 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIRDFusion: Iterative Relation-Map Difference guided Feature Fusion for Multispectral Object Detection
Sep 11, 2025Current multispectral object detection methods often retain extraneous background or noise during feature fusion, limiting perceptual performance.To address this, we propose an innovative feature fusion framework based on cross-modal feature contrastive and screening strategy, diverging from conventional approaches. The proposed method adaptively enhances salient structures by fusing object-aware complementary cross-modal features while suppressing shared background interference.Our solution centers on two novel, specially designed modules: the Mutual Feature Refinement Module (MFRM) and the Differential Feature Feedback Module (DFFM). The MFRM enhances intra- and inter-modal feature representations by modeling their relationships, thereby improving cross-modal alignment and discriminative power.Inspired by feedback differential amplifiers, the DFFM dynamically computes inter-modal differential features as guidance signals and feeds them back to the MFRM, enabling adaptive fusion of complementary information while suppressing common-mode noise across modalities. To enable robust feature learning, the MFRM and DFFM are integrated into a unified framework, which is formally formulated as an Iterative Relation-Map Differential Guided Feature Fusion mechanism, termed IRDFusion. IRDFusion enables high-quality cross-modal fusion by progressively amplifying salient relational signals through iterative feedback, while suppressing feature noise, leading to significant performance gains.In extensive experiments on FLIR, LLVIP and M$^3$FD datasets, IRDFusion achieves state-of-the-art performance and consistently outperforms existing methods across diverse challenging scenarios, demonstrating its robustness and effectiveness. Code will be available at https://github.com/61s61min/IRDFusion.git.
G3CN: Gaussian Topology Refinement Gated Graph Convolutional Network for Skeleton-Based Action Recognition
Sep 09, 2025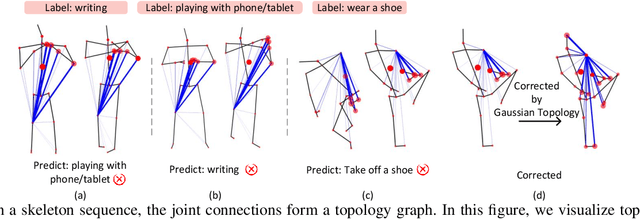
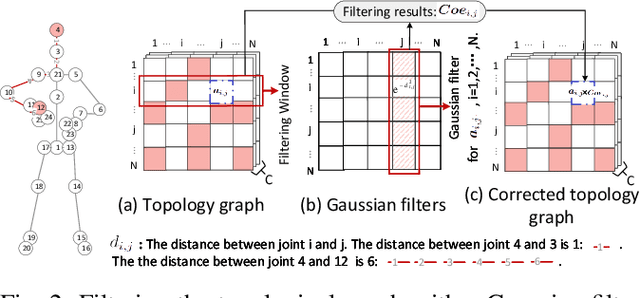
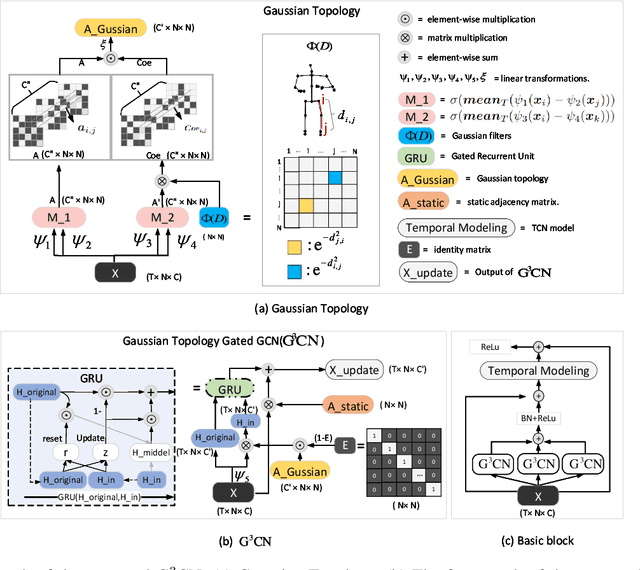
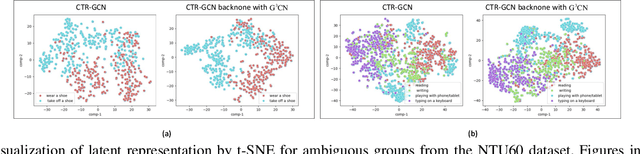
Graph Convolutional Networks (GCNs) have proven to be highly effective for skeleton-based action recognition, primarily due to their ability to leverage graph topology for feature aggregation, a key factor in extracting meaningful representations. However, despite their success, GCNs often struggle to effectively distinguish between ambiguous actions, revealing limitations in the representation of learned topological and spatial features. To address this challenge, we propose a novel approach, Gaussian Topology Refinement Gated Graph Convolution (G$^{3}$CN), to address the challenge of distinguishing