 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Vector Prompt Interfaces Should Be Exposed to Enable Customization of Large Language Models
Mar 04, 2026As large language models (LLMs) transition from research prototypes to real-world systems, customization has emerged as a central bottleneck. While text prompts can already customize LLM behavior, we argue that text-only prompting does not constitute a suitable control interface for scalable, stable, and inference-only customization. This position paper argues that model providers should expose \emph{vector prompt inputs} as part of the public interface for customizing LLMs. We support this position with diagnostic evidence showing that vector prompt tuning continues to improve with increasing supervision whereas text-based prompt optimization saturates early, and that vector prompts exhibit dense, global attention patterns indicative of a distinct control mechanism. We further discuss why inference-only customization is increasingly important under realistic deployment constraints, and why exposing vector prompts need not fundamentally increase model leakage risk under a standard black-box threat model. We conclude with a call to action for the community to rethink prompt interfaces as a core component of LLM customization.
AudioCapBench: Quick Evaluation on Audio Captioning across Sound, Music, and Speech
Feb 27, 2026We introduce AudioCapBench, a benchmark for evaluating audio captioning capabilities of large multimodal models. \method covers three distinct audio domains, including environmental sound, music, and speech, with 1,000 curated evaluation samples drawn from established datasets. We evaluate 13 models across two providers (OpenAI, Google Gemini) using both reference-based metrics (METEOR, BLEU, ROUGE-L) and an LLM-as-Judge framework that scores predictions on three orthogonal dimensions: \textit{accuracy} (semantic correctness), \textit{completeness} (coverage of reference content), and \textit{hallucination} (absence of fabricated content). Our results reveal that Gemini models generally outperform OpenAI models on overall captioning quality, with Gemini~3~Pro achieving the highest overall score (6.00/10), while OpenAI models exhibit lower hallucination rates. All models perform best on speech captioning and worst on music captioning. We release the benchmark as well as evaluation code to facilitate reproducible audio understanding research.
Group Representational Position Encoding
Dec 08, 2025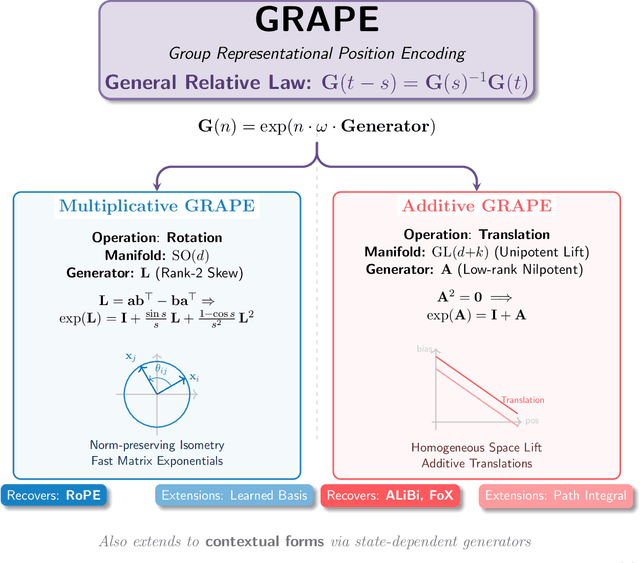
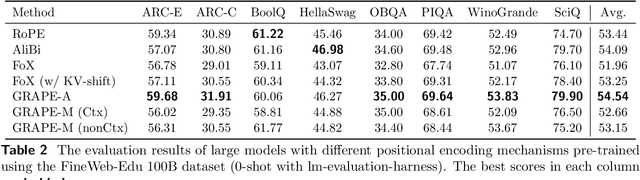
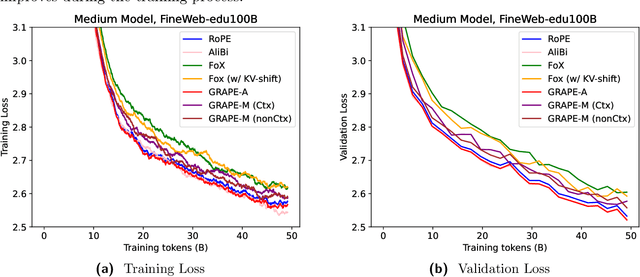

