 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Underwater Light Field Images via Global Geometry-aware Diffusion Process
Jan 29, 2026This work studies the challenging problem of acquiring high-quality underwater images via 4-D light field (LF) imaging. To this end, we propose GeoDiff-LF, a novel diffusion-based framework built upon SD-Turbo to enhance underwater 4-D LF imaging by leveraging its spatial-angular structure. GeoDiff-LF consists of three key adaptations: (1) a modified U-Net architecture with convolutional and attention adapters to model geometric cues, (2) a geometry-guided loss function using tensor decomposition and progressive weighting to regularize global structure, and (3) an optimized sampling strategy with noise prediction to improve efficiency. By integrating diffusion priors and LF geometry, GeoDiff-LF effectively mitigates color distortion in underwater scenes. Extensive experiments demonstrate that our framework outperforms existing methods across both visual fidelity and quantitative performance, advancing the state-of-the-art in enhancing underwater imaging. The code will be publicly available at https://github.com/linlos1234/GeoDiff-LF.
SeedVR2: One-Step Video Restoration via Diffusion Adversarial Post-Training
Jun 05, 2025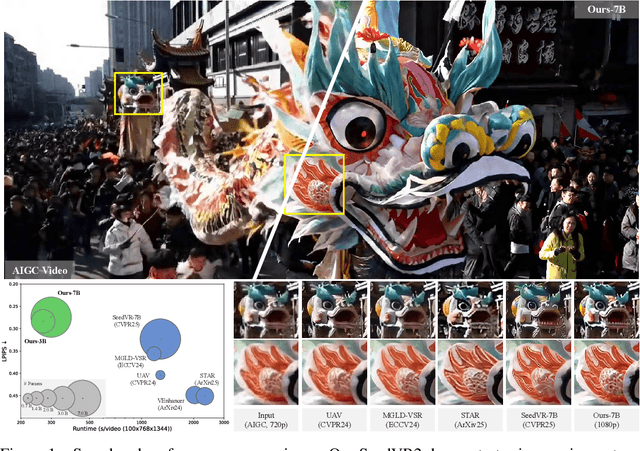
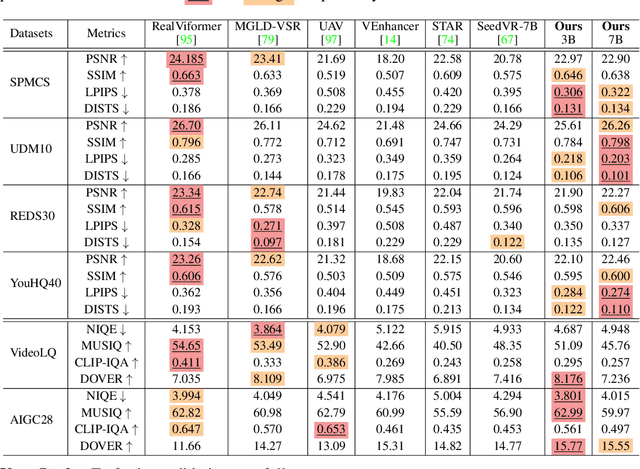
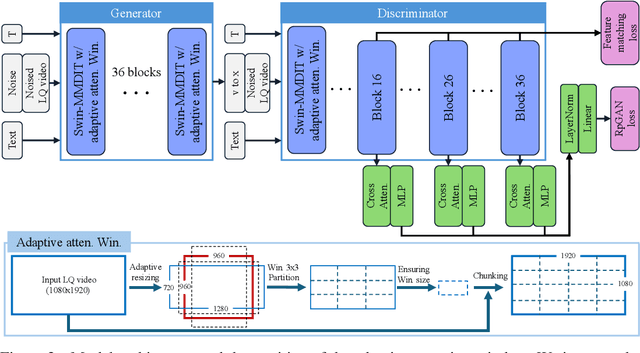
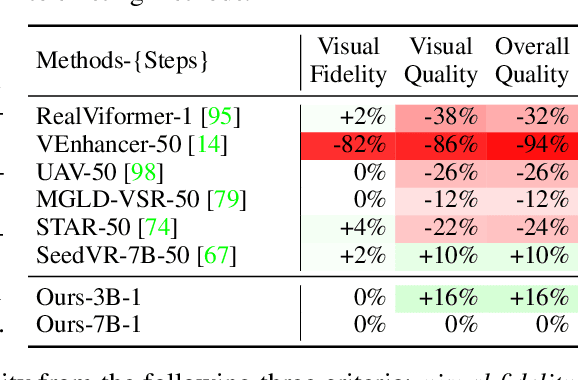
Recent advances in diffusion-based video restoration (VR) demonstrate significant improvement in visual quality, yet yield a prohibitive computational cost during inference. While several distillation-based approaches have exhibited the potential of one-step image restoration, extending existing approaches to VR remains challenging and underexplored, particularly when dealing with high-resolution video in real-world settings. In this work, we propose a one-step diffusion-based VR model, termed as SeedVR2, which performs adversarial VR training against real data. To handle the challenging high-resolution VR within a single step, we introduce several enhancements to both model architecture and training procedures. Specifically, an adaptive window attention mechanism is proposed, where the window size is dynamically adjusted to fit the output resolutions, avoiding window inconsistency observed under high-resolution VR using window attention with a predefined window size. To stabilize and improve the adversarial post-training towards VR, we further verify the effectiveness of a series of losses, including a proposed feature matching loss without significantly sacrificing training efficiency. Extensive experiments show that SeedVR2 can achieve comparable or even better performance compared with existing VR approaches in a single step.
Arbitrary-steps Image Super-resolution via Diffusion Inversion
Dec 12, 2024