ambiguous actions in skeleton-based action recognition. G$^{3}$CN incorporates a Gaussian filter to refine the skeleton topology graph, improving the representation of ambiguous actions. Additionally, Gated Recurrent Units (GRUs) are integrated into the GCN framework to enhance information propagation between skeleton points. Our method shows strong generalization across various GCN backbones. Extensive experiments on NTU RGB+D, NTU RGB+D 120, and NW-UCLA benchmarks demonstrate that G$^{3}$CN effectively improves action recognition, particularly for ambiguous samples.
An Empirical Study of Methods for Small Object Detection from Satellite Imagery
Feb 05, 2025



This paper reviews object detection methods for finding small objects from remote sensing imagery and provides an empirical evaluation of four state-of-the-art methods to gain insights into method performance and technical challenges. In particular, we use car detection from urban satellite images and bee box detection from satellite images of agricultural lands as application scenarios. Drawing from the existing surveys and literature, we identify several top-performing methods for the empirical study. Public, high-resolution satellite image datasets are used in our experiments.
Benchmarking Fish Dataset and Evaluation Metric in Keypoint Detection -- Towards Precise Fish Morphological Assessment in Aquaculture Breeding
May 21, 2024



Accurate phenotypic analysis in aquaculture breeding necessitates the quantification of subtle morphological phenotypes. Existing datasets suffer from limitations such as small scale, limited species coverage, and inadequate annotation of keypoints for measuring refined and complex morphological phenotypes of fish body parts. To address this gap, we introduce FishPhenoKey, a comprehensive dataset comprising 23,331 high-resolution images spanning six fish species. Notably, FishPhenoKey includes 22 phenotype-oriented annotations, enabling the capture of intricate morphological phenotypes. Motivated by the nuanced evaluation of these subtle morphologies, we also propose a new evaluation metric, Percentage of Measured Phenotype (PMP). It is designed to assess the accuracy of individual keypoint positions and is highly sensitive to the phenotypes measured using the corresponding keypoints. To enhance keypoint detection accuracy, we further propose a novel loss, Anatomically-Calibrated Regularization (ACR), that can be integrated into keypoint detection models, leveraging biological insights to refine keypoint localization. Our contributions set a new benchmark in fish phenotype analysis, addressing the challenges of precise morphological quantification and opening new avenues for research in sustainable aquaculture and genetic studies. Our dataset and code are available at https://github.com/WeizhenLiuBioinform/Fish-Phenotype-Detect.
