 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePanoramic Multimodal Semantic Occupancy Prediction for Quadruped Robots
Mar 13, 2026Panoramic imagery provides holistic 360° visual coverage for perception in quadruped robots. However, existing occupancy prediction methods are mainly designed for wheeled autonomous driving and rely heavily on RGB cues, limiting their robustness in complex environments. To bridge this gap, (1) we present PanoMMOcc, the first real-world panoramic multimodal occupancy dataset for quadruped robots, featuring four sensing modalities across diverse scenes. (2) We propose a panoramic multimodal occupancy perception framework, VoxelHound, tailored for legged mobility and spherical imaging. Specifically, we design (i) a Vertical Jitter Compensation (VJC) module to mitigate severe viewpoint perturbations caused by body pitch and roll during mobility, enabling more consistent spatial reasoning, and (ii) an effective Multimodal Information Prompt Fusion (MIPF) module that jointly leverages panoramic visual cues and auxiliary modalities to enhance volumetric occupancy prediction. (3) We establish a benchmark based on PanoMMOcc and provide detailed data analysis to enable systematic evaluation of perception methods under challenging embodied scenarios. Extensive experiments demonstrate that VoxelHound achieves state-of-the-art performance on PanoMMOcc (+4.16%} in mIoU). The dataset and code will be publicly released to facilitate future research on panoramic multimodal 3D perception for embodied robotic systems at https://github.com/SXDR/PanoMMOcc, along with the calibration tools released at https://github.com/losehu/CameraLiDAR-Calib.
O3N: Omnidirectional Open-Vocabulary Occupancy Prediction
Mar 12, 2026Understanding and reconstructing the 3D world through omnidirectional perception is an inevitable trend in the development of autonomous agents and embodied intelligence. However, existing 3D occupancy prediction methods are constrained by limited perspective inputs and predefined training distribution, making them difficult to apply to embodied agents that require comprehensive and safe perception of scenes in open world exploration. To address this, we present O3N, the first purely visual, end-to-end Omnidirectional Open-vocabulary Occupancy predictioN framework. O3N embeds omnidirectional voxels in a polar-spiral topology via the Polar-spiral Mamba (PsM) module, enabling continuous spatial representation and long-range context modeling across 360°. The Occupancy Cost Aggregation (OCA) module introduces a principled mechanism for unifying geometric and semantic supervision within the voxel space, ensuring consistency between the reconstructed geometry and the underlying semantic structure. Moreover, Natural Modality Alignment (NMA) establishes a gradient-free alignment pathway that harmonizes visual features, voxel embeddings, and text semantics, forming a consistent "pixel-voxel-text" representation triad. Extensive experiments on multiple models demonstrate that our method not only achieves state-of-the-art performance on QuadOcc and Human360Occ benchmarks but also exhibits remarkable cross-scene generalization and semantic scalability, paving the way toward universal 3D world modeling. The source code will be made publicly available at https://github.com/MengfeiD/O3N.
Spherical-GOF: Geometry-Aware Panoramic Gaussian Opacity Fields for 3D Scene Reconstruction
Mar 09, 2026Omnidirectional images are increasingly used in robotics and vision due to their wide field of view. However, extending 3D Gaussian Splatting (3DGS) to panoramic camera models remains challenging, as existing formulations are designed for perspective projections and naive adaptations often introduce distortion and geometric inconsistencies. We present Spherical-GOF, an omnidirectional Gaussian rendering framework built upon Gaussian Opacity Fields (GOF). Unlike projection-based rasterization, Spherical-GOF performs GOF ray sampling directly on the unit sphere in spherical ray space, enabling consistent ray-Gaussian interactions for panoramic rendering. To make the spherical ray casting efficient and robust, we derive a conservative spherical bounding rule for fast ray-Gaussian culling and introduce a spherical filtering scheme that adapts Gaussian footprints to distortion-varying panoramic pixel sampling. Extensive experiments on standard panoramic benchmarks (OmniBlender and OmniPhotos) demonstrate competitive photometric quality and substantially improved geometric consistency. Compared with the strongest baseline, Spherical-GOF reduces depth reprojection error by 57% and improves cycle inlier ratio by 21%. Qualitative results show cleaner depth and more coherent normal maps, with strong robustness to global panorama rotations. We further validate generalization on OmniRob, a real-world robotic omnidirectional dataset introduced in this work, featuring UAV and quadruped platforms. The source code and the OmniRob dataset will be released at https://github.com/1170632760/Spherical-GOF.