We present GRAPE (Group RepresentAtional Position Encoding), a unified framework for positional encoding based on group actions. GRAPE brings together two families of mechanisms: (i) multiplicative rotations (Multiplicative GRAPE) in $\mathrm{SO}(d)$ and (ii) additive logit biases (Additive GRAPE) arising from unipotent actions in the general linear group $\mathrm{GL}$. In Multiplicative GRAPE, a position $n \in \mathbb{Z}$ (or $t \in \mathbb{R}$) acts as $\mathbf{G}(n)=\exp(n\,ω\,\mathbf{L})$ with a rank-2 skew generator $\mathbf{L} \in \mathbb{R}^{d \times d}$, yielding a relative, compositional, norm-preserving map with a closed-form matrix exponential. RoPE is recovered exactly when the $d/2$ planes are the canonical coordinate pairs with log-uniform spectrum. Learned commuting subspaces and compact non-commuting mixtures strictly extend this geometry to capture cross-subspace feature coupling at $O(d)$ and $O(r d)$ cost per head, respectively. In Additive GRAPE, additive logits arise as rank-1 (or low-rank) unipotent actions, recovering ALiBi and the Forgetting Transformer (FoX) as exact special cases while preserving an exact relative law and streaming cacheability. Altogether, GRAPE supplies a principled design space for positional geometry in long-context models, subsuming RoPE and ALiBi as special cases. Project Page: https://github.com/model-architectures/GRAPE.
LoCoBench-Agent: An Interactive Benchmark for LLM Agents in Long-Context Software Engineering
Nov 17, 2025



As large language models (LLMs) evolve into sophisticated autonomous agents capable of complex software development tasks, evaluating their real-world capabilities becomes critical. While existing benchmarks like LoCoBench~\cite{qiu2025locobench} assess long-context code understanding, they focus on single-turn evaluation and cannot capture the multi-turn interactive nature, tool usage patterns, and adaptive reasoning required by real-world coding agents. We introduce \textbf{LoCoBench-Agent}, a comprehensive evaluation framework specifically designed to assess LLM agents in realistic, long-context software engineering workflows. Our framework extends LoCoBench's 8,000 scenarios into interactive agent environments, enabling systematic evaluation of multi-turn conversations, tool usage efficiency, error recovery, and architectural consistency across extended development sessions. We also introduce an evaluation methodology with 9 metrics across comprehension and efficiency dimensions. Our framework provides agents with 8 specialized tools (file operations, search, code analysis) and evaluates them across context lengths ranging from 10K to 1M tokens, enabling precise assessment of long-context performance. Through systematic evaluation of state-of-the-art models, we reveal several key findings: (1) agents exhibit remarkable long-context robustness; (2) comprehension-efficiency trade-off exists with negative correlation, where thorough exploration increases comprehension but reduces efficiency; and (3) conversation efficiency varies dramatically across models, with strategic tool usage patterns differentiating high-performing agents. As the first long-context LLM agent benchmark for software engineering, LoCoBench-Agent establishes a rigorous foundation for measuring agent capabilities, identifying performance gaps, and advancing autonomous software development at scale.
Global Convergence and Rich Feature Learning in $L$-Layer Infinite-Width Neural Networks under $μ$P Parametrization
Mar 12, 2025