Revealing Hierarchical Structure of Leaf Venations in Plant Science via Label-Efficient Segmentation: Dataset and Method
May 16, 2024Hierarchical leaf vein segmentation is a crucial but under-explored task in agricultural sciences, where analysis of the hierarchical structure of plant leaf venation can contribute to plant breeding. While current segmentation techniques rely on data-driven models, there is no publicly available dataset specifically designed for hierarchical leaf vein segmentation. To address this gap, we introduce the HierArchical Leaf Vein Segmentation (HALVS) dataset, the first public hierarchical leaf vein segmentation dataset. HALVS comprises 5,057 real-scanned high-resolution leaf images collected from three plant species: soybean, sweet cherry, and London planetree. It also includes human-annotated ground truth for three orders of leaf veins, with a total labeling effort of 83.8 person-days. Based on HALVS, we further develop a label-efficient learning paradigm that leverages partial label information, i.e. missing annotations for tertiary veins. Empirical studies are performed on HALVS, revealing new observations, challenges, and research directions on leaf vein segmentation.
Benchmarking the Robustness of UAV Tracking Against Common Corruptions
Mar 18, 2024The robustness of unmanned aerial vehicle (UAV) tracking is crucial in many tasks like surveillance and robotics. Despite its importance, little attention is paid to the performance of UAV trackers under common corruptions due to lack of a dedicated platform. Addressing this, we propose UAV-C, a large-scale benchmark for assessing robustness of UAV trackers under common corruptions. Specifically, UAV-C is built upon two popular UAV datasets by introducing 18 common corruptions from 4 representative categories including adversarial, sensor, blur, and composite corruptions in different levels. Finally, UAV-C contains more than 10K sequences. To understand the robustness of existing UAV trackers against corruptions, we extensively evaluate 12 representative algorithms on UAV-C. Our study reveals several key findings: 1) Current trackers are vulnerable to corruptions, indicating more attention needed in enhancing the robustness of UAV trackers; 2) When accompanying together, composite corruptions result in more severe degradation to trackers; and 3) While each tracker has its unique performance profile, some trackers may be more sensitive to specific corruptions. By releasing UAV-C, we hope it, along with comprehensive analysis, serves as a valuable resource for advancing the robustness of UAV tracking against corruption. Our UAV-C will be available at https://github.com/Xiaoqiong-Liu/UAV-C.
Voting Network for Contour Levee Farmland Segmentation and Classification
Sep 28, 2023High-resolution aerial imagery allows fine details in the segmentation of farmlands. However, small objects and features introduce distortions to the delineation of object boundaries, and larger contextual views are needed to mitigate class confusion. In this work, we present an end-to-end trainable network for segmenting farmlands with contour levees from high-resolution aerial imagery. A fusion block is devised that includes multiple voting blocks to achieve image segmentation and classification. We integrate the fusion block with a backbone and produce both semantic predictions and segmentation slices. The segmentation slices are used to perform majority voting on the predictions. The network is trained to assign the most likely class label of a segment to its pixels, learning the concept of farmlands rather than analyzing constitutive pixels separately. We evaluate our method using images from the National Agriculture Imagery Program. Our method achieved an average accuracy of 94.34\%. Compared to the state-of-the-art methods, the proposed method obtains an improvement of 6.96% and 2.63% in the F1 score on average.
Designing Deep Networks for Scene Recognition
Mar 13, 2023Most deep learning backbones are evaluated on ImageNet. Using scenery images as an example, we conducted extensive experiments to demonstrate the widely accepted principles in network design may result in dramatic performance differences when the data is altered. Exploratory experiments are engaged to explain the underlining cause of the differences. Based on our observation, this paper presents a novel network design methodology: data-oriented network design. In other words, instead of designing universal backbones, the scheming of the networks should treat the characteristics of data as a crucial component. We further proposed a Deep-Narrow Network and Dilated Pooling module, which improved the scene recognition performance using less than half of the computational resources compared to the benchmark network architecture ResNets. The source code is publicly available on https://github.com/ZN-Qiao/Deep-Narrow-Network.
