 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePst900
Papers and Code
Spectral-Aware Global Fusion for RGB-Thermal Semantic Segmentation
May 21, 2025Semantic segmentation relying solely on RGB data often struggles in challenging conditions such as low illumination and obscured views, limiting its reliability in critical applications like autonomous driving. To address this, integrating additional thermal radiation data with RGB images demonstrates enhanced performance and robustness. However, how to effectively reconcile the modality discrepancies and fuse the RGB and thermal features remains a well-known challenge. In this work, we address this challenge from a novel spectral perspective. We observe that the multi-modal features can be categorized into two spectral components: low-frequency features that provide broad scene context, including color variations and smooth areas, and high-frequency features that capture modality-specific details such as edges and textures. Inspired by this, we propose the Spectral-aware Global Fusion Network (SGFNet) to effectively enhance and fuse the multi-modal features by explicitly modeling the interactions between the high-frequency, modality-specific features. Our experimental results demonstrate that SGFNet outperforms the state-of-the-art methods on the MFNet and PST900 datasets.
Segment Any RGB-Thermal Model with Language-aided Distillation
May 04, 2025The recent Segment Anything Model (SAM) demonstrates strong instance segmentation performance across various downstream tasks. However, SAM is trained solely on RGB data, limiting its direct applicability to RGB-thermal (RGB-T) semantic segmentation. Given that RGB-T provides a robust solution for scene understanding in adverse weather and lighting conditions, such as low light and overexposure, we propose a novel framework, SARTM, which customizes the powerful SAM for RGB-T semantic segmentation. Our key idea is to unleash the potential of SAM while introduce semantic understanding modules for RGB-T data pairs. Specifically, our framework first involves fine tuning the original SAM by adding extra LoRA layers, aiming at preserving SAM's strong generalization and segmentation capabilities for downstream tasks. Secondly, we introduce language information as guidance for training our SARTM. To address cross-modal inconsistencies, we introduce a Cross-Modal Knowledge Distillation(CMKD) module that effectively achieves modality adaptation while maintaining its generalization capabilities. This semantic module enables the minimization of modality gaps and alleviates semantic ambiguity, facilitating the combination of any modality under any visual conditions. Furthermore, we enhance the segmentation performance by adjusting the segmentation head of SAM and incorporating an auxiliary semantic segmentation head, which integrates multi-scale features for effective fusion. Extensive experiments are conducted across three multi-modal RGBT semantic segmentation benchmarks: MFNET, PST900, and FMB. Both quantitative and qualitative results consistently demonstrate that the proposed SARTM significantly outperforms state-of-the-art approaches across a variety of conditions.
Unveiling the Potential of Segment Anything Model 2 for RGB-Thermal Semantic Segmentation with Language Guidance
Mar 04, 2025The perception capability of robotic systems relies on the richness of the dataset. Although Segment Anything Model 2 (SAM2), trained on large datasets, demonstrates strong perception potential in perception tasks, its inherent training paradigm prevents it from being suitable for RGB-T tasks. To address these challenges, we propose SHIFNet, a novel SAM2-driven Hybrid Interaction Paradigm that unlocks the potential of SAM2 with linguistic guidance for efficient RGB-Thermal perception. Our framework consists of two key components: (1) Semantic-Aware Cross-modal Fusion (SACF) module that dynamically balances modality contributions through text-guided affinity learning, overcoming SAM2's inherent RGB bias; (2) Heterogeneous Prompting Decoder (HPD) that enhances global semantic information through a semantic enhancement module and then combined with category embeddings to amplify cross-modal semantic consistency. With 32.27M trainable parameters, SHIFNet achieves state-of-the-art segmentation performance on public benchmarks, reaching 89.8% on PST900 and 67.8% on FMB, respectively. The framework facilitates the adaptation of pre-trained large models to RGB-T segmentation tasks, effectively mitigating the high costs associated with data collection while endowing robotic systems with comprehensive perception capabilities. The source code will be made publicly available at https://github.com/iAsakiT3T/SHIFNet.
Context-Aware Interaction Network for RGB-T Semantic Segmentation
Jan 03, 2024



