 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenEarthAgent: A Unified Framework for Tool-Augmented Geospatial Agents
Feb 19, 2026Recent progress in multimodal reasoning has enabled agents that can interpret imagery, connect it with language, and perform structured analytical tasks. Extending such capabilities to the remote sensing domain remains challenging, as models must reason over spatial scale, geographic structures, and multispectral indices while maintaining coherent multi-step logic. To bridge this gap, OpenEarthAgent introduces a unified framework for developing tool-augmented geospatial agents trained on satellite imagery, natural-language queries, and detailed reasoning traces. The training pipeline relies on supervised fine-tuning over structured reasoning trajectories, aligning the model with verified multistep tool interactions across diverse analytical contexts. The accompanying corpus comprises 14,538 training and 1,169 evaluation instances, with more than 100K reasoning steps in the training split and over 7K reasoning steps in the evaluation split. It spans urban, environmental, disaster, and infrastructure domains, and incorporates GIS-based operations alongside index analyses such as NDVI, NBR, and NDBI. Grounded in explicit reasoning traces, the learned agent demonstrates structured reasoning, stable spatial understanding, and interpretable behaviour through tool-driven geospatial interactions across diverse conditions. We report consistent improvements over a strong baseline and competitive performance relative to recent open and closed-source models.
GEO-Bench-2: From Performance to Capability, Rethinking Evaluation in Geospatial AI
Nov 19, 2025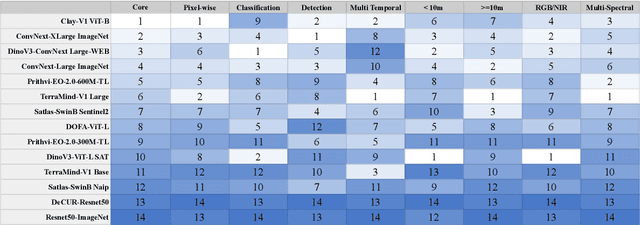


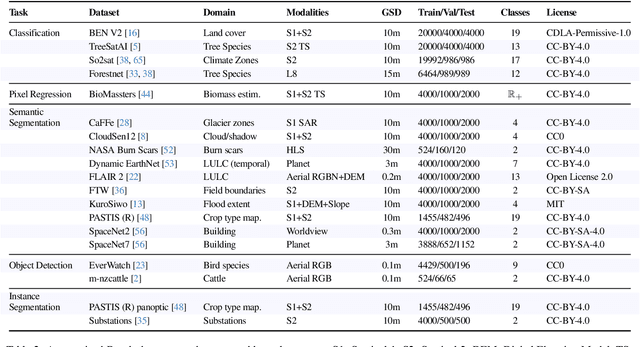
Geospatial Foundation Models (GeoFMs) are transforming Earth Observation (EO), but evaluation lacks standardized protocols. GEO-Bench-2 addresses this with a comprehensive framework spanning classification, segmentation, regression, object detection, and instance segmentation across 19 permissively-licensed datasets. We introduce ''capability'' groups to rank models on datasets that share common characteristics (e.g., resolution, bands, temporality). This enables users to identify which models excel in each capability and determine which areas need improvement in future work. To support both fair comparison and methodological innovation, we define a prescriptive yet flexible evaluation protocol. This not only ensures consistency in benchmarking but also facilitates research into model adaptation strategies, a key and open challenge in advancing GeoFMs for downstream tasks. Our experiments show that no single model dominates across all tasks, confirming the specificity of the choices made during architecture design and pretraining. While models pretrained on natural images (ConvNext ImageNet, DINO V3) excel on high-resolution tasks, EO-specific models (TerraMind, Prithvi, and Clay) outperform them on multispectral applications such as agriculture and disaster response. These findings demonstrate that optimal model choice depends on task requirements, data modalities, and constraints. This shows that the goal of a single GeoFM model that performs well across all tasks remains open for future research. GEO-Bench-2 enables informed, reproducible GeoFM evaluation tailored to specific use cases. Code, data, and leaderboard for GEO-Bench-2 are publicly released under a permissive license.
ThinkGeo: Evaluating Tool-Augmented Agents for Remote Sensing Tasks
May 29, 2025