Urban land-use analysis using proximate sensing imagery: a survey
Jan 13, 2021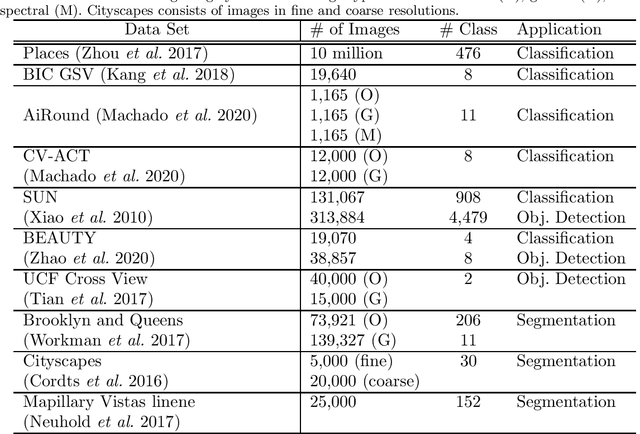
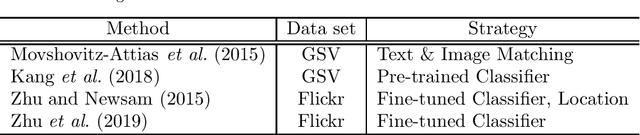
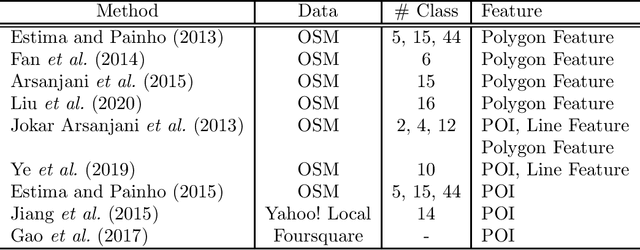
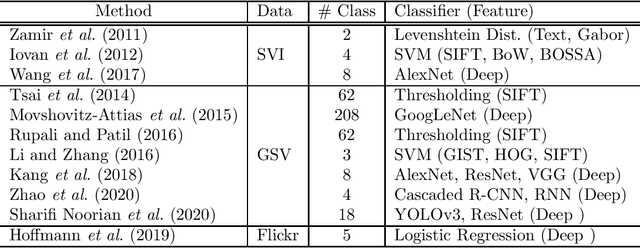
Urban regions are complicated functional systems that are closely associated with and reshaped by human activities. The propagation of online geographic information-sharing platforms and mobile devices equipped with Global Positioning System (GPS) greatly proliferates proximate sensing images taken near or on the ground at a close distance to urban targets. Studies leveraging proximate sensing imagery have demonstrated great potential to address the need for local data in urban land-use analysis. This paper reviews and summarizes the state-of-the-art methods and publicly available datasets from proximate sensing to support land-use analysis. We identify several research problems in the perspective of examples to support training of models and means of integrating diverse data sets. Our discussions highlight the challenges, strategies, and opportunities faced by the existing methods using proximate sensing imagery in urban land-use studies.