Unveiling the Potential of Segment Anything Model 2 for RGB-Thermal Semantic Segmentation with Language Guidance
Mar 04, 2025The perception capability of robotic systems relies on the richness of the dataset. Although Segment Anything Model 2 (SAM2), trained on large datasets, demonstrates strong perception potential in perception tasks, its inherent training paradigm prevents it from being suitable for RGB-T tasks. To address these challenges, we propose SHIFNet, a novel SAM2-driven Hybrid Interaction Paradigm that unlocks the potential of SAM2 with linguistic guidance for efficient RGB-Thermal perception. Our framework consists of two key components: (1) Semantic-Aware Cross-modal Fusion (SACF) module that dynamically balances modality contributions through text-guided affinity learning, overcoming SAM2's inherent RGB bias; (2) Heterogeneous Prompting Decoder (HPD) that enhances global semantic information through a semantic enhancement module and then combined with category embeddings to amplify cross-modal semantic consistency. With 32.27M trainable parameters, SHIFNet achieves state-of-the-art segmentation performance on public benchmarks, reaching 89.8% on PST900 and 67.8% on FMB, respectively. The framework facilitates the adaptation of pre-trained large models to RGB-T segmentation tasks, effectively mitigating the high costs associated with data collection while endowing robotic systems with comprehensive perception capabilities. The source code will be made publicly available at https://github.com/iAsakiT3T/SHIFNet.
Sparse Multi-baseline SAR Cross-modal 3D Reconstruction of Vehicle Targets
Jun 06, 2024



Multi-baseline SAR 3D imaging faces significant challenges due to data sparsity. In recent years, deep learning techniques have achieved notable success in enhancing the quality of sparse SAR 3D imaging. However, previous work typically rely on full-aperture high-resolution radar images to supervise the training of deep neural networks (DNNs), utilizing only single-modal information from radar data. Consequently, imaging performance is limited, and acquiring full-aperture data for multi-baseline SAR is costly and sometimes impractical in real-world applications. In this paper, we propose a Cross-Modal Reconstruction Network (CMR-Net), which integrates differentiable render and cross-modal supervision with optical images to reconstruct highly sparse multi-baseline SAR 3D images of vehicle targets into visually structured and high-resolution images. We meticulously designed the network architecture and training strategies to enhance network generalization capability. Remarkably, CMR-Net, trained solely on simulated data, demonstrates high-resolution reconstruction capabilities on both publicly available simulation datasets and real measured datasets, outperforming traditional sparse reconstruction algorithms based on compressed sensing and other learning-based methods. Additionally, using optical images as supervision provides a cost-effective way to build training datasets, reducing the difficulty of method dissemination. Our work showcases the broad prospects of deep learning in multi-baseline SAR 3D imaging and offers a novel path for researching radar imaging based on cross-modal learning theory.
AxonCallosumEM Dataset: Axon Semantic Segmentation of Whole Corpus Callosum cross section from EM Images
Jul 05, 2023The electron microscope (EM) remains the predominant technique for elucidating intricate details of the animal nervous system at the nanometer scale. However, accurately reconstructing the complex morphology of axons and myelin sheaths poses a significant challenge. Furthermore, the absence of publicly available, large-scale EM datasets encompassing complete cross sections of the corpus callosum, with dense ground truth segmentation for axons and myelin sheaths, hinders the advancement and evaluation of holistic corpus callosum reconstructions. To surmount these obstacles, we introduce the AxonCallosumEM dataset, comprising a 1.83 times 5.76mm EM image captured from the corpus callosum of the Rett Syndrome (RTT) mouse model, which entail extensive axon bundles. We meticulously proofread over 600,000 patches at a resolution of 1024 times 1024, thus providing a comprehensive ground truth for myelinated axons and myelin sheaths. Additionally, we extensively annotated three distinct regions within the dataset for the purposes of training, testing, and validation. Utilizing this dataset, we develop a fine-tuning methodology that adapts Segment Anything Model (SAM) to EM images segmentation tasks, called EM-SAM, enabling outperforms other state-of-the-art methods. Furthermore, we present the evaluation results of EM-SAM as a baseline.
