 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffectively leveraging Multi-modal Features for Movie Genre Classification
Mar 24, 2022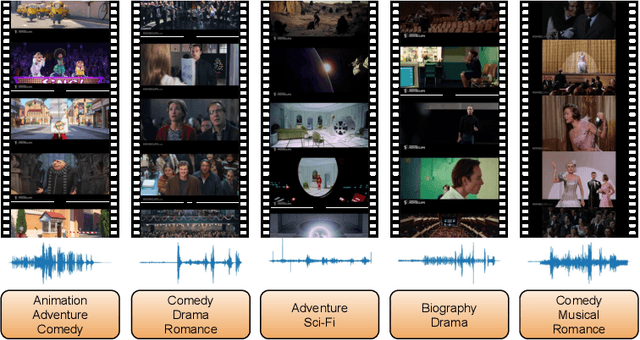
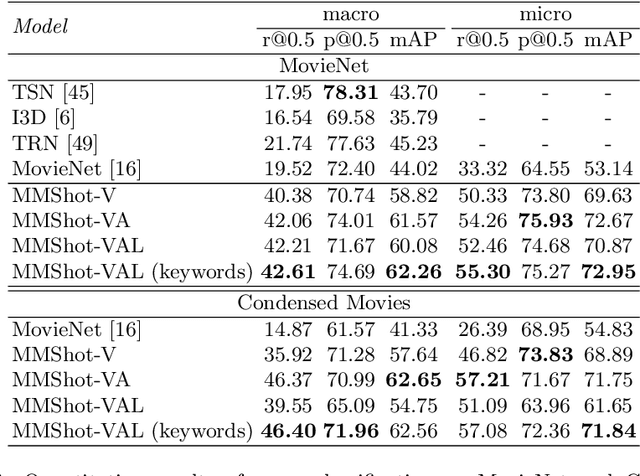
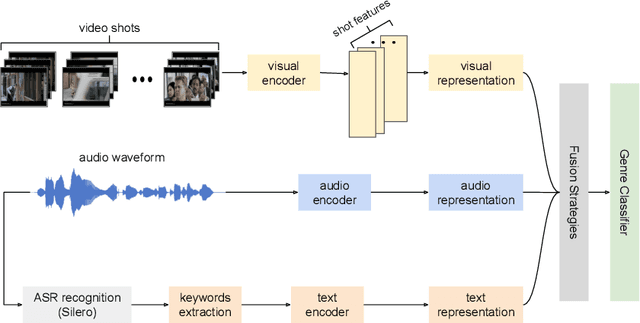

Movie genre classification has been widely studied in recent years due to its various applications in video editing, summarization, and recommendation. Prior work has typically addressed this task by predicting genres based solely on the visual content. As a result, predictions from these methods often perform poorly for genres such as documentary or musical, since non-visual modalities like audio or language play an important role in correctly classifying these genres. In addition, the analysis of long videos at frame level is always associated with high computational cost and makes the prediction less efficient. To address these two issues, we propose a Multi-Modal approach leveraging shot information, MMShot, to classify video genres in an efficient and effective way. We evaluate our method on MovieNet and Condensed Movies for genre classification, achieving 17% ~ 21% improvement on mean Average Precision (mAP) over the state-of-the-art. Extensive experiments are conducted to demonstrate the ability of MMShot for long video analysis and uncover the correlations between genres and multiple movie elements. We also demonstrate our approach's ability to generalize by evaluating the scene boundary detection task, achieving 1.1% improvement on Average Precision (AP) over the state-of-the-art.
