 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Words to Wavelengths: VLMs for Few-Shot Multispectral Object Detection
Dec 17, 2025
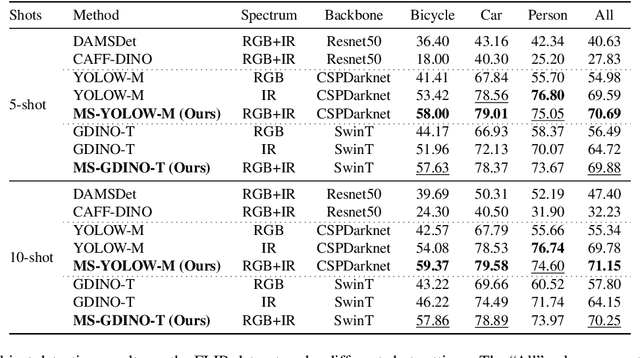

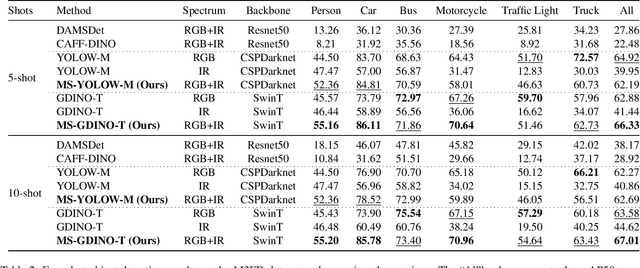
Multispectral object detection is critical for safety-sensitive applications such as autonomous driving and surveillance, where robust perception under diverse illumination conditions is essential. However, the limited availability of annotated multispectral data severely restricts the training of deep detectors. In such data-scarce scenarios, textual class information can serve as a valuable source of semantic supervision. Motivated by the recent success of Vision-Language Models (VLMs) in computer vision, we explore their potential for few-shot multispectral object detection. Specifically, we adapt two representative VLM-based detectors, Grounding DINO and YOLO-World, to handle multispectral inputs and propose an effective mechanism to integrate text, visual and thermal modalities. Through extensive experiments on two popular multispectral image benchmarks, FLIR and M3FD, we demonstrate that VLM-based detectors not only excel in few-shot regimes, significantly outperforming specialized multispectral models trained with comparable data, but also achieve competitive or superior results under fully supervised settings. Our findings reveal that the semantic priors learned by large-scale VLMs effectively transfer to unseen spectral modalities, ofFering a powerful pathway toward data-efficient multispectral perception.
Localize to Classify and Classify to Localize: Mutual Guidance in Object Detection
Sep 29, 2020
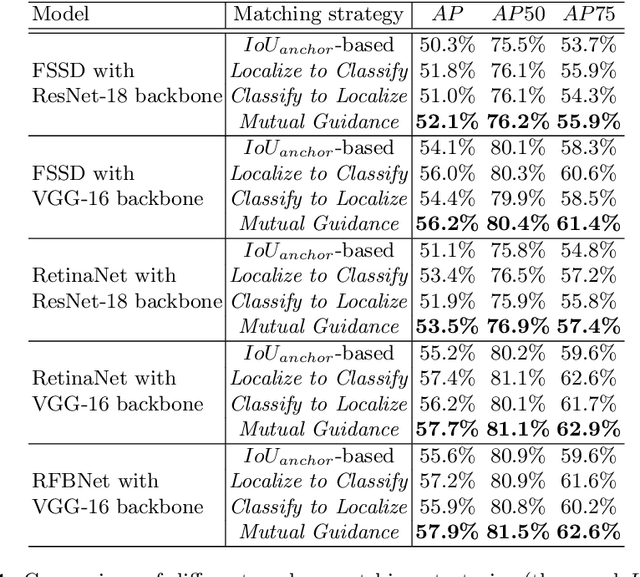
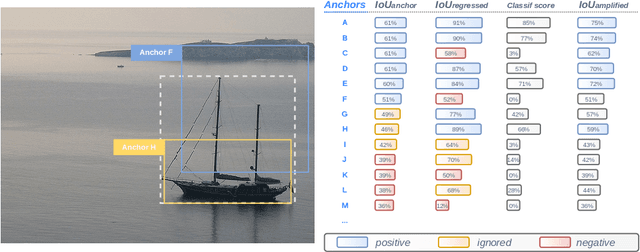
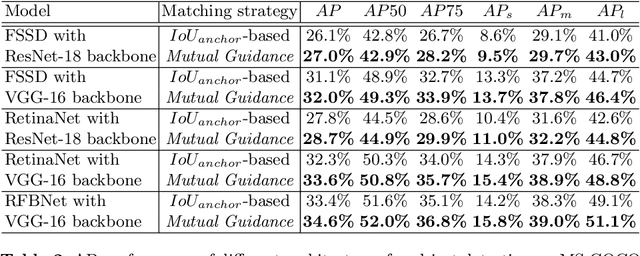
