 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultispectral Object Detection
Papers and Code
SpectraDINO: Bridging the Spectral Gap in Vision Foundation Models via Lightweight Adapters
May 04, 2026Vision Foundation Models (VFMs) pretrained on large-scale RGB data have demonstrated remarkable representation quality, yet their applicability to multispectral imaging spanning Near-Infrared (NIR), Short-Wave Infrared (SWIR), and Long-Wave Infrared (LWIR) remains largely unexplored. These spectral modalities offer complementary sensing capabilities critical for robust perception in adverse conditions, but present a fundamental domain gap relative to RGB-centric pretrained models. We present SpectraDINO, a multispectral VFM that bridges this spectral gap by extending DINOv2 ViT backbones to beyond-visible modalities through lightweight, per-modality bottleneck adapters, while preserving the rich representations of the frozen RGB backbone. We introduce a multi-stage teacher-student training protocol in which a frozen DINOv2 teacher guides a spectral student via cosine distillation, symmetric contrastive loss, patch-level alignment, and a novel neighborhood-structure-preservation loss. This staged curriculum enables strong cross-modal alignment without catastrophic forgetting of RGB priors. We evaluate SpectraDINO on multispectral object detection and semantic segmentation across challenging NIR, SWIR, and LWIR benchmarks using widely adopted fusion strategies. SpectraDINO achieves state-of-the-art performance across most benchmarks, validating its effectiveness as a general-purpose backbone for spectral generalization. The code and weights for model variants are available at https://github.com/Yonsei-STL/SpectraDINO.
Bridging the RGB-IR Gap: Consensus and Discrepancy Modeling for Text-Guided Multispectral Detection
Apr 13, 2026Text-guided multispectral object detection uses text semantics to guide semantic-aware cross-modal interaction between RGB and IR for more robust perception. However, notable limitations remain: (1) existing methods often use text only as an auxiliary semantic enhancement signal, without exploiting its guiding role to bridge the inherent granularity asymmetry between RGB and IR; and (2) conventional data-driven attention-based fusion tends to emphasize stable consensus while overlooking potentially valuable cross-modal discrepancies. To address these issues, we propose a semantic bridge fusion framework with bi-support modeling for multispectral object detection. Specifically, text is used as a shared semantic bridge to align RGB and IR responses under a unified category condition, while the recalibrated thermal semantic prior is projected onto the RGB branch for semantic-level mapping fusion. We further formulate RGB-IR interaction evidence into the regular consensus support and the complementary discrepancy support that contains potentially discriminative cues, and introduce them into fusion via dynamic recalibration as a structured inductive bias. In addition, we design a bidirectional semantic alignment module for closed-loop vision-text guidance enhancement. Extensive experiments demonstrate the effectiveness of the proposed fusion framework and its superior detection performance on multispectral benchmarks. Code is available at https://github.com/zhenwang5372/Bridging-RGB-IR-Gap.
Brewing Stronger Features: Dual-Teacher Distillation for Multispectral Earth Observation
Feb 24, 2026Foundation models are transforming Earth Observation (EO), yet the diversity of EO sensors and modalities makes a single universal model unrealistic. Multiple specialized EO foundation models (EOFMs) will likely coexist, making efficient knowledge transfer across modalities essential. Most existing EO pretraining relies on masked image modeling, which emphasizes local reconstruction but provides limited control over global semantic structure. To address this, we propose a dual-teacher contrastive distillation framework for multispectral imagery that aligns the student's pretraining objective with the contrastive self-distillation paradigm of modern optical vision foundation models (VFMs). Our approach combines a multispectral teacher with an optical VFM teacher, enabling coherent cross-modal representation learning. Experiments across diverse optical and multispectral benchmarks show that our model adapts to multispectral data without compromising performance on optical-only inputs, achieving state-of-the-art results in both settings, with an average improvement of 3.64 percentage points in semantic segmentation, 1.2 in change detection, and 1.31 in classification tasks. This demonstrates that contrastive distillation provides a principled and efficient approach to scalable representation learning across heterogeneous EO data sources. Project page: \textcolor{magenta}{https://wolfilip.github.io/DEO/}.