Semantic Image Manipulation with Background-guided Internal Learning
Mar 24, 2022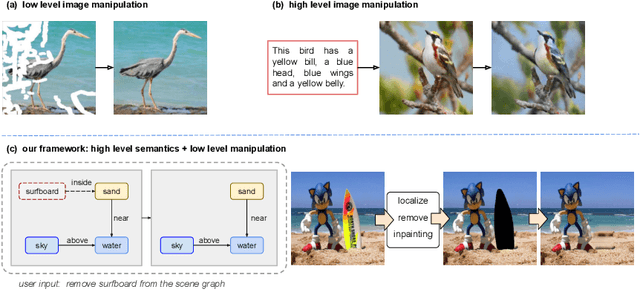
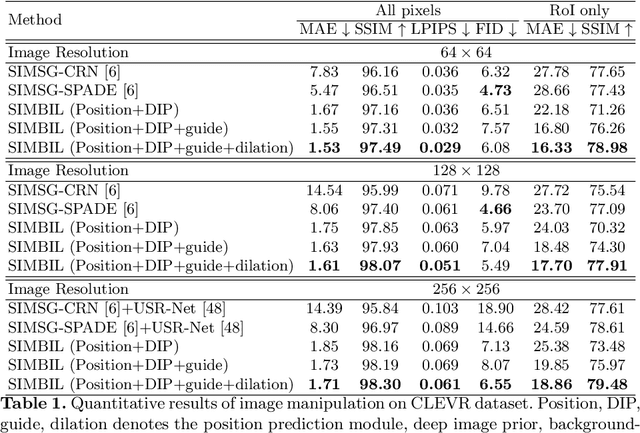
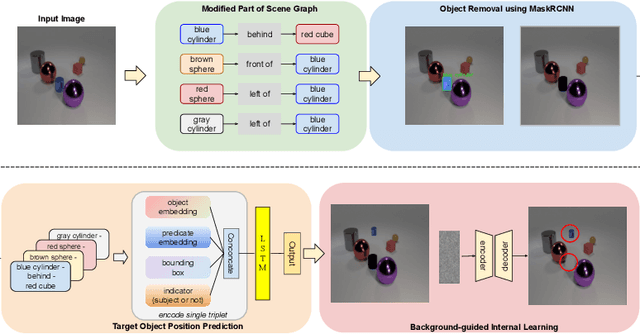

Image manipulation has attracted a lot of interest due to its wide range of applications. Prior work modifies images either from low-level manipulation, such as image inpainting or through manual edits via paintbrushes and scribbles, or from high-level manipulation, employing deep generative networks to output an image conditioned on high-level semantic input. In this study, we propose Semantic Image Manipulation with Background-guided Internal Learning (SIMBIL), which combines high-level and low-level manipulation. Specifically, users can edit an image at the semantic level by applying changes on a scene graph. Then our model manipulates the image at the pixel level according to the modified scene graph. There are two major advantages of our approach. First, high-level manipulation of scene graphs requires less manual effort from the user compared to manipulating raw image pixels. Second, our low-level internal learning approach is scalable to images of various sizes without reliance on external visual datasets for training. We outperform the state-of-the-art in a quantitative and qualitative evaluation on the CLEVR and Visual Genome datasets. Experiments show 8 points improvement on FID scores (CLEVR) and 27% improvement on user evaluation (Visual Genome), demonstrating the effectiveness of our approach.
ImageSubject: A Large-scale Dataset for Subject Detection
Jan 09, 2022
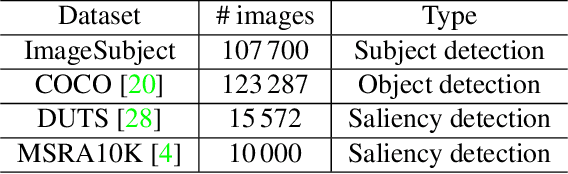

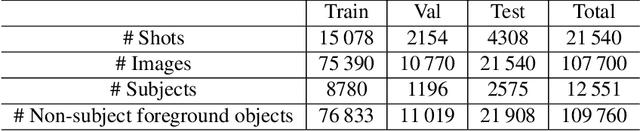
Main subjects usually exist in the images or videos, as they are the objects that the photographer wants to highlight. Human viewers can easily identify them but algorithms often confuse them with other objects. Detecting the main subjects is an important technique to help machines understand the content of images and videos. We present a new dataset with the goal of training models to understand the layout of the objects and the context of the image then to find the main subjects among them. This is achieved in three aspects. By gathering images from movie shots created by directors with professional shooting skills, we collect the dataset with strong diversity, specifically, it contains 107\,700 images from 21\,540 movie shots. We labeled them with the bounding box labels for two classes: subject and non-subject foreground object. We present a detailed analysis of the dataset and compare the task with saliency detection and object detection. ImageSubject is the first dataset that tries to localize the subject in an image that the photographer wants to highlight. Moreover, we find the transformer-based detection model offers the best result among other popular model architectures. Finally, we discuss the potential applications and conclude with the importance of the dataset.
