 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeONLY: One-Layer Intervention Sufficiently Mitigates Hallucinations in Large Vision-Language Models
Jul 01, 2025Recent Large Vision-Language Models (LVLMs) have introduced a new paradigm for understanding and reasoning about image input through textual responses. Although they have achieved remarkable performance across a range of multi-modal tasks, they face the persistent challenge of hallucination, which introduces practical weaknesses and raises concerns about their reliable deployment in real-world applications. Existing work has explored contrastive decoding approaches to mitigate this issue, where the output of the original LVLM is compared and contrasted with that of a perturbed version. However, these methods require two or more queries that slow down LVLM response generation, making them less suitable for real-time applications. To overcome this limitation, we propose ONLY, a training-free decoding approach that requires only a single query and a one-layer intervention during decoding, enabling efficient real-time deployment. Specifically, we enhance textual outputs by selectively amplifying crucial textual information using a text-to-visual entropy ratio for each token. Extensive experimental results demonstrate that our proposed ONLY consistently outperforms state-of-the-art methods across various benchmarks while requiring minimal implementation effort and computational cost. Code is available at https://github.com/zifuwan/ONLY.
InstructPart: Task-Oriented Part Segmentation with Instruction Reasoning
May 23, 2025Large multimodal foundation models, particularly in the domains of language and vision, have significantly advanced various tasks, including robotics, autonomous driving, information retrieval, and grounding. However, many of these models perceive objects as indivisible, overlooking the components that constitute them. Understanding these components and their associated affordances provides valuable insights into an object's functionality, which is fundamental for performing a wide range of tasks. In this work, we introduce a novel real-world benchmark, InstructPart, comprising hand-labeled part segmentation annotations and task-oriented instructions to evaluate the performance of current models in understanding and executing part-level tasks within everyday contexts. Through our experiments, we demonstrate that task-oriented part segmentation remains a challenging problem, even for state-of-the-art Vision-Language Models (VLMs). In addition to our benchmark, we introduce a simple baseline that achieves a twofold performance improvement through fine-tuning with our dataset. With our dataset and benchmark, we aim to facilitate research on task-oriented part segmentation and enhance the applicability of VLMs across various domains, including robotics, virtual reality, information retrieval, and other related fields. Project website: https://zifuwan.github.io/InstructPart/.
Spectral-Aware Global Fusion for RGB-Thermal Semantic Segmentation
May 21, 2025Semantic segmentation relying solely on RGB data often struggles in challenging conditions such as low illumination and obscured views, limiting its reliability in critical applications like autonomous driving. To address this, integrating additional thermal radiation data with RGB images demonstrates enhanced performance and robustness. However, how to effectively reconcile the modality discrepancies and fuse the RGB and thermal features remains a well-known challenge. In this work, we address this challenge from a novel spectral perspective. We observe that the multi-modal features can be categorized into two spectral components: low-frequency features that provide broad scene context, including color variations and smooth areas, and high-frequency features that capture modality-specific details such as edges and textures. Inspired by this, we propose the Spectral-aware Global Fusion Network (SGFNet) to effectively enhance and fuse the multi-modal features by explicitly modeling the interactions between the high-frequency, modality-specific features. Our experimental results demonstrate that SGFNet outperforms the state-of-the-art methods on the MFNet and PST900 datasets.
Self-Correcting Decoding with Generative Feedback for Mitigating Hallucinations in Large Vision-Language Models
Feb 10, 2025While recent Large Vision-Language Models (LVLMs) have shown remarkable performance in multi-modal tasks, they are prone to generating hallucinatory text responses that do not align with the given visual input, which restricts their practical applicability in real-world scenarios. In this work, inspired by the observation that the text-to-image generation process is the inverse of image-conditioned response generation in LVLMs, we explore the potential of leveraging text-to-image generative models to assist in mitigating hallucinations in LVLMs. We discover that generative models can offer valuable self-feedback for mitigating hallucinations at both the response and token levels. Building on this insight, we introduce self-correcting Decoding with Generative Feedback (DeGF), a novel training-free algorithm that incorporates feedback from text-to-image generative models into the decoding process to effectively mitigate hallucinations in LVLMs. Specifically, DeGF generates an image from the initial response produced by LVLMs, which acts as an auxiliary visual reference and provides self-feedback to verify and correct the initial response through complementary or contrastive decoding. Extensive experimental results validate the effectiveness of our approach in mitigating diverse types of hallucinations, consistently surpassing state-of-the-art methods across six benchmarks. Code is available at https://github.com/zhangce01/DeGF.