This study presents a new image super-resolution (SR) technique based on diffusion inversion, aiming at harnessing the rich image priors encapsulated in large pre-trained diffusion models to improve SR performance. We design a Partial noise Prediction strategy to construct an intermediate state of the diffusion model, which serves as the starting sampling point. Central to our approach is a deep noise predictor to estimate the optimal noise maps for the forward diffusion process. Once trained, this noise predictor can be used to initialize the sampling process partially along the diffusion trajectory, generating the desirable high-resolution result. Compared to existing approaches, our method offers a flexible and efficient sampling mechanism that supports an arbitrary number of sampling steps, ranging from one to five. Even with a single sampling step, our method demonstrates superior or comparable performance to recent state-of-the-art approaches. The code and model are publicly available at https://github.com/zsyOAOA/InvSR.
Omegance: A Single Parameter for Various Granularities in Diffusion-Based Synthesis
Nov 26, 2024



In this work, we introduce a single parameter $\omega$, to effectively control granularity in diffusion-based synthesis. This parameter is incorporated during the denoising steps of the diffusion model's reverse process. Our approach does not require model retraining, architectural modifications, or additional computational overhead during inference, yet enables precise control over the level of details in the generated outputs. Moreover, spatial masks or denoising schedules with varying $\omega$ values can be applied to achieve region-specific or timestep-specific granularity control. Prior knowledge of image composition from control signals or reference images further facilitates the creation of precise $\omega$ masks for granularity control on specific objects. To highlight the parameter's role in controlling subtle detail variations, the technique is named Omegance, combining "omega" and "nuance". Our method demonstrates impressive performance across various image and video synthesis tasks and is adaptable to advanced diffusion models. The code is available at https://github.com/itsmag11/Omegance.
Degradation-Guided One-Step Image Super-Resolution with Diffusion Priors
Sep 25, 2024



Diffusion-based image super-resolution (SR) methods have achieved remarkable success by leveraging large pre-trained text-to-image diffusion models as priors. However, these methods still face two challenges: the requirement for dozens of sampling steps to achieve satisfactory results, which limits efficiency in real scenarios, and the neglect of degradation models, which are critical auxiliary information in solving the SR problem. In this work, we introduced a novel one-step SR model, which significantly addresses the efficiency issue of diffusion-based SR methods. Unlike existing fine-tuning strategies, we designed a degradation-guided Low-Rank Adaptation (LoRA) module specifically for SR, which corrects the model parameters based on the pre-estimated degradation information from low-resolution images. This module not only facilitates a powerful data-dependent or degradation-dependent SR model but also preserves the generative prior of the pre-trained diffusion model as much as possible. Furthermore, we tailor a novel training pipeline by introducing an online negative sample generation strategy. Combined with the classifier-free guidance strategy during inference, it largely improves the perceptual quality of the super-resolution results. Extensive experiments have demonstrated the superior efficiency and effectiveness of the proposed model compared to recent state-of-the-art methods.
Blind Image Deconvolution by Generative-based Kernel Prior and Initializer via Latent Encoding
Jul 20, 2024