Recent progress in large language models (LLMs) has enabled tool-augmented agents capable of solving complex real-world tasks through step-by-step reasoning. However, existing evaluations often focus on general-purpose or multimodal scenarios, leaving a gap in domain-specific benchmarks that assess tool-use capabilities in complex remote sensing use cases. We present ThinkGeo, an agentic benchmark designed to evaluate LLM-driven agents on remote sensing tasks via structured tool use and multi-step planning. Inspired by tool-interaction paradigms, ThinkGeo includes human-curated queries spanning a wide range of real-world applications such as urban planning, disaster assessment and change analysis, environmental monitoring, transportation analysis, aviation monitoring, recreational infrastructure, and industrial site analysis. Each query is grounded in satellite or aerial imagery and requires agents to reason through a diverse toolset. We implement a ReAct-style interaction loop and evaluate both open and closed-source LLMs (e.g., GPT-4o, Qwen2.5) on 436 structured agentic tasks. The benchmark reports both step-wise execution metrics and final answer correctness. Our analysis reveals notable disparities in tool accuracy and planning consistency across models. ThinkGeo provides the first extensive testbed for evaluating how tool-enabled LLMs handle spatial reasoning in remote sensing. Our code and dataset are publicly available
Fine-tune Smarter, Not Harder: Parameter-Efficient Fine-Tuning for Geospatial Foundation Models
Apr 24, 2025



Earth observation (EO) is crucial for monitoring environmental changes, responding to disasters, and managing natural resources. In this context, foundation models facilitate remote sensing image analysis to retrieve relevant geoinformation accurately and efficiently. However, as these models grow in size, fine-tuning becomes increasingly challenging due to the associated computational resources and costs, limiting their accessibility and scalability. Furthermore, full fine-tuning can lead to forgetting pre-trained features and even degrade model generalization. To address this, Parameter-Efficient Fine-Tuning (PEFT) techniques offer a promising solution. In this paper, we conduct extensive experiments with various foundation model architectures and PEFT techniques to evaluate their effectiveness on five different EO datasets. Our results provide a comprehensive comparison, offering insights into when and how PEFT methods support the adaptation of pre-trained geospatial models. We demonstrate that PEFT techniques match or even exceed full fine-tuning performance and enhance model generalisation to unseen geographic regions, while reducing training time and memory requirements. Additional experiments investigate the effect of architecture choices such as the decoder type or the use of metadata, suggesting UNet decoders and fine-tuning without metadata as the recommended configuration. We have integrated all evaluated foundation models and techniques into the open-source package TerraTorch to support quick, scalable, and cost-effective model adaptation.
Hyperspectral Vision Transformers for Greenhouse Gas Estimations from Space
Apr 23, 2025Hyperspectral imaging provides detailed spectral information and holds significant potential for monitoring of greenhouse gases (GHGs). However, its application is constrained by limited spatial coverage and infrequent revisit times. In contrast, multispectral imaging offers broader spatial and temporal coverage but often lacks the spectral detail that can enhance GHG detection. To address these challenges, this study proposes a spectral transformer model that synthesizes hyperspectral data from multispectral inputs. The model is pre-trained via a band-wise masked autoencoder and subsequently fine-tuned on spatio-temporally aligned multispectral-hyperspectral image pairs. The resulting synthetic hyperspectral data retain the spatial and temporal benefits of multispectral imagery and improve GHG prediction accuracy relative to using multispectral data alone. This approach effectively bridges the trade-off between spectral resolution and coverage, highlighting its potential to advance atmospheric monitoring by combining the strengths of hyperspectral and multispectral systems with self-supervised deep learning.
TerraMind: Large-Scale Generative Multimodality for Earth Observation
Apr 15, 2025