Off-policy Reinforcement Learning with Optimistic Exploration and Distribution Correction
Oct 27, 2021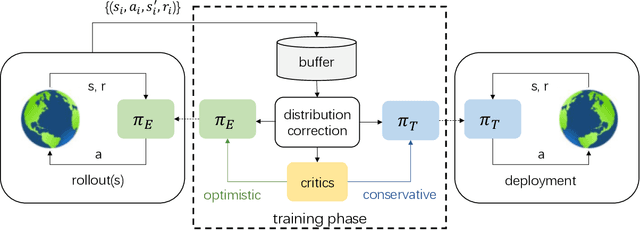
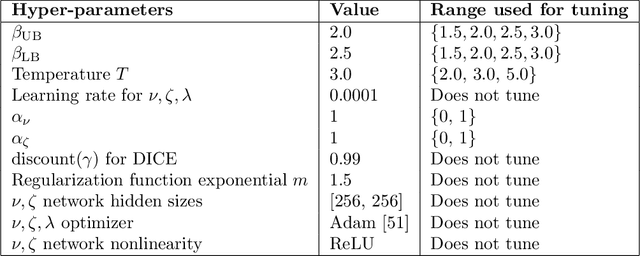

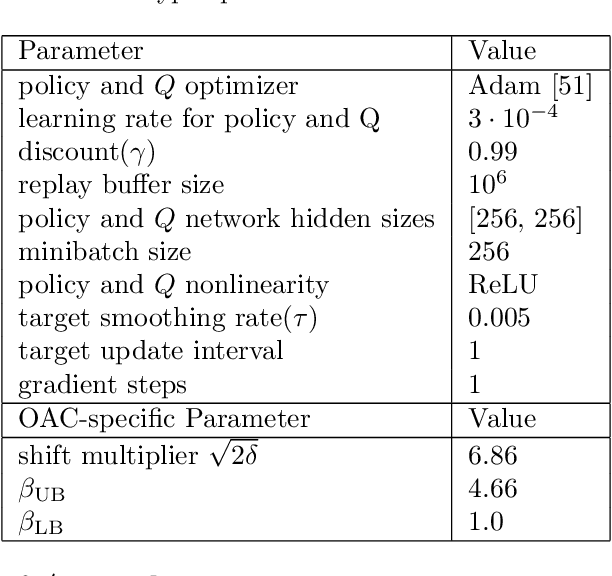
Improving sample efficiency of reinforcement learning algorithms requires effective exploration. Following the principle of $\textit{optimism in the face of uncertainty}$, we train a separate exploration policy to maximize an approximate upper confidence bound of the critics in an off-policy actor-critic framework. However, this introduces extra differences between the replay buffer and the target policy in terms of their stationary state-action distributions. To mitigate the off-policy-ness, we adapt the recently introduced DICE framework to learn a distribution correction ratio for off-policy actor-critic training. In particular, we correct the training distribution for both policies and critics. Empirically, we evaluate our proposed method in several challenging continuous control tasks and show superior performance compared to state-of-the-art methods. We also conduct extensive ablation studies to demonstrate the effectiveness and the rationality of the proposed method.
Fine-Grained Control of Artistic Styles in Image Generation
Oct 25, 2021

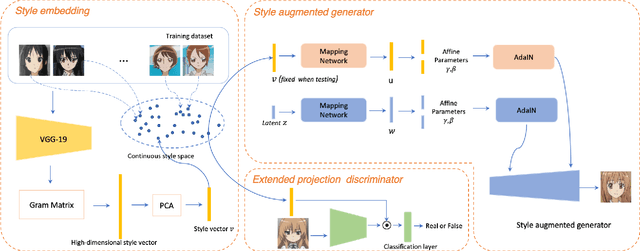

Recent advances in generative models and adversarial training have enabled artificially generating artworks in various artistic styles. It is highly desirable to gain more control over the generated style in practice. However, artistic styles are unlike object categories -- there are a continuous spectrum of styles distinguished by subtle differences. Few works have been explored to capture the continuous spectrum of styles and apply it to a style generation task. In this paper, we propose to achieve this by embedding original artwork examples into a continuous style space. The style vectors are fed to the generator and discriminator to achieve fine-grained control. Our method can be used with common generative adversarial networks (such as StyleGAN). Experiments show that our method not only precisely controls the fine-grained artistic style but also improves image quality over vanilla StyleGAN as measured by FID.