MAS-SAM: Segment Any Marine Animal with Aggregated Features
Apr 24, 2024



Recently, Segment Anything Model (SAM) shows exceptional performance in generating high-quality object masks and achieving zero-shot image segmentation. However, as a versatile vision model, SAM is primarily trained with large-scale natural light images. In underwater scenes, it exhibits substantial performance degradation due to the light scattering and absorption. Meanwhile, the simplicity of the SAM's decoder might lead to the loss of fine-grained object details. To address the above issues, we propose a novel feature learning framework named MAS-SAM for marine animal segmentation, which involves integrating effective adapters into the SAM's encoder and constructing a pyramidal decoder. More specifically, we first build a new SAM's encoder with effective adapters for underwater scenes. Then, we introduce a Hypermap Extraction Module (HEM) to generate multi-scale features for a comprehensive guidance. Finally, we propose a Progressive Prediction Decoder (PPD) to aggregate the multi-scale features and predict the final segmentation results. When grafting with the Fusion Attention Module (FAM), our method enables to extract richer marine information from global contextual cues to fine-grained local details. Extensive experiments on four public MAS datasets demonstrate that our MAS-SAM can obtain better results than other typical segmentation methods. The source code is available at https://github.com/Drchip61/MAS-SAM.
Sigma: Siamese Mamba Network for Multi-Modal Semantic Segmentation
Apr 05, 2024Multi-modal semantic segmentation significantly enhances AI agents' perception and scene understanding, especially under adverse conditions like low-light or overexposed environments. Leveraging additional modalities (X-modality) like thermal and depth alongside traditional RGB provides complementary information, enabling more robust and reliable segmentation. In this work, we introduce Sigma, a Siamese Mamba network for multi-modal semantic segmentation, utilizing the Selective Structured State Space Model, Mamba. Unlike conventional methods that rely on CNNs, with their limited local receptive fields, or Vision Transformers (ViTs), which offer global receptive fields at the cost of quadratic complexity, our model achieves global receptive fields coverage with linear complexity. By employing a Siamese encoder and innovating a Mamba fusion mechanism, we effectively select essential information from different modalities. A decoder is then developed to enhance the channel-wise modeling ability of the model. Our method, Sigma, is rigorously evaluated on both RGB-Thermal and RGB-Depth segmentation tasks, demonstrating its superiority and marking the first successful application of State Space Models (SSMs) in multi-modal perception tasks. Code is available at https://github.com/zifuwan/Sigma.
2023 Low-Power Computer Vision Challenge (LPCVC) Summary
Mar 11, 2024



This article describes the 2023 IEEE Low-Power Computer Vision Challenge (LPCVC). Since 2015, LPCVC has been an international competition devoted to tackling the challenge of computer vision (CV) on edge devices. Most CV researchers focus on improving accuracy, at the expense of ever-growing sizes of machine models. LPCVC balances accuracy with resource requirements. Winners must achieve high accuracy with short execution time when their CV solutions run on an embedded device, such as Raspberry PI or Nvidia Jetson Nano. The vision problem for 2023 LPCVC is segmentation of images acquired by Unmanned Aerial Vehicles (UAVs, also called drones) after disasters. The 2023 LPCVC attracted 60 international teams that submitted 676 solutions during the submission window of one month. This article explains the setup of the competition and highlights the winners' methods that improve accuracy and shorten execution time.
TransY-Net:Learning Fully Transformer Networks for Change Detection of Remote Sensing Images
Oct 22, 2023In the remote sensing field, Change Detection (CD) aims to identify and localize the changed regions from dual-phase images over the same places. Recently, it has achieved great progress with the advances of deep learning. However, current methods generally deliver incomplete CD regions and irregular CD boundaries due to the limited representation ability of the extracted visual features. To relieve these issues, in this work we propose a novel Transformer-based learning framework named TransY-Net for remote sensing image CD, which improves the feature extraction from a global view and combines multi-level visual features in a pyramid manner. More specifically, the proposed framework first utilizes the advantages of Transformers in long-range dependency modeling. It can help to learn more discriminative global-level features and obtain complete CD regions. Then, we introduce a novel pyramid structure to aggregate multi-level visual features from Transformers for feature enhancement. The pyramid structure grafted with a Progressive Attention Module (PAM) can improve the feature representation ability with additional inter-dependencies through spatial and channel attentions. Finally, to better train the whole framework, we utilize the deeply-supervised learning with multiple boundary-aware loss functions. Extensive experiments demonstrate that our proposed method achieves a new state-of-the-art performance on four optical and two SAR image CD benchmarks. The source code is released at https://github.com/Drchip61/TransYNet.