Interpretable Deep Learning for Automatic Diagnosis of 12-lead Electrocardiogram
Oct 20, 2020
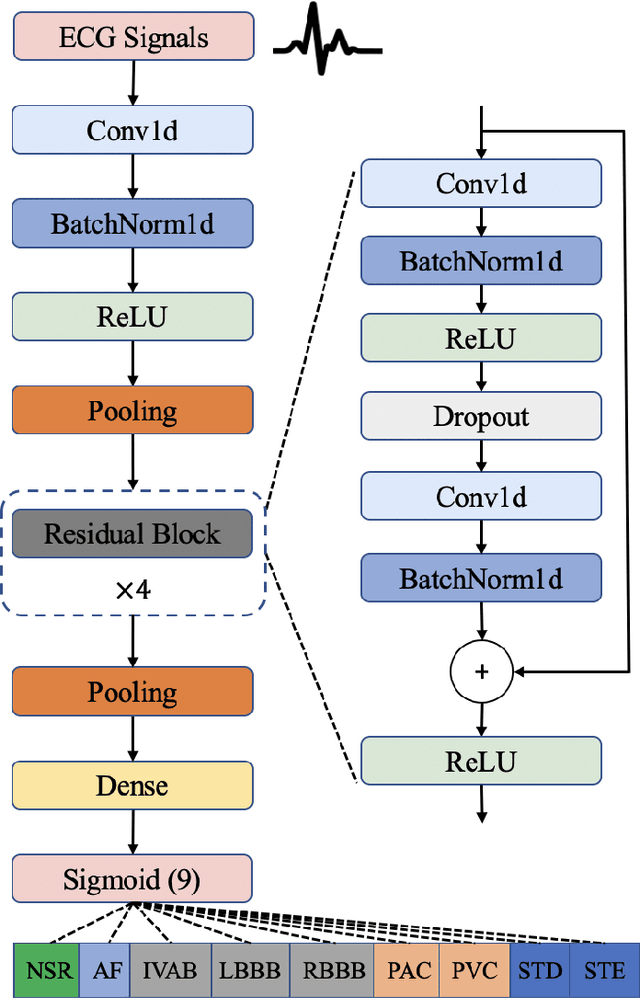
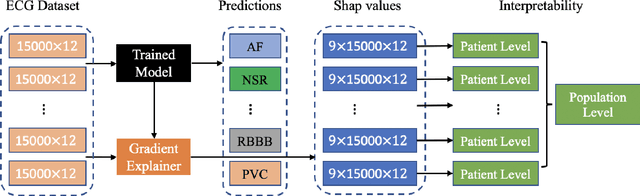
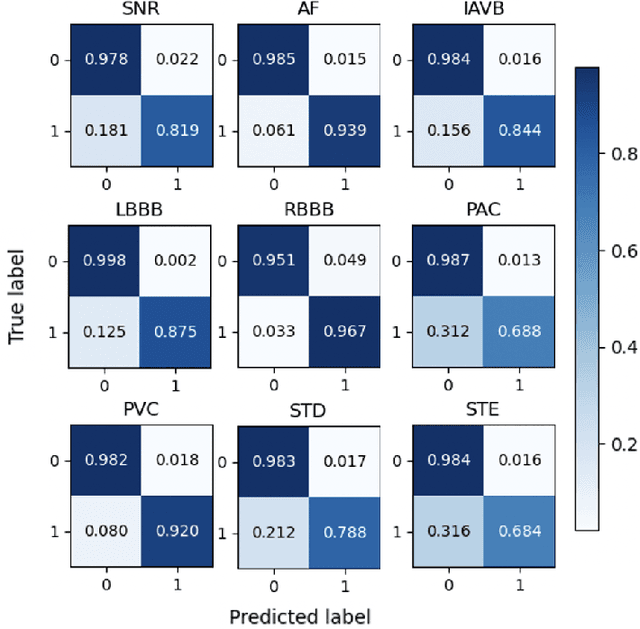
Electrocardiogram (ECG) is a widely used reliable, non-invasive approach for cardiovascular disease diagnosis. With the rapid growth of ECG examinations and the insufficiency of cardiologists, accurate and automatic diagnosis of ECG signals has become a hot research topic. Deep learning methods have demonstrated promising results in predictive healthcare tasks. In this paper, we developed a deep neural network for multi-label classification of cardiac arrhythmias in 12-lead ECG recordings. Experiments on a public 12-lead ECG dataset showed the effectiveness of our method. The proposed model achieved an average area under the receiver operating characteristic curve (AUC) of 0.970 and an average F1 score of 0.813. The deep model showed superior performance than 4 machine learning methods learned from extracted expert features. Besides, the deep models trained on single-lead ECGs produce lower performance than using all 12 leads simultaneously. The best-performing leads are lead I, aVR, and V5 among 12 leads. Finally, we employed the SHapley Additive exPlanations (SHAP) method to interpret the model's behavior at both patient level and population level. Our code is freely available at https://github.com/onlyzdd/ecg-diagnosis.