From Words to Wavelengths: VLMs for Few-Shot Multispectral Object Detection
Dec 17, 2025
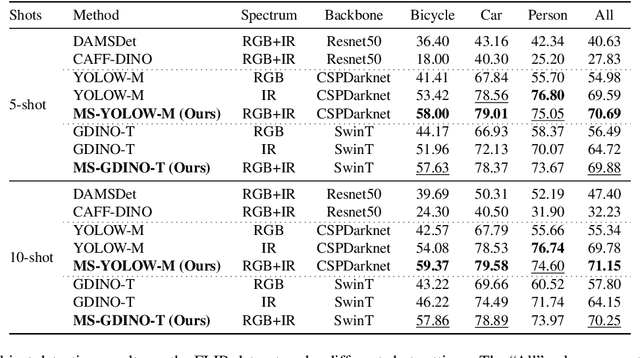

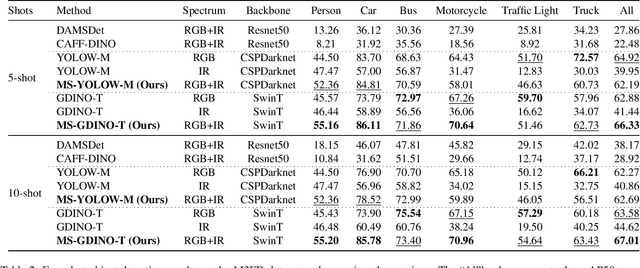
Multispectral object detection is critical for safety-sensitive applications such as autonomous driving and surveillance, where robust perception under diverse illumination conditions is essential. However, the limited availability of annotated multispectral data severely restricts the training of deep detectors. In such data-scarce scenarios, textual class information can serve as a valuable source of semantic supervision. Motivated by the recent success of Vision-Language Models (VLMs) in computer vision, we explore their potential for few-shot multispectral object detection. Specifically, we adapt two representative VLM-based detectors, Grounding DINO and YOLO-World, to handle multispectral inputs and propose an effective mechanism to integrate text, visual and thermal modalities. Through extensive experiments on two popular multispectral image benchmarks, FLIR and M3FD, we demonstrate that VLM-based detectors not only excel in few-shot regimes, significantly outperforming specialized multispectral models trained with comparable data, but also achieve competitive or superior results under fully supervised settings. Our findings reveal that the semantic priors learned by large-scale VLMs effectively transfer to unseen spectral modalities, ofFering a powerful pathway toward data-efficient multispectral perception.
MODA: The First Challenging Benchmark for Multispectral Object Detection in Aerial Images
Dec 10, 2025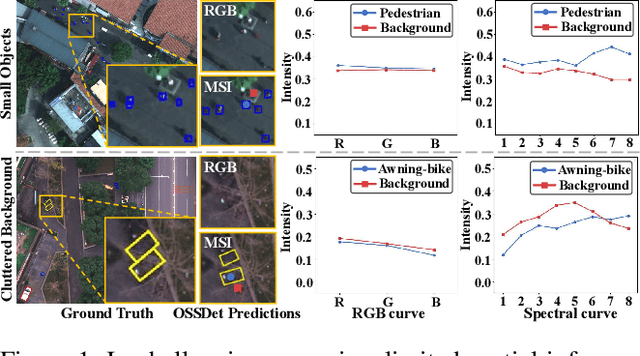


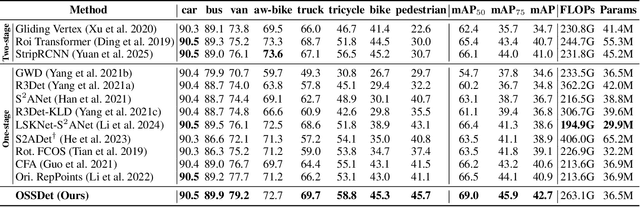
Aerial object detection faces significant challenges in real-world scenarios, such as small objects and extensive background interference, which limit the performance of RGB-based detectors with insufficient discriminative information. Multispectral images (MSIs) capture additional spectral cues across multiple bands, offering a promising alternative. However, the lack of training data has been the primary bottleneck to exploiting the potential of MSIs. To address this gap, we introduce the first large-scale dataset for Multispectral Object Detection in Aerial images (MODA), which comprises 14,041 MSIs and 330,191 annotations across diverse, challenging scenarios, providing a comprehensive data foundation for this field. Furthermore, to overcome challenges inherent to aerial object detection using MSIs, we propose OSSDet, a framework that integrates spectral and spatial information with object-aware cues. OSSDet employs a cascaded spectral-spatial modulation structure to optimize target perception, aggregates spectrally related features by exploiting spectral similarities to reinforce intra-object correlations, and suppresses irrelevant background via object-aware masking. Moreover, cross-spectral attention further refines object-related representations under explicit object-aware guidance. Extensive experiments demonstrate that OSSDet outperforms existing methods with comparable parameters and efficiency.