EVOQUER: Enhancing Temporal Grounding with Video-Pivoted BackQuery Generation
Sep 10, 2021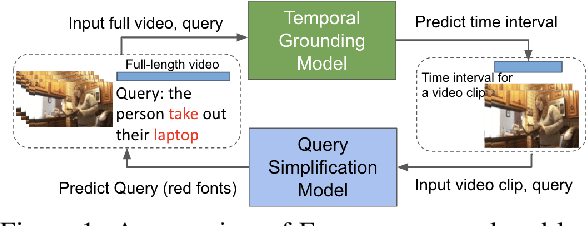
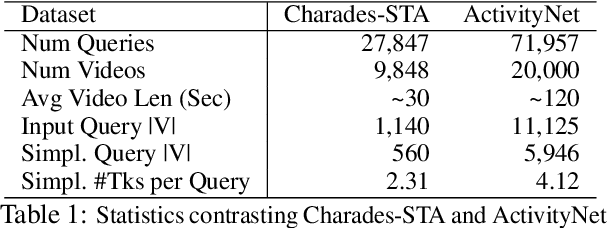
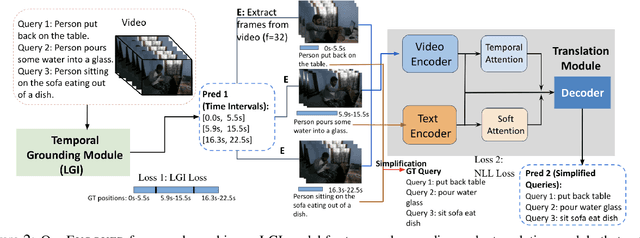
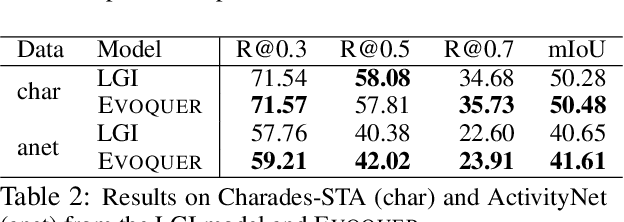
Temporal grounding aims to predict a time interval of a video clip corresponding to a natural language query input. In this work, we present EVOQUER, a temporal grounding framework incorporating an existing text-to-video grounding model and a video-assisted query generation network. Given a query and an untrimmed video, the temporal grounding model predicts the target interval, and the predicted video clip is fed into a video translation task by generating a simplified version of the input query. EVOQUER forms closed-loop learning by incorporating loss functions from both temporal grounding and query generation serving as feedback. Our experiments on two widely used datasets, Charades-STA and ActivityNet, show that EVOQUER achieves promising improvements by 1.05 and 1.31 at R@0.7. We also discuss how the query generation task could facilitate error analysis by explaining temporal grounding model behavior.
Transforming the Latent Space of StyleGAN for Real Face Editing
May 29, 2021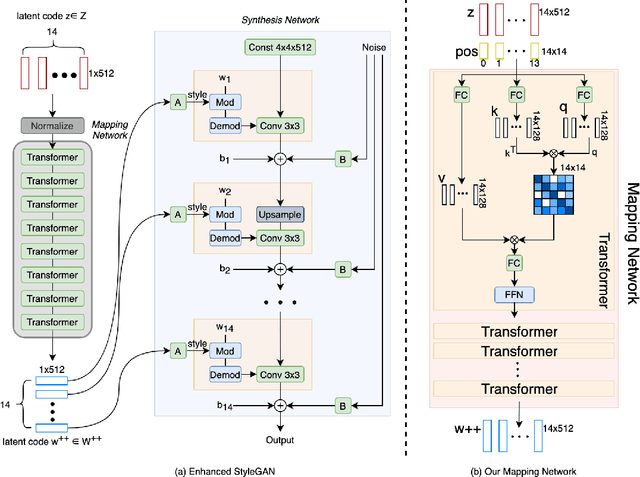

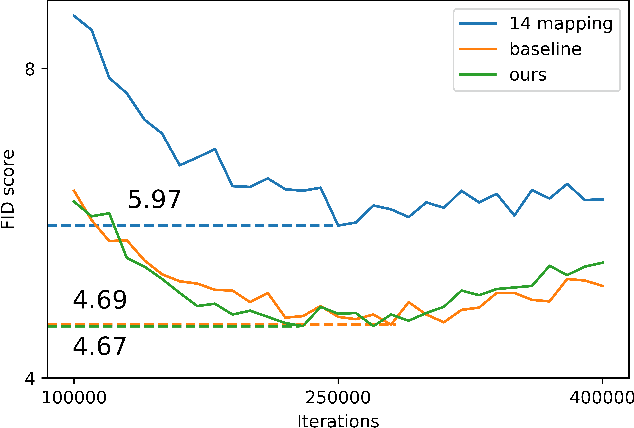

