 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSIGMA: A Physics-Based Benchmark for Gas Chimney Understanding in Seismic Images
Mar 24, 2026Seismic images reconstruct subsurface reflectivity from field recordings, guiding exploration and reservoir monitoring. Gas chimneys are vertical anomalies caused by subsurface fluid migration. Understanding these phenomena is crucial for assessing hydrocarbon potential and avoiding drilling hazards. However, accurate detection is challenging due to strong seismic attenuation and scattering. Traditional physics-based methods are computationally expensive and sensitive to model errors, while deep learning offers efficient alternatives, yet lacks labeled datasets. In this work, we introduce \textbf{SIGMA}, a new physics-based dataset for gas chimney understanding in seismic images, featuring (i) pixel-level gas-chimney mask for detection and (ii) paired degraded and ground-truth image for enhancement. We employed physics-based methods that cover a wide range of geological settings and data acquisition conditions. Comprehensive experiments demonstrate that SIGMA serves as a challenging benchmark for gas chimney interpretation and benefits general seismic understanding.
From Words to Wavelengths: VLMs for Few-Shot Multispectral Object Detection
Dec 17, 2025
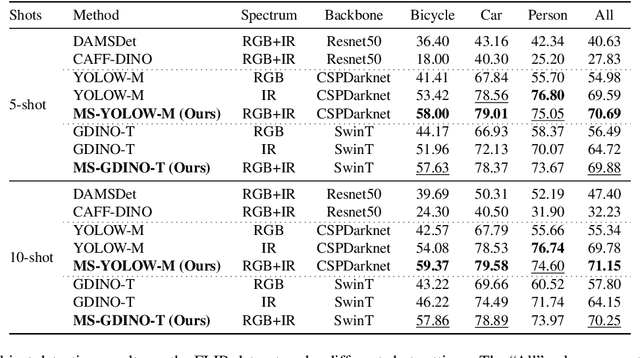

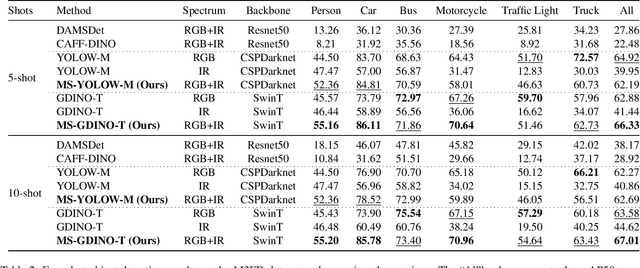
Multispectral object detection is critical for safety-sensitive applications such as autonomous driving and surveillance, where robust perception under diverse illumination conditions is essential. However, the limited availability of annotated multispectral data severely restricts the training of deep detectors. In such data-scarce scenarios, textual class information can serve as a valuable source of semantic supervision. Motivated by the recent success of Vision-Language Models (VLMs) in computer vision, we explore their potential for few-shot multispectral object detection. Specifically, we adapt two representative VLM-based detectors, Grounding DINO and YOLO-World, to handle multispectral inputs and propose an effective mechanism to integrate text, visual and thermal modalities. Through extensive experiments on two popular multispectral image benchmarks, FLIR and M3FD, we demonstrate that VLM-based detectors not only excel in few-shot regimes, significantly outperforming specialized multispectral models trained with comparable data, but also achieve competitive or superior results under fully supervised settings. Our findings reveal that the semantic priors learned by large-scale VLMs effectively transfer to unseen spectral modalities, ofFering a powerful pathway toward data-efficient multispectral perception.
Enhancing deep learning performance on burned area delineation from SPOT-6/7 imagery for emergency management
Dec 12, 2025After a wildfire, delineating burned areas (BAs) is crucial for quantifying damages and supporting ecosystem recovery. Current BA mapping approaches rely on computer vision models trained on post-event remote sensing imagery, but often overlook their applicability to time-constrained emergency management scenarios. This study introduces a supervised semantic segmentation workflow aimed at boosting both the performance and efficiency of BA delineation. It targets SPOT-6/7 imagery due to its very high resolution and on-demand availability. Experiments are evaluated based on Dice score, Intersection over Union, and inference time. The results show that U-Net and SegFormer models perform similarly with limited training data. However, SegFormer requires more resources, challenging its practical use in emergencies. Incorporating land cover data as an auxiliary task enhances model robustness without increasing inference time. Lastly, Test-Time Augmentation improves BA delineation performance but raises inference time, which can be mitigated with optimization methods like Mixed Precision.
Adaptive federated learning for ship detection across diverse satellite imagery sources
Dec 12, 2025We investigate the application of Federated Learning (FL) for ship detection across diverse satellite datasets, offering a privacy-preserving solution that eliminates the need for data sharing or centralized collection. This approach is particularly advantageous for handling commercial satellite imagery or sensitive ship annotations. Four FL models including FedAvg, FedProx, FedOpt, and FedMedian, are evaluated and compared to a local training baseline, where the YOLOv8 ship detection model is independently trained on each dataset without sharing learned parameters. The results reveal that FL models substantially improve detection accuracy over training on smaller local datasets and achieve performance levels close to global training that uses all datasets during the training. Furthermore, the study underscores the importance of selecting appropriate FL configurations, such as the number of communication rounds and local training epochs, to optimize detection precision while maintaining computational efficiency.