Towards Large-scale Single-shot Millimeter-wave Imaging for Low-cost Security Inspection
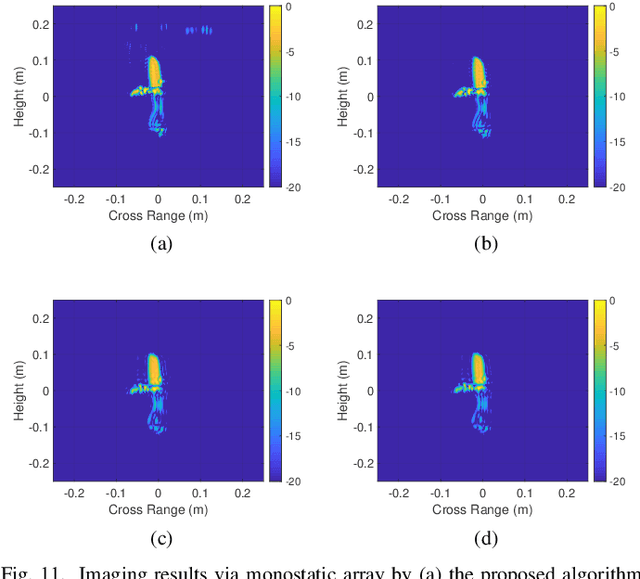
May 25, 2023Millimeter-wave (MMW) imaging is emerging as a promising technique for safe security inspection. It achieves a delicate balance between imaging resolution, penetrability and human safety, resulting in higher resolution compared to low-frequency microwave, stronger penetrability compared to visible light, and stronger safety compared to X ray. Despite of recent advance in the last decades, the high cost of requisite large-scale antenna array hinders widespread adoption of MMW imaging in practice. To tackle this challenge, we report a large-scale single-shot MMW imaging framework using sparse antenna array, achieving low-cost but high-fidelity security inspection under an interpretable learning scheme. We first collected extensive full-sampled MMW echoes to study the statistical ranking of each element in the large-scale array. These elements are then sampled based on the ranking, building the experimentally optimal sparse sampling strategy that reduces the cost of antenna array by up to one order of magnitude. Additionally, we derived an untrained interpretable learning scheme, which realizes robust and accurate image reconstruction from sparsely sampled echoes. Last, we developed a neural network for automatic object detection, and experimentally demonstrated successful detection of concealed centimeter-sized targets using 10% sparse array, whereas all the other contemporary approaches failed at the same sample sampling ratio. The performance of the reported technique presents higher than 50% superiority over the existing MMW imaging schemes on various metrics including precision, recall, and mAP50. With such strong detection ability and order-of-magnitude cost reduction, we anticipate that this technique provides a practical way for large-scale single-shot MMW imaging, and could advocate its further practical applications.
Compressive Sensing Based Sparse MIMO Array Optimization for Wideband Near-Field Imaging
Aug 09, 2022



In the area of near-field millimeter-wave imaging, the generalized sparse array synthesis (SAS) method is in great demand. The traditional methods usually employ the greedy algorithms, which may have the convergence problem. This paper proposes a convex optimization model for the multiple-input multiple-output (MIMO) array design based on the compressive sensing (CS) approach. We generate a block shaped reference pattern, to be used as an optimizing target. The pattern occupies the entire imaging area of interest in order to involve the effect of each pixel into the optimization model. In MIMO scenarios, we can fix the transmit subarray and synthesize the receive subarray, and vice versa, or doing the synthesis sequentially. The problems associated with focusing, sidelobes suppression, and grating lobes suppression of the synthesized array are examined in details. Numerical and experimental results demonstrate that the synthesized sparse array can offer better image qualities than the sparse arrays with equally spaced or randomly spaced antennas with the same number of antenna elements.
Near-Field Millimeter-Wave Imaging via Arrays in the Shape of Polyline
Sep 07, 2021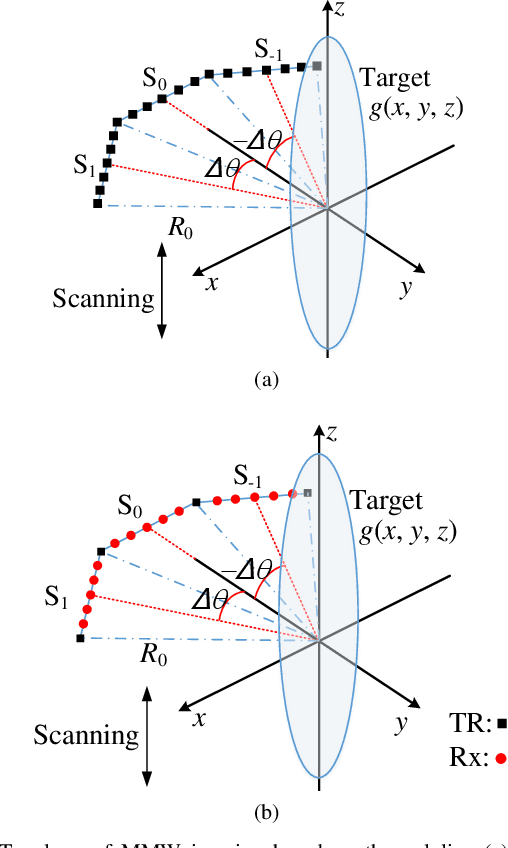

This paper proposes a polyline shaped array based system scheme, associated with mechanical scanning along the perpendicular direction of the array, for near-field millimeter-wave (MMW) imaging. Each section of the polyline is a chord of a circle with equal length. The polyline array, which can be realized as a monostatic array or a multistatic one, is capable of providing more observation angles than the linear or planar arrays. Further, we present the related three-dimensional (3-D) imaging algorithms based on a hybrid processing in the time domain and the spatial frequency domain. The nonuniform fast Fourier transform (NUFFT) is utilized to improve the computational efficiency. Simulations and experimental results are provided to demonstrate the efficacy of the proposed method in comparison with the back-projection (BP) algorithm.