SFFR: Spatial-Frequency Feature Reconstruction for Multispectral Aerial Object Detection
Nov 17, 2025Recent multispectral object detection methods have primarily focused on spatial-domain feature fusion based on CNNs or Transformers, while the potential of frequency-domain feature remains underexplored. In this work, we propose a novel Spatial and Frequency Feature Reconstruction method (SFFR) method, which leverages the spatial-frequency feature representation mechanisms of the Kolmogorov-Arnold Network (KAN) to reconstruct complementary representations in both spatial and frequency domains prior to feature fusion. The core components of SFFR are the proposed Frequency Component Exchange KAN (FCEKAN) module and Multi-Scale Gaussian KAN (MSGKAN) module. The FCEKAN introduces an innovative selective frequency component exchange strategy that effectively enhances the complementarity and consistency of cross-modal features based on the frequency feature of RGB and IR images. The MSGKAN module demonstrates excellent nonlinear feature modeling capability in the spatial domain. By leveraging multi-scale Gaussian basis functions, it effectively captures the feature variations caused by scale changes at different UAV flight altitudes, significantly enhancing the model's adaptability and robustness to scale variations. It is experimentally validated that our proposed FCEKAN and MSGKAN modules are complementary and can effectively capture the frequency and spatial semantic features respectively for better feature fusion. Extensive experiments on the SeaDroneSee, DroneVehicle and DVTOD datasets demonstrate the superior performance and significant advantages of the proposed method in UAV multispectral object perception task. Code will be available at https://github.com/qchenyu1027/SFFR.
IRDFusion: Iterative Relation-Map Difference guided Feature Fusion for Multispectral Object Detection
Sep 11, 2025Current multispectral object detection methods often retain extraneous background or noise during feature fusion, limiting perceptual performance.To address this, we propose an innovative feature fusion framework based on cross-modal feature contrastive and screening strategy, diverging from conventional approaches. The proposed method adaptively enhances salient structures by fusing object-aware complementary cross-modal features while suppressing shared background interference.Our solution centers on two novel, specially designed modules: the Mutual Feature Refinement Module (MFRM) and the Differential Feature Feedback Module (DFFM). The MFRM enhances intra- and inter-modal feature representations by modeling their relationships, thereby improving cross-modal alignment and discriminative power.Inspired by feedback differential amplifiers, the DFFM dynamically computes inter-modal differential features as guidance signals and feeds them back to the MFRM, enabling adaptive fusion of complementary information while suppressing common-mode noise across modalities. To enable robust feature learning, the MFRM and DFFM are integrated into a unified framework, which is formally formulated as an Iterative Relation-Map Differential Guided Feature Fusion mechanism, termed IRDFusion. IRDFusion enables high-quality cross-modal fusion by progressively amplifying salient relational signals through iterative feedback, while suppressing feature noise, leading to significant performance gains.In extensive experiments on FLIR, LLVIP and M$^3$FD datasets, IRDFusion achieves state-of-the-art performance and consistently outperforms existing methods across diverse challenging scenarios, demonstrating its robustness and effectiveness. Code will be available at https://github.com/61s61min/IRDFusion.git.
MCOD: The First Challenging Benchmark for Multispectral Camouflaged Object Detection
Sep 19, 2025



Camouflaged Object Detection (COD) aims to identify objects that blend seamlessly into natural scenes. Although RGB-based methods have advanced, their performance remains limited under challenging conditions. Multispectral imagery, providing rich spectral information, offers a promising alternative for enhanced foreground-background discrimination. However, existing COD benchmark datasets are exclusively RGB-based, lacking essential support for multispectral approaches, which has impeded progress in this area. To address this gap, we introduce MCOD, the first challenging benchmark dataset specifically designed for multispectral camouflaged object detection. MCOD features three key advantages: (i) Comprehensive challenge attributes: It captures real-world difficulties such as small object sizes and extreme lighting conditions commonly encountered in COD tasks. (ii) Diverse real-world scenarios: The dataset spans a wide range of natural environments to better reflect practical applications. (iii) High-quality pixel-level annotations: Each image is manually annotated with precise object masks and corresponding challenge attribute labels. We benchmark eleven representative COD methods on MCOD, observing a consistent performance drop due to increased task difficulty. Notably, integrating multispectral modalities substantially alleviates this degradation, highlighting the value of spectral information in enhancing detection robustness. We anticipate MCOD will provide a strong foundation for future research in multispectral camouflaged object detection. The dataset is publicly accessible at https://github.com/yl2900260-bit/MCOD.
