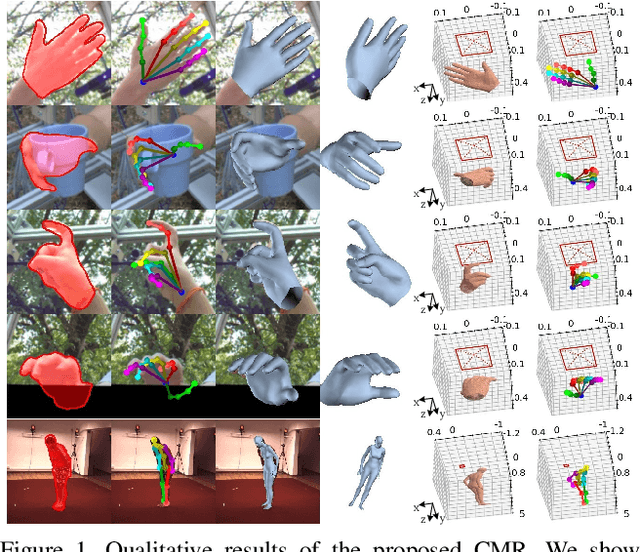
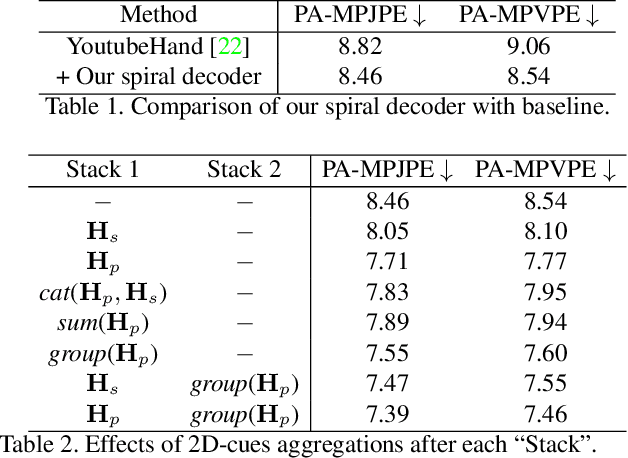
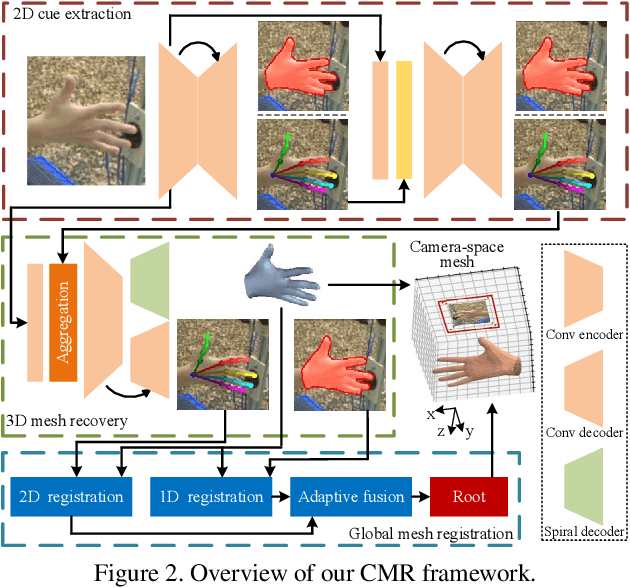
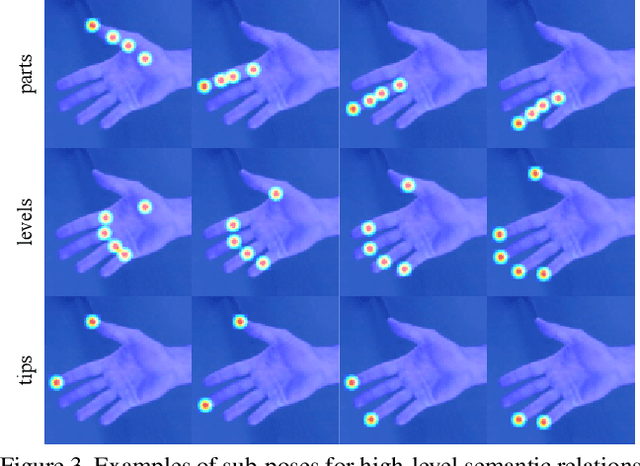
Recent years have witnessed significant progress in 3D hand mesh recovery. Nevertheless, because of the intrinsic 2D-to-3D ambiguity, recovering camera-space 3D information from a single RGB image remains challenging. To tackle this problem, we divide camera-space mesh recovery into two sub-tasks, i.e., root-relative mesh recovery and root recovery. First, joint landmarks and silhouette are extracted from a single input image to provide 2D cues for the 3D tasks. In the root-relative mesh recovery task, we exploit semantic relations among joints to generate a 3D mesh from the extracted 2D cues. Such generated 3D mesh coordinates are expressed relative to a root position, i.e., wrist of the hand. In the root recovery task, the root position is registered to the camera space by aligning the generated 3D mesh back to 2D cues, thereby completing cameraspace 3D mesh recovery. Our pipeline is novel in that (1) it explicitly makes use of known semantic relations among joints and (2) it exploits 1D projections of the silhouette and mesh to achieve robust registration. Extensive experiments on popular datasets such as FreiHAND, RHD, and Human3.6M demonstrate that our approach achieves stateof-the-art performance on both root-relative mesh recovery and root recovery. Our code is publicly available at https://github.com/SeanChenxy/HandMesh.