RGB-T semantic segmentation is a key technique for autonomous driving scenes understanding. For the existing RGB-T semantic segmentation methods, however, the effective exploration of the complementary relationship between different modalities is not implemented in the information interaction between multiple levels. To address such an issue, the Context-Aware Interaction Network (CAINet) is proposed for RGB-T semantic segmentation, which constructs interaction space to exploit auxiliary tasks and global context for explicitly guided learning. Specifically, we propose a Context-Aware Complementary Reasoning (CACR) module aimed at establishing the complementary relationship between multimodal features with the long-term context in both spatial and channel dimensions. Further, considering the importance of global contextual and detailed information, we propose the Global Context Modeling (GCM) module and Detail Aggregation (DA) module, and we introduce specific auxiliary supervision to explicitly guide the context interaction and refine the segmentation map. Extensive experiments on two benchmark datasets of MFNet and PST900 demonstrate that the proposed CAINet achieves state-of-the-art performance. The code is available at https://github.com/YingLv1106/CAINet.
Variational Probabilistic Fusion Network for RGB-T Semantic Segmentation
Jul 17, 2023RGB-T semantic segmentation has been widely adopted to handle hard scenes with poor lighting conditions by fusing different modality features of RGB and thermal images. Existing methods try to find an optimal fusion feature for segmentation, resulting in sensitivity to modality noise, class-imbalance, and modality bias. To overcome the problems, this paper proposes a novel Variational Probabilistic Fusion Network (VPFNet), which regards fusion features as random variables and obtains robust segmentation by averaging segmentation results under multiple samples of fusion features. The random samples generation of fusion features in VPFNet is realized by a novel Variational Feature Fusion Module (VFFM) designed based on variation attention. To further avoid class-imbalance and modality bias, we employ the weighted cross-entropy loss and introduce prior information of illumination and category to control the proposed VFFM. Experimental results on MFNet and PST900 datasets demonstrate that the proposed VPFNet can achieve state-of-the-art segmentation performance.
Residual Spatial Fusion Network for RGB-Thermal Semantic Segmentation
Jun 17, 2023Semantic segmentation plays an important role in widespread applications such as autonomous driving and robotic sensing. Traditional methods mostly use RGB images which are heavily affected by lighting conditions, \eg, darkness. Recent studies show thermal images are robust to the night scenario as a compensating modality for segmentation. However, existing works either simply fuse RGB-Thermal (RGB-T) images or adopt the encoder with the same structure for both the RGB stream and the thermal stream, which neglects the modality difference in segmentation under varying lighting conditions. Therefore, this work proposes a Residual Spatial Fusion Network (RSFNet) for RGB-T semantic segmentation. Specifically, we employ an asymmetric encoder to learn the compensating features of the RGB and the thermal images. To effectively fuse the dual-modality features, we generate the pseudo-labels by saliency detection to supervise the feature learning, and develop the Residual Spatial Fusion (RSF) module with structural re-parameterization to learn more promising features by spatially fusing the cross-modality features. RSF employs a hierarchical feature fusion to aggregate multi-level features, and applies the spatial weights with the residual connection to adaptively control the multi-spectral feature fusion by the confidence gate. Extensive experiments were carried out on two benchmarks, \ie, MFNet database and PST900 database. The results have shown the state-of-the-art segmentation performance of our method, which achieves a good balance between accuracy and speed.
SpiderMesh: Spatial-aware Demand-guided Recursive Meshing for RGB-T Semantic Segmentation
Mar 15, 2023For semantic segmentation in urban scene understanding, RGB cameras alone often fail to capture a clear holistic topology, especially in challenging lighting conditions. Thermal signal is an informative additional channel that can bring to light the contour and fine-grained texture of blurred regions in low-quality RGB image. Aiming at RGB-T (thermal) segmentation, existing methods either use simple passive channel/spatial-wise fusion for cross-modal interaction, or rely on heavy labeling of ambiguous boundaries for fine-grained supervision. We propose a Spatial-aware Demand-guided Recursive Meshing (SpiderMesh) framework that: 1) proactively compensates inadequate contextual semantics in optically-impaired regions via a demand-guided target masking algorithm; 2) refines multimodal semantic features with recursive meshing to improve pixel-level semantic analysis performance. We further introduce an asymmetric data augmentation technique M-CutOut, and enable semi-supervised learning to fully utilize RGB-T labels only sparsely available in practical use. Extensive experiments on MFNet and PST900 datasets demonstrate that SpiderMesh achieves new state-of-the-art performance on standard RGB-T segmentation benchmarks.
PST900: RGB-Thermal Calibration, Dataset and Segmentation Network
Sep 20, 2019

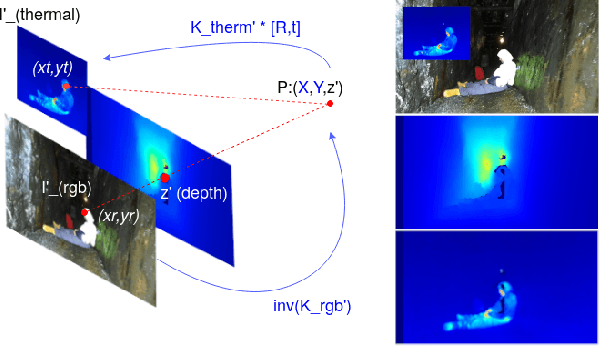

In this work we propose long wave infrared (LWIR) imagery as a viable supporting modality for semantic segmentation using learning-based techniques. We first address the problem of RGB-thermal camera calibration by proposing a passive calibration target and procedure that is both portable and easy to use. Second, we present PST900, a dataset of 894 synchronized and calibrated RGB and Thermal image pairs with per pixel human annotations across four distinct classes from the DARPA Subterranean Challenge. Lastly, we propose a CNN architecture for fast semantic segmentation that combines both RGB and Thermal imagery in a way that leverages RGB imagery independently. We compare our method against the state-of-the-art and show that our method outperforms them in our dataset.