Despite recent advances in semantic manipulation using StyleGAN, semantic editing of real faces remains challenging. The gap between the $W$ space and the $W$+ space demands an undesirable trade-off between reconstruction quality and editing quality. To solve this problem, we propose to expand the latent space by replacing fully-connected layers in the StyleGAN's mapping network with attention-based transformers. This simple and effective technique integrates the aforementioned two spaces and transforms them into one new latent space called $W$++. Our modified StyleGAN maintains the state-of-the-art generation quality of the original StyleGAN with moderately better diversity. But more importantly, the proposed $W$++ space achieves superior performance in both reconstruction quality and editing quality. Despite these significant advantages, our $W$++ space supports existing inversion algorithms and editing methods with only negligible modifications thanks to its structural similarity with the $W/W$+ space. Extensive experiments on the FFHQ dataset prove that our proposed $W$++ space is evidently more preferable than the previous $W/W$+ space for real face editing. The code is publicly available for research purposes at https://github.com/AnonSubm2021/TransStyleGAN.
Camera-Space Hand Mesh Recovery via Semantic Aggregation and Adaptive 2D-1D Registration
Mar 31, 2021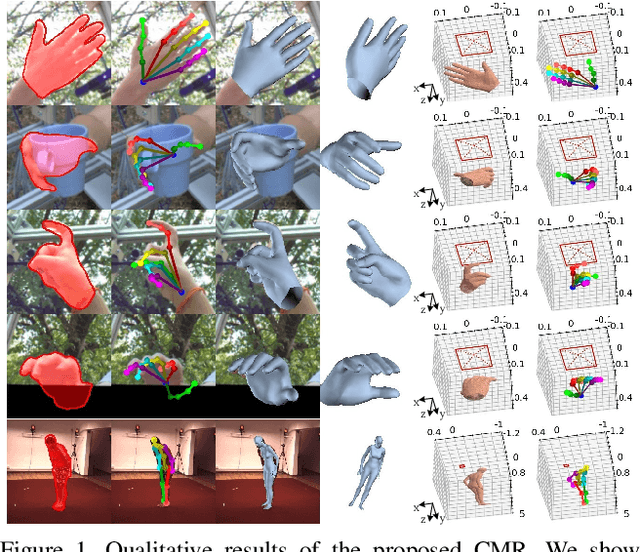
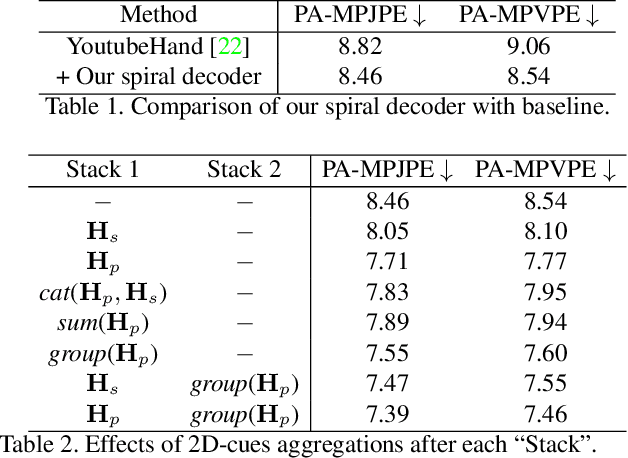
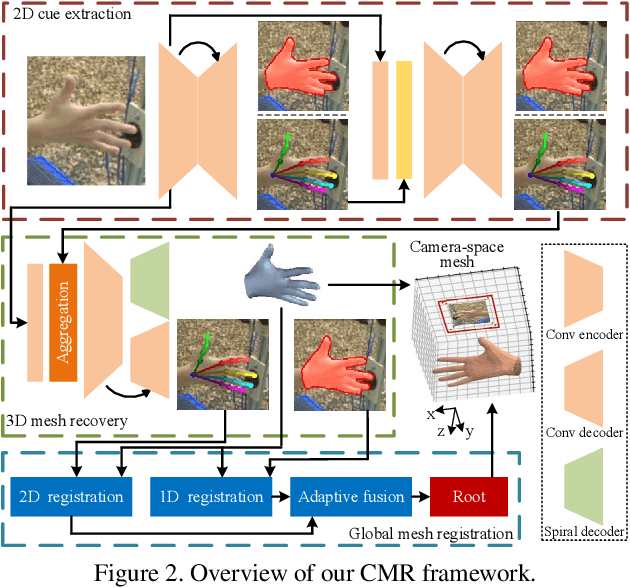