Blind image deconvolution (BID) is a classic yet challenging problem in the field of image processing. Recent advances in deep image prior (DIP) have motivated a series of DIP-based approaches, demonstrating remarkable success in BID. However, due to the high non-convexity of the inherent optimization process, these methods are notorious for their sensitivity to the initialized kernel. To alleviate this issue and further improve their performance, we propose a new framework for BID that better considers the prior modeling and the initialization for blur kernels, leveraging a deep generative model. The proposed approach pre-trains a generative adversarial network-based kernel generator that aptly characterizes the kernel priors and a kernel initializer that facilitates a well-informed initialization for the blur kernel through latent space encoding. With the pre-trained kernel generator and initializer, one can obtain a high-quality initialization of the blur kernel, and enable optimization within a compact latent kernel manifold. Such a framework results in an evident performance improvement over existing DIP-based BID methods. Extensive experiments on different datasets demonstrate the effectiveness of the proposed method.
Denoising as Adaptation: Noise-Space Domain Adaptation for Image Restoration
Jun 26, 2024



Although deep learning-based image restoration methods have made significant progress, they still struggle with limited generalization to real-world scenarios due to the substantial domain gap caused by training on synthetic data. Existing methods address this issue by improving data synthesis pipelines, estimating degradation kernels, employing deep internal learning, and performing domain adaptation and regularization. Previous domain adaptation methods have sought to bridge the domain gap by learning domain-invariant knowledge in either feature or pixel space. However, these techniques often struggle to extend to low-level vision tasks within a stable and compact framework. In this paper, we show that it is possible to perform domain adaptation via the noise-space using diffusion models. In particular, by leveraging the unique property of how the multi-step denoising process is influenced by auxiliary conditional inputs, we obtain meaningful gradients from noise prediction to gradually align the restored results of both synthetic and real-world data to a common clean distribution. We refer to this method as denoising as adaptation. To prevent shortcuts during training, we present useful techniques such as channel shuffling and residual-swapping contrastive learning. Experimental results on three classical image restoration tasks, namely denoising, deblurring, and deraining, demonstrate the effectiveness of the proposed method. Code will be released at: https://github.com/KangLiao929/Noise-DA/.
MIPI 2024 Challenge on Few-shot RAW Image Denoising: Methods and Results
Jun 11, 2024



The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Few-shot RAW Image Denoising track on MIPI 2024. In total, 165 participants were successfully registered, and 7 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art erformance on Few-shot RAW Image Denoising. More details of this challenge and the link to the dataset can be found at https://mipichallenge.org/MIPI2024.
MIPI 2024 Challenge on Demosaic for HybridEVS Camera: Methods and Results
May 08, 2024



The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.
MIPI 2024 Challenge on Nighttime Flare Removal: Methods and Results
Apr 30, 2024



The increasing demand for computational photography and imaging on mobile platforms has led to the widespread development and integration of advanced image sensors with novel algorithms in camera systems. However, the scarcity of high-quality data for research and the rare opportunity for in-depth exchange of views from industry and academia constrain the development of mobile intelligent photography and imaging (MIPI). Building on the achievements of the previous MIPI Workshops held at ECCV 2022 and CVPR 2023, we introduce our third MIPI challenge including three tracks focusing on novel image sensors and imaging algorithms. In this paper, we summarize and review the Nighttime Flare Removal track on MIPI 2024. In total, 170 participants were successfully registered, and 14 teams submitted results in the final testing phase. The developed solutions in this challenge achieved state-of-the-art performance on Nighttime Flare Removal. More details of this challenge and the link to the dataset can be found at https://mipi-challenge.org/MIPI2024/.