We present TerraMind, the first any-to-any generative, multimodal foundation model for Earth observation (EO). Unlike other multimodal models, TerraMind is pretrained on dual-scale representations combining both token-level and pixel-level data across modalities. On a token level, TerraMind encodes high-level contextual information to learn cross-modal relationships, while on a pixel level, TerraMind leverages fine-grained representations to capture critical spatial nuances. We pretrained TerraMind on nine geospatial modalities of a global, large-scale dataset. In this paper, we demonstrate that (i) TerraMind's dual-scale early fusion approach unlocks a range of zero-shot and few-shot applications for Earth observation, (ii) TerraMind introduces "Thinking-in-Modalities" (TiM) -- the capability of generating additional artificial data during finetuning and inference to improve the model output -- and (iii) TerraMind achieves beyond state-of-the-art performance in community-standard benchmarks for EO like PANGAEA. The pretraining dataset, the model weights, and our code is open-sourced under a permissive license.
TerraMesh: A Planetary Mosaic of Multimodal Earth Observation Data
Apr 15, 2025Large-scale foundation models in Earth Observation can learn versatile, label-efficient representations by leveraging massive amounts of unlabeled data. However, existing public datasets are often limited in scale, geographic coverage, or sensor variety. We introduce TerraMesh, a new globally diverse, multimodal dataset combining optical, synthetic aperture radar, elevation, and land-cover modalities in an Analysis-Ready Data format. TerraMesh includes over 9 million samples with eight spatiotemporal aligned modalities, enabling large-scale pre-training and fostering robust cross-modal correlation learning. We provide detailed data processing steps, comprehensive statistics, and empirical evidence demonstrating improved model performance when pre-trained on TerraMesh. The dataset will be made publicly available with a permissive license.
TerraTorch: The Geospatial Foundation Models Toolkit
Mar 26, 2025



TerraTorch is a fine-tuning and benchmarking toolkit for Geospatial Foundation Models built on PyTorch Lightning and tailored for satellite, weather, and climate data. It integrates domain-specific data modules, pre-defined tasks, and a modular model factory that pairs any backbone with diverse decoder heads. These components allow researchers and practitioners to fine-tune supported models in a no-code fashion by simply editing a training configuration. By consolidating best practices for model development and incorporating the automated hyperparameter optimization extension Iterate, TerraTorch reduces the expertise and time required to fine-tune or benchmark models on new Earth Observation use cases. Furthermore, TerraTorch directly integrates with GEO-Bench, allowing for systematic and reproducible benchmarking of Geospatial Foundation Models. TerraTorch is open sourced under Apache 2.0, available at https://github.com/IBM/terratorch, and can be installed via pip install terratorch.
Lossy Neural Compression for Geospatial Analytics: A Review
Mar 03, 2025



Over the past decades, there has been an explosion in the amount of available Earth Observation (EO) data. The unprecedented coverage of the Earth's surface and atmosphere by satellite imagery has resulted in large volumes of data that must be transmitted to ground stations, stored in data centers, and distributed to end users. Modern Earth System Models (ESMs) face similar challenges, operating at high spatial and temporal resolutions, producing petabytes of data per simulated day. Data compression has gained relevance over the past decade, with neural compression (NC) emerging from deep learning and information theory, making EO data and ESM outputs ideal candidates due to their abundance of unlabeled data. In this review, we outline recent developments in NC applied to geospatial data. We introduce the fundamental concepts of NC including seminal works in its traditional applications to image and video compression domains with focus on lossy compression. We discuss the unique characteristics of EO and ESM data, contrasting them with "natural images", and explain the additional challenges and opportunities they present. Moreover, we review current applications of NC across various EO modalities and explore the limited efforts in ESM compression to date. The advent of self-supervised learning (SSL) and foundation models (FM) has advanced methods to efficiently distill representations from vast unlabeled data. We connect these developments to NC for EO, highlighting the similarities between the two fields and elaborate on the potential of transferring compressed feature representations for machine--to--machine communication. Based on insights drawn from this review, we devise future directions relevant to applications in EO and ESM.
Multispectral to Hyperspectral using Pretrained Foundational model
Feb 26, 2025



Hyperspectral imaging provides detailed spectral information, offering significant potential for monitoring greenhouse gases like CH4 and NO2. However, its application is constrained by limited spatial coverage and infrequent revisit times. In contrast, multispectral imaging delivers broader spatial and temporal coverage but lacks the spectral granularity required for precise GHG detection. To address these challenges, this study proposes Spectral and Spatial-Spectral transformer models that reconstruct hyperspectral data from multispectral inputs. The models in this paper are pretrained on EnMAP and EMIT datasets and fine-tuned on spatio-temporally aligned (Sentinel-2, EnMAP) and (HLS-S30, EMIT) image pairs respectively. Our model has the potential to enhance atmospheric monitoring by combining the strengths of hyperspectral and multispectral imaging systems.