 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGEO-Bench-2: From Performance to Capability, Rethinking Evaluation in Geospatial AI
Nov 19, 2025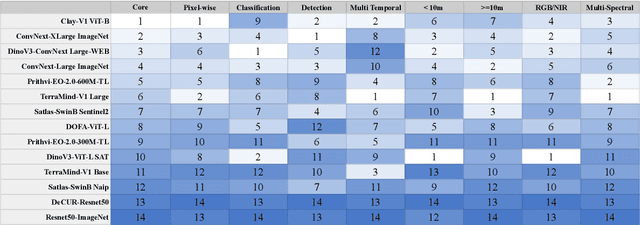


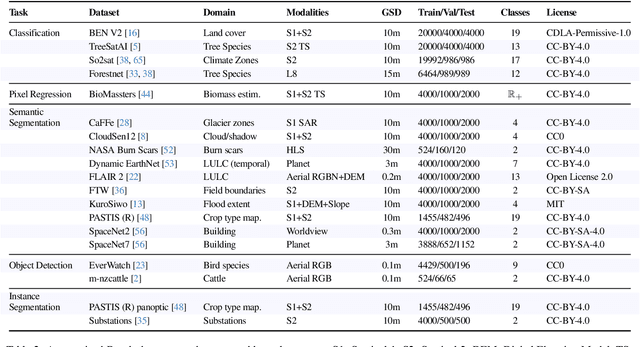
Geospatial Foundation Models (GeoFMs) are transforming Earth Observation (EO), but evaluation lacks standardized protocols. GEO-Bench-2 addresses this with a comprehensive framework spanning classification, segmentation, regression, object detection, and instance segmentation across 19 permissively-licensed datasets. We introduce ''capability'' groups to rank models on datasets that share common characteristics (e.g., resolution, bands, temporality). This enables users to identify which models excel in each capability and determine which areas need improvement in future work. To support both fair comparison and methodological innovation, we define a prescriptive yet flexible evaluation protocol. This not only ensures consistency in benchmarking but also facilitates research into model adaptation strategies, a key and open challenge in advancing GeoFMs for downstream tasks. Our experiments show that no single model dominates across all tasks, confirming the specificity of the choices made during architecture design and pretraining. While models pretrained on natural images (ConvNext ImageNet, DINO V3) excel on high-resolution tasks, EO-specific models (TerraMind, Prithvi, and Clay) outperform them on multispectral applications such as agriculture and disaster response. These findings demonstrate that optimal model choice depends on task requirements, data modalities, and constraints. This shows that the goal of a single GeoFM model that performs well across all tasks remains open for future research. GEO-Bench-2 enables informed, reproducible GeoFM evaluation tailored to specific use cases. Code, data, and leaderboard for GEO-Bench-2 are publicly released under a permissive license.
TerraTorch: The Geospatial Foundation Models Toolkit
Mar 26, 2025



TerraTorch is a fine-tuning and benchmarking toolkit for Geospatial Foundation Models built on PyTorch Lightning and tailored for satellite, weather, and climate data. It integrates domain-specific data modules, pre-defined tasks, and a modular model factory that pairs any backbone with diverse decoder heads. These components allow researchers and practitioners to fine-tune supported models in a no-code fashion by simply editing a training configuration. By consolidating best practices for model development and incorporating the automated hyperparameter optimization extension Iterate, TerraTorch reduces the expertise and time required to fine-tune or benchmark models on new Earth Observation use cases. Furthermore, TerraTorch directly integrates with GEO-Bench, allowing for systematic and reproducible benchmarking of Geospatial Foundation Models. TerraTorch is open sourced under Apache 2.0, available at https://github.com/IBM/terratorch, and can be installed via pip install terratorch.
Fine-tuning of Geospatial Foundation Models for Aboveground Biomass Estimation
Jun 28, 2024


Global vegetation structure mapping is critical for understanding the global carbon cycle and maximizing the efficacy of nature-based carbon sequestration initiatives. Moreover, vegetation structure mapping can help reduce the impacts of climate change by, for example, guiding actions to improve water security, increase biodiversity and reduce flood risk. Global satellite measurements provide an important set of observations for monitoring and managing deforestation and degradation of existing forests, natural forest regeneration, reforestation, biodiversity restoration, and the implementation of sustainable agricultural practices. In this paper, we explore the effectiveness of fine-tuning of a geospatial foundation model to estimate above-ground biomass (AGB) using space-borne data collected across different eco-regions in Brazil. The fine-tuned model architecture consisted of a Swin-B transformer as the encoder (i.e., backbone) and a single convolutional layer for the decoder head. All results were compared to a U-Net which was trained as the baseline model Experimental results of this sparse-label prediction task demonstrate that the fine-tuned geospatial foundation model with a frozen encoder has comparable performance to a U-Net trained from scratch. This is despite the fine-tuned model having 13 times less parameters requiring optimization, which saves both time and compute resources. Further, we explore the transfer-learning capabilities of the geospatial foundation models by fine-tuning on satellite imagery with sparse labels from different eco-regions in Brazil.
Foundation Models for Generalist Geospatial Artificial Intelligence
Nov 08, 2023Significant progress in the development of highly adaptable and reusable Artificial Intelligence (AI) models is expected to have a significant impact on Earth science and remote sensing. Foundation models are pre-trained on large unlabeled datasets through self-supervision, and then fine-tuned for various downstream tasks with small labeled datasets. This paper introduces a first-of-a-kind framework for the efficient pre-training and fine-tuning of foundational models on extensive geospatial data. We have utilized this framework to create Prithvi, a transformer-based geospatial foundational model pre-trained on more than 1TB of multispectral satellite imagery from the Harmonized Landsat-Sentinel 2 (HLS) dataset. Our study demonstrates the efficacy of our framework in successfully fine-tuning Prithvi to a range of Earth observation tasks that have not been tackled by previous work on foundation models involving multi-temporal cloud gap imputation, flood mapping, wildfire scar segmentation, and multi-temporal crop segmentation. Our experiments show that the pre-trained model accelerates the fine-tuning process compared to leveraging randomly initialized weights. In addition, pre-trained Prithvi compares well against the state-of-the-art, e.g., outperforming a conditional GAN model in multi-temporal cloud imputation by up to 5pp (or 5.7%) in the structural similarity index. Finally, due to the limited availability of labeled data in the field of Earth observation, we gradually reduce the quantity of available labeled data for refining the model to evaluate data efficiency and demonstrate that data can be decreased significantly without affecting the model's accuracy. The pre-trained 100 million parameter model and corresponding fine-tuning workflows have been released publicly as open source contributions to the global Earth sciences community through Hugging Face.
TensorBank:Tensor Lakehouse for Foundation Model Training
Sep 07, 2023



Storing and streaming high dimensional data for foundation model training became a critical requirement with the rise of foundation models beyond natural language. In this paper we introduce TensorBank, a petabyte scale tensor lakehouse capable of streaming tensors from Cloud Object Store (COS) to GPU memory at wire speed based on complex relational queries. We use Hierarchical Statistical Indices (HSI) for query acceleration. Our architecture allows to directly address tensors on block level using HTTP range reads. Once in GPU memory, data can be transformed using PyTorch transforms. We provide a generic PyTorch dataset type with a corresponding dataset factory translating relational queries and requested transformations as an instance. By making use of the HSI, irrelevant blocks can be skipped without reading them as those indices contain statistics on their content at different hierarchical resolution levels. This is an opinionated architecture powered by open standards and making heavy use of open-source technology. Although, hardened for production use using geospatial-temporal data, this architecture generalizes to other use case like computer vision, computational neuroscience, biological sequence analysis and more.