Improving Monocular Depth Estimation by Leveraging Structural Awareness and Complementary Datasets
Jul 22, 2020
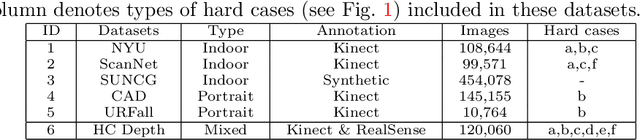
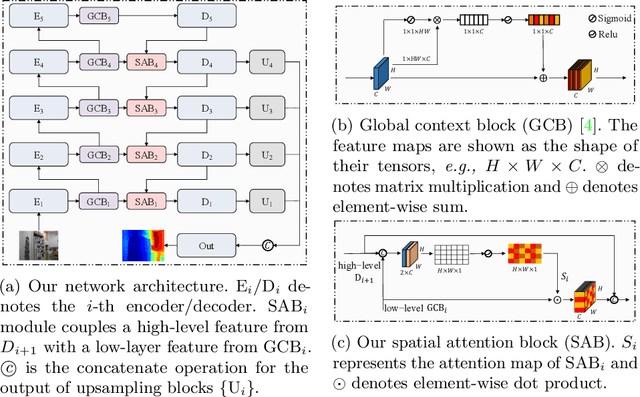
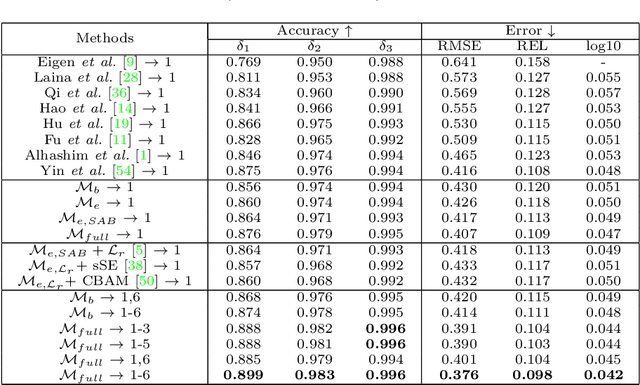
Monocular depth estimation plays a crucial role in 3D recognition and understanding. One key limitation of existing approaches lies in their lack of structural information exploitation, which leads to inaccurate spatial layout, discontinuous surface, and ambiguous boundaries. In this paper, we tackle this problem in three aspects. First, to exploit the spatial relationship of visual features, we propose a structure-aware neural network with spatial attention blocks. These blocks guide the network attention to global structures or local details across different feature layers. Second, we introduce a global focal relative loss for uniform point pairs to enhance spatial constraint in the prediction, and explicitly increase the penalty on errors in depth-wise discontinuous regions, which helps preserve the sharpness of estimation results. Finally, based on analysis of failure cases for prior methods, we collect a new Hard Case (HC) Depth dataset of challenging scenes, such as special lighting conditions, dynamic objects, and tilted camera angles. The new dataset is leveraged by an informed learning curriculum that mixes training examples incrementally to handle diverse data distributions. Experimental results show that our method outperforms state-of-the-art approaches by a large margin in terms of both prediction accuracy on NYUDv2 dataset and generalization performance on unseen datasets.