RESOUND: Speech Reconstruction from Silent Videos via Acoustic-Semantic Decomposed Modeling
May 28, 2025



Lip-to-speech (L2S) synthesis, which reconstructs speech from visual cues, faces challenges in accuracy and naturalness due to limited supervision in capturing linguistic content, accents, and prosody. In this paper, we propose RESOUND, a novel L2S system that generates intelligible and expressive speech from silent talking face videos. Leveraging source-filter theory, our method involves two components: an acoustic path to predict prosody and a semantic path to extract linguistic features. This separation simplifies learning, allowing independent optimization of each representation. Additionally, we enhance performance by integrating speech units, a proven unsupervised speech representation technique, into waveform generation alongside mel-spectrograms. This allows RESOUND to synthesize prosodic speech while preserving content and speaker identity. Experiments conducted on two standard L2S benchmarks confirm the effectiveness of the proposed method across various metrics.
Towards Efficient Benchmarking of Foundation Models in Remote Sensing: A Capabilities Encoding Approach
May 06, 2025Foundation models constitute a significant advancement in computer vision: after a single, albeit costly, training phase, they can address a wide array of tasks. In the field of Earth observation, over 75 remote sensing vision foundation models have been developed in the past four years. However, none has consistently outperformed the others across all available downstream tasks. To facilitate their comparison, we propose a cost-effective method for predicting a model's performance on multiple downstream tasks without the need for fine-tuning on each one. This method is based on what we call "capabilities encoding." The utility of this novel approach is twofold: we demonstrate its potential to simplify the selection of a foundation model for a given new task, and we employ it to offer a fresh perspective on the existing literature, suggesting avenues for future research. Codes are available at https://github.com/pierreadorni/capabilities-encoding.
Box for Mask and Mask for Box: weak losses for multi-task partially supervised learning
Nov 26, 2024Object detection and semantic segmentation are both scene understanding tasks yet they differ in data structure and information level. Object detection requires box coordinates for object instances while semantic segmentation requires pixel-wise class labels. Making use of one task's information to train the other would be beneficial for multi-task partially supervised learning where each training example is annotated only for a single task, having the potential to expand training sets with different-task datasets. This paper studies various weak losses for partially annotated data in combination with existing supervised losses. We propose Box-for-Mask and Mask-for-Box strategies, and their combination BoMBo, to distil necessary information from one task annotations to train the other. Ablation studies and experimental results on VOC and COCO datasets show favorable results for the proposed idea. Source code and data splits can be found at https://github.com/lhoangan/multas.
Mapping earth mounds from space
Aug 31, 2024Regular patterns of vegetation are considered widespread landscapes, although their global extent has never been estimated. Among them, spotted landscapes are of particular interest in the context of climate change. Indeed, regularly spaced vegetation spots in semi-arid shrublands result from extreme resource depletion and prefigure catastrophic shift of the ecosystem to a homogeneous desert, while termite mounds also producing spotted landscapes were shown to increase robustness to climate change. Yet, their identification at large scale calls for automatic methods, for instance using the popular deep learning framework, able to cope with a vast amount of remote sensing data, e.g., optical satellite imagery. In this paper, we tackle this problem and benchmark some state-of-the-art deep networks on several landscapes and geographical areas. Despite the promising results we obtained, we found that more research is needed to be able to map automatically these earth mounds from space.
Variational Autoencoder for Anomaly Detection: A Comparative Study
Aug 24, 2024This paper aims to conduct a comparative analysis of contemporary Variational Autoencoder (VAE) architectures employed in anomaly detection, elucidating their performance and behavioral characteristics within this specific task. The architectural configurations under consideration encompass the original VAE baseline, the VAE with a Gaussian Random Field prior (VAE-GRF), and the VAE incorporating a vision transformer (ViT-VAE). The findings reveal that ViT-VAE exhibits exemplary performance across various scenarios, whereas VAE-GRF may necessitate more intricate hyperparameter tuning to attain its optimal performance state. Additionally, to mitigate the propensity for over-reliance on results derived from the widely used MVTec dataset, this paper leverages the recently-public MiAD dataset for benchmarking. This deliberate inclusion seeks to enhance result competitiveness by alleviating the impact of domain-specific models tailored exclusively for MVTec, thereby contributing to a more robust evaluation framework. Codes is available at https://github.com/endtheme123/VAE-compare.git.
Leveraging knowledge distillation for partial multi-task learning from multiple remote sensing datasets
May 24, 2024Partial multi-task learning where training examples are annotated for one of the target tasks is a promising idea in remote sensing as it allows combining datasets annotated for different tasks and predicting more tasks with fewer network parameters. The na\"ive approach to partial multi-task learning is sub-optimal due to the lack of all-task annotations for learning joint representations. This paper proposes using knowledge distillation to replace the need of ground truths for the alternate task and enhance the performance of such approach. Experiments conducted on the public ISPRS 2D Semantic Labeling Contest dataset show the effectiveness of the proposed idea on partial multi-task learning for semantic tasks including object detection and semantic segmentation in aerial images.