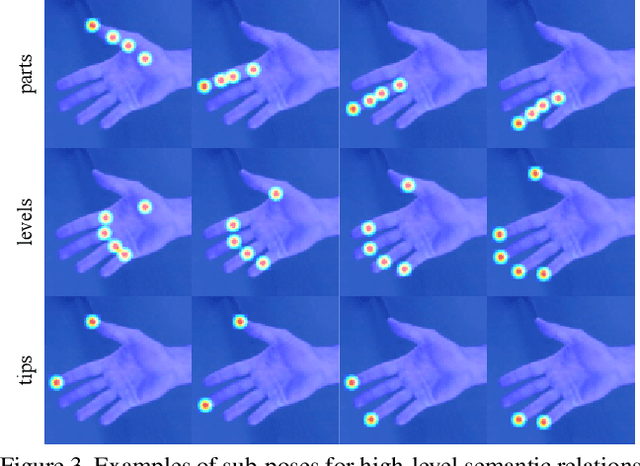
Recent years have witnessed significant progress in 3D hand mesh recovery. Nevertheless, because of the intrinsic 2D-to-3D ambiguity, recovering camera-space 3D information from a single RGB image remains challenging. To tackle this problem, we divide camera-space mesh recovery into two sub-tasks, i.e., root-relative mesh recovery and root recovery. First, joint landmarks and silhouette are extracted from a single input image to provide 2D cues for the 3D tasks. In the root-relative mesh recovery task, we exploit semantic relations among joints to generate a 3D mesh from the extracted 2D cues. Such generated 3D mesh coordinates are expressed relative to a root position, i.e., wrist of the hand. In the root recovery task, the root position is registered to the camera space by aligning the generated 3D mesh back to 2D cues, thereby completing cameraspace 3D mesh recovery. Our pipeline is novel in that (1) it explicitly makes use of known semantic relations among joints and (2) it exploits 1D projections of the silhouette and mesh to achieve robust registration. Extensive experiments on popular datasets such as FreiHAND, RHD, and Human3.6M demonstrate that our approach achieves stateof-the-art performance on both root-relative mesh recovery and root recovery. Our code is publicly available at https://github.com/SeanChenxy/HandMesh.