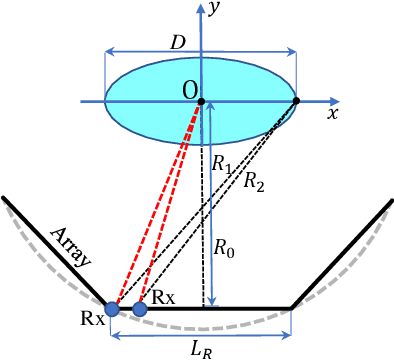
Near-Field Millimeter-Wave Imaging via Circular-Arc MIMO Arrays
Feb 26, 2021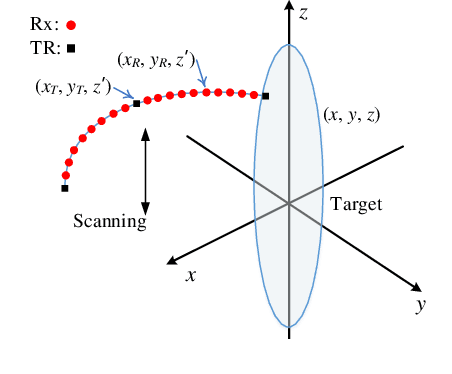
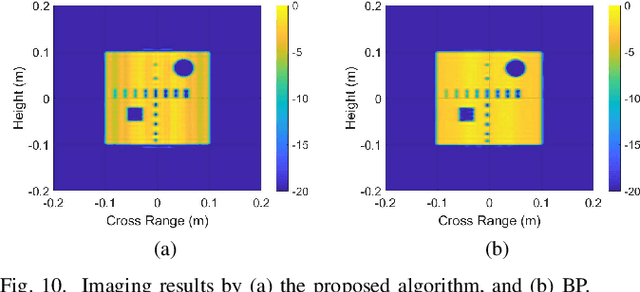
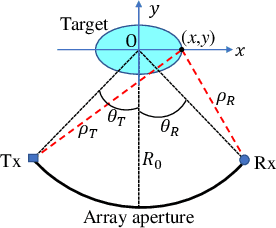
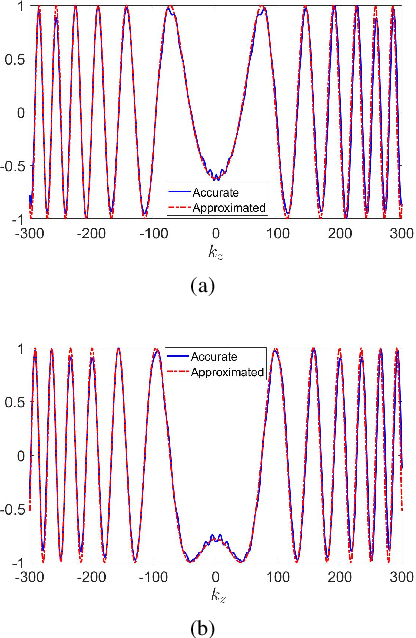
Millimeter-wave (MMW) imaging has a wide prospect in application of concealed weapons detection. We propose a circular-arc multiple-input multiple-output (MIMO) array scheme with uniformly spaced transmit and receive antennas along the horizontal-arc direction, while scanning along the vertical direction. The antenna beams of the circular-arc MIMO array can provide more uniform coverage of the imaging scene than those of the linear or planar MIMO arrays. Further, a near-field three-dimensional (3-D) imaging algorithm, based on the spatial frequency domain processing, is presented with analysis of sampling criteria and resolutions. Numerical simulations, as well as comparisons with the back-projection (BP) algorithm, are provided to show the efficacy of the proposed approach.