GEO-Bench-2: From Performance to Capability, Rethinking Evaluation in Geospatial AI
Nov 19, 2025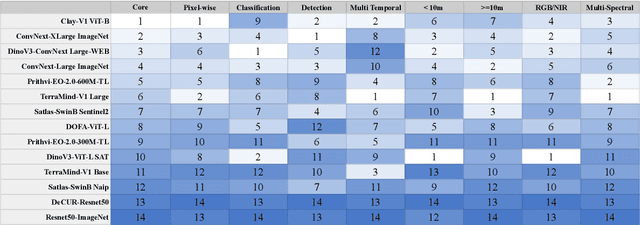


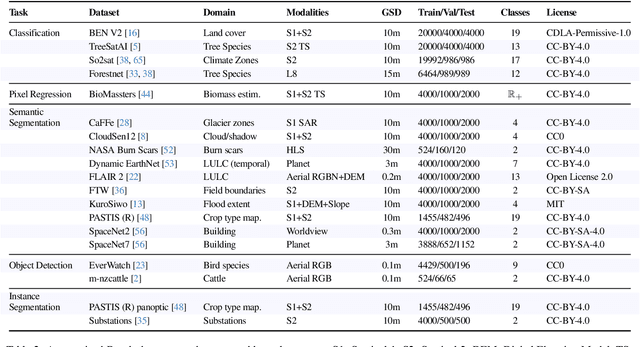
Geospatial Foundation Models (GeoFMs) are transforming Earth Observation (EO), but evaluation lacks standardized protocols. GEO-Bench-2 addresses this with a comprehensive framework spanning classification, segmentation, regression, object detection, and instance segmentation across 19 permissively-licensed datasets. We introduce ''capability'' groups to rank models on datasets that share common characteristics (e.g., resolution, bands, temporality). This enables users to identify which models excel in each capability and determine which areas need improvement in future work. To support both fair comparison and methodological innovation, we define a prescriptive yet flexible evaluation protocol. This not only ensures consistency in benchmarking but also facilitates research into model adaptation strategies, a key and open challenge in advancing GeoFMs for downstream tasks. Our experiments show that no single model dominates across all tasks, confirming the specificity of the choices made during architecture design and pretraining. While models pretrained on natural images (ConvNext ImageNet, DINO V3) excel on high-resolution tasks, EO-specific models (TerraMind, Prithvi, and Clay) outperform them on multispectral applications such as agriculture and disaster response. These findings demonstrate that optimal model choice depends on task requirements, data modalities, and constraints. This shows that the goal of a single GeoFM model that performs well across all tasks remains open for future research. GEO-Bench-2 enables informed, reproducible GeoFM evaluation tailored to specific use cases. Code, data, and leaderboard for GEO-Bench-2 are publicly released under a permissive license.
DEPF: A UAV Multispectral Object Detector with Dual-Domain Enhancement and Priority-Guided Mamba Fusion
Sep 09, 2025Multispectral remote sensing object detection is one of the important application of unmanned aerial vehicle (UAV). However, it faces three challenges. Firstly, the low-light remote sensing images reduce the complementarity during multi-modality fusion. Secondly, the local small target modeling is interfered with redundant information in the fusion stage easily. Thirdly, due to the quadratic computational complexity, it is hard to apply the transformer-based methods on the UAV platform. To address these limitations, motivated by Mamba with linear complexity, a UAV multispectral object detector with dual-domain enhancement and priority-guided mamba fusion (DEPF) is proposed. Firstly, to enhance low-light remote sensing images, Dual-Domain Enhancement Module (DDE) is designed, which contains Cross-Scale Wavelet Mamba (CSWM) and Fourier Details Recovery block (FDR). CSWM applies cross-scale mamba scanning for the low-frequency components to enhance the global brightness of images, while FDR constructs spectrum recovery network to enhance the frequency spectra features for recovering the texture-details. Secondly, to enhance local target modeling and reduce the impact of redundant information during fusion, Priority-Guided Mamba Fusion Module (PGMF) is designed. PGMF introduces the concept of priority scanning, which starts from local targets features according to the priority scores obtained from modality difference. Experiments on DroneVehicle dataset and VEDAI dataset reports that, DEPF performs well on object detection, comparing with state-of-the-art methods. Our code is available in the supplementary material.