Improving Monocular Depth Estimation by Leveraging Structural Awareness and Complementary Datasets
Jul 22, 2020
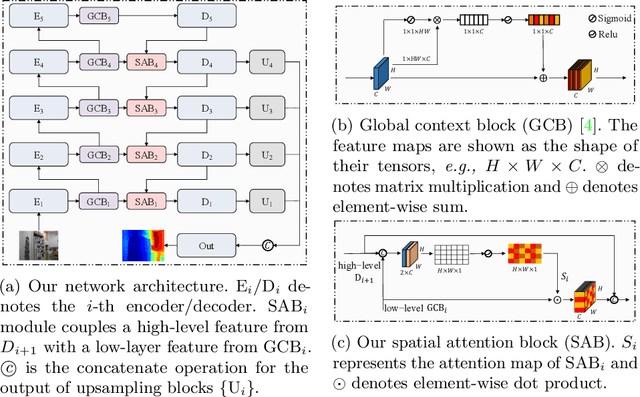
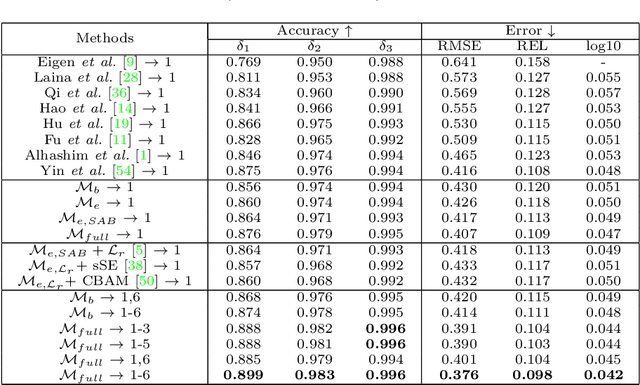
Monocular depth estimation plays a crucial role in 3D recognition and understanding. One key limitation of existing approaches lies in their lack of structural information exploitation, which leads to inaccurate spatial layout, discontinuous surface, and ambiguous boundaries. In this paper, we tackle this problem in three aspects. First, to exploit the spatial relationship of visual features, we propose a structure-aware neural network with spatial attention blocks. These blocks guide the network attention to global structures or local details across different feature layers. Second, we introduce a global focal relative loss for uniform point pairs to enhance spatial constraint in the prediction, and explicitly increase the penalty on errors in depth-wise discontinuous regions, which helps preserve the sharpness of estimation results. Finally, based on analysis of failure cases for prior methods, we collect a new Hard Case (HC) Depth dataset of challenging scenes, such as special lighting conditions, dynamic objects, and tilted camera angles. The new dataset is leveraged by an informed learning curriculum that mixes training examples incrementally to handle diverse data distributions. Experimental results show that our method outperforms state-of-the-art approaches by a large margin in terms of both prediction accuracy on NYUDv2 dataset and generalization performance on unseen datasets.
Understanding Why Neural Networks Generalize Well Through GSNR of Parameters
Feb 24, 2020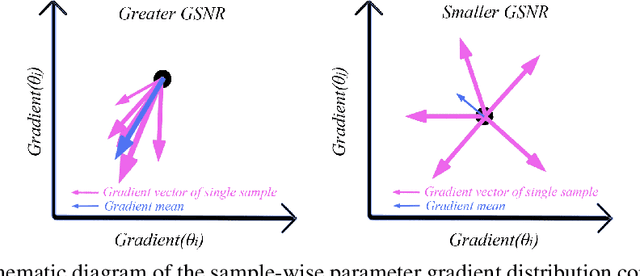
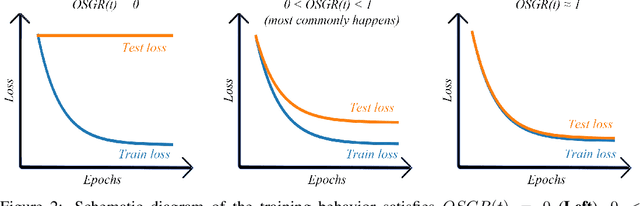

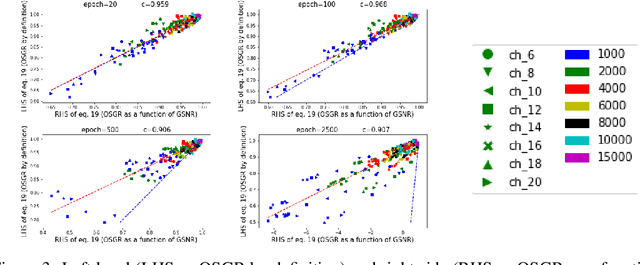
As deep neural networks (DNNs) achieve tremendous success across many application domains, researchers tried to explore in many aspects on why they generalize well. In this paper, we provide a novel perspective on these issues using the gradient signal to noise ratio (GSNR) of parameters during training process of DNNs. The GSNR of a parameter is defined as the ratio between its gradient's squared mean and variance, over the data distribution. Based on several approximations, we establish a quantitative relationship between model parameters' GSNR and the generalization gap. This relationship indicates that larger GSNR during training process leads to better generalization performance. Moreover, we show that, different from that of shallow models (e.g. logistic regression, support vector machines), the gradient descent optimization dynamics of DNNs naturally produces large GSNR during training, which is probably the key to DNNs' remarkable generalization ability.