Most deep learning object detectors are based on the anchor mechanism and resort to the Intersection over Union (IoU) between predefined anchor boxes and ground truth boxes to evaluate the matching quality between anchors and objects. In this paper, we question this use of IoU and propose a new anchor matching criterion guided, during the training phase, by the optimization of both the localization and the classification tasks: the predictions related to one task are used to dynamically assign sample anchors and improve the model on the other task, and vice versa. Despite the simplicity of the proposed method, our experiments with different state-of-the-art deep learning architectures on PASCAL VOC and MS COCO datasets demonstrate the effectiveness and generality of our Mutual Guidance strategy.
Multispectral Fusion for Object Detection with Cyclic Fuse-and-Refine Blocks
Sep 26, 2020
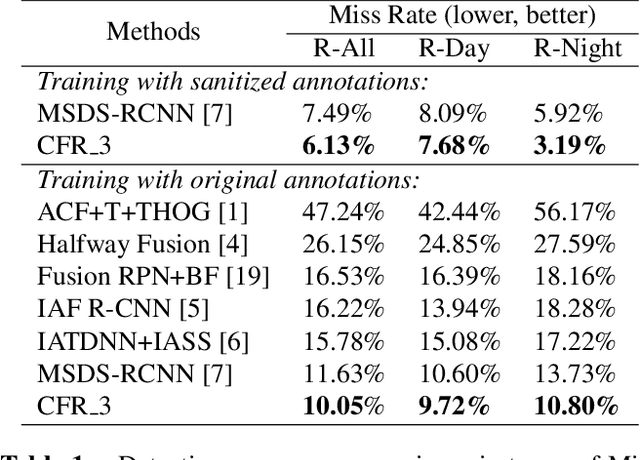
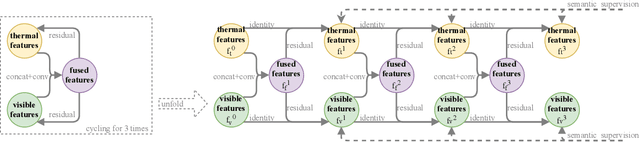
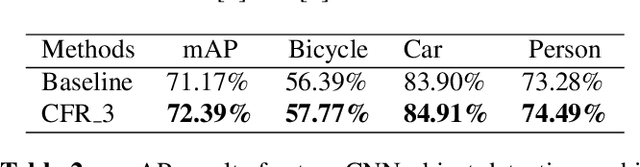
Multispectral images (e.g. visible and infrared) may be particularly useful when detecting objects with the same model in different environments (e.g. day/night outdoor scenes). To effectively use the different spectra, the main technical problem resides in the information fusion process. In this paper, we propose a new halfway feature fusion method for neural networks that leverages the complementary/consistency balance existing in multispectral features by adding to the network architecture, a particular module that cyclically fuses and refines each spectral feature. We evaluate the effectiveness of our fusion method on two challenging multispectral datasets for object detection. Our results show that implementing our Cyclic Fuse-and-Refine module in any network improves the performance on both datasets compared to other state-of-the-art multispectral object detection methods.