Fully Transformer Network for Change Detection of Remote Sensing Images
Oct 03, 2022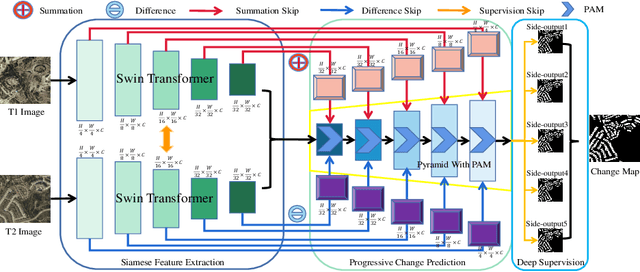
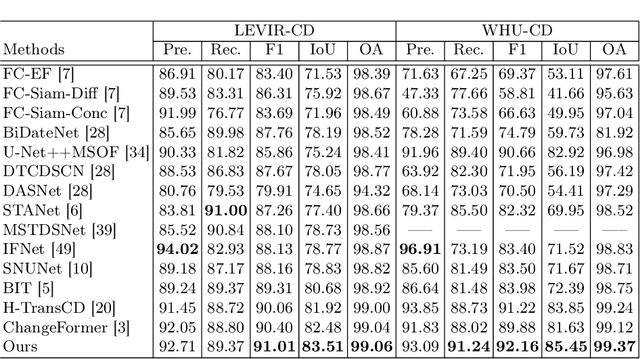
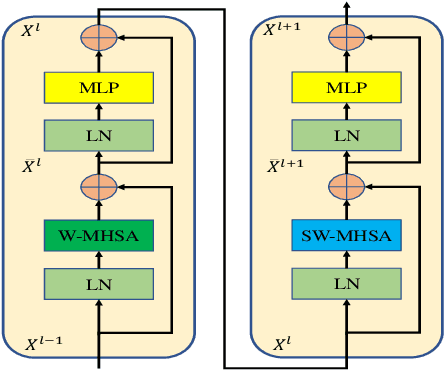
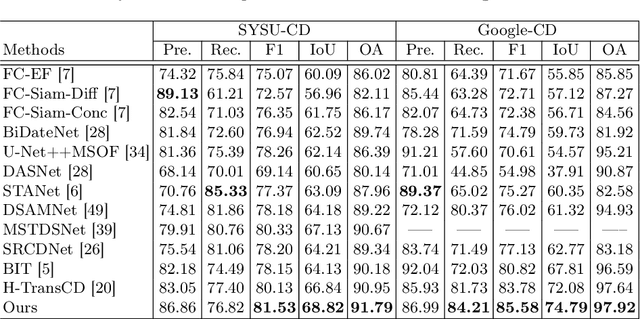
Recently, change detection (CD) of remote sensing images have achieved great progress with the advances of deep learning. However, current methods generally deliver incomplete CD regions and irregular CD boundaries due to the limited representation ability of the extracted visual features. To relieve these issues, in this work we propose a novel learning framework named Fully Transformer Network (FTN) for remote sensing image CD, which improves the feature extraction from a global view and combines multi-level visual features in a pyramid manner. More specifically, the proposed framework first utilizes the advantages of Transformers in long-range dependency modeling. It can help to learn more discriminative global-level features and obtain complete CD regions. Then, we introduce a pyramid structure to aggregate multi-level visual features from Transformers for feature enhancement. The pyramid structure grafted with a Progressive Attention Module (PAM) can improve the feature representation ability with additional interdependencies through channel attentions. Finally, to better train the framework, we utilize the deeply-supervised learning with multiple boundaryaware loss functions. Extensive experiments demonstrate that our proposed method achieves a new state-of-the-art performance on four public CD benchmarks. For model reproduction, the source code is released at https://github.com/AI-Zhpp/FTN.