Despite deep neural networks' powerful representation learning capabilities, theoretical understanding of how networks can simultaneously achieve meaningful feature learning and global convergence remains elusive. Existing approaches like the neural tangent kernel (NTK) are limited because features stay close to their initialization in this parametrization, leaving open questions about feature properties during substantial evolution. In this paper, we investigate the training dynamics of infinitely wide, $L$-layer neural networks using the tensor program (TP) framework. Specifically, we show that, when trained with stochastic gradient descent (SGD) under the Maximal Update parametrization ($\mu$P) and mild conditions on the activation function, SGD enables these networks to learn linearly independent features that substantially deviate from their initial values. This rich feature space captures relevant data information and ensures that any convergent point of the training process is a global minimum. Our analysis leverages both the interactions among features across layers and the properties of Gaussian random variables, providing new insights into deep representation learning. We further validate our theoretical findings through experiments on real-world datasets.
Convergence of Score-Based Discrete Diffusion Models: A Discrete-Time Analysis
Oct 03, 2024

Diffusion models have achieved great success in generating high-dimensional samples across various applications. While the theoretical guarantees for continuous-state diffusion models have been extensively studied, the convergence analysis of the discrete-state counterparts remains under-explored. In this paper, we study the theoretical aspects of score-based discrete diffusion models under the Continuous Time Markov Chain (CTMC) framework. We introduce a discrete-time sampling algorithm in the general state space $[S]^d$ that utilizes score estimators at predefined time points. We derive convergence bounds for the Kullback-Leibler (KL) divergence and total variation (TV) distance between the generated sample distribution and the data distribution, considering both scenarios with and without early stopping under specific assumptions. Notably, our KL divergence bounds are nearly linear in dimension $d$, aligning with state-of-the-art results for diffusion models. Our convergence analysis employs a Girsanov-based method and establishes key properties of the discrete score function, which are essential for characterizing the discrete-time sampling process.
Guided Discrete Diffusion for Electronic Health Record Generation
Apr 18, 2024



Electronic health records (EHRs) are a pivotal data source that enables numerous applications in computational medicine, e.g., disease progression prediction, clinical trial design, and health economics and outcomes research. Despite wide usability, their sensitive nature raises privacy and confidentially concerns, which limit potential use cases. To tackle these challenges, we explore the use of generative models to synthesize artificial, yet realistic EHRs. While diffusion-based methods have recently demonstrated state-of-the-art performance in generating other data modalities and overcome the training instability and mode collapse issues that plague previous GAN-based approaches, their applications in EHR generation remain underexplored. The discrete nature of tabular medical code data in EHRs poses challenges for high-quality data generation, especially for continuous diffusion models. To this end, we introduce a novel tabular EHR generation method, EHR-D3PM, which enables both unconditional and conditional generation using the discrete diffusion model. Our experiments demonstrate that EHR-D3PM significantly outperforms existing generative baselines on comprehensive fidelity and utility metrics while maintaining less membership vulnerability risks. Furthermore, we show EHR-D3PM is effective as a data augmentation method and enhances performance on downstream tasks when combined with real data.
Matching the Statistical Query Lower Bound for k-sparse Parity Problems with Stochastic Gradient Descent
Apr 18, 2024



The $k$-parity problem is a classical problem in computational complexity and algorithmic theory, serving as a key benchmark for understanding computational classes. In this paper, we solve the $k$-parity problem with stochastic gradient descent (SGD) on two-layer fully-connected neural networks. We demonstrate that SGD can efficiently solve the $k$-sparse parity problem on a $d$-dimensional hypercube ($k\le O(\sqrt{d})$) with a sample complexity of $\tilde{O}(d^{k-1})$ using $2^{\Theta(k)}$ neurons, thus matching the established $\Omega(d^{k})$ lower bounds of Statistical Query (SQ) models. Our theoretical analysis begins by constructing a good neural network capable of correctly solving the $k$-parity problem. We then demonstrate how a trained neural network with SGD can effectively approximate this good network, solving the $k$-parity problem with small statistical errors. Our theoretical results and findings are supported by empirical evidence, showcasing the efficiency and efficacy of our approach.
Self-Play Fine-Tuning of Diffusion Models for Text-to-Image Generation
Feb 15, 2024



Fine-tuning Diffusion Models remains an underexplored frontier in generative artificial intelligence (GenAI), especially when compared with the remarkable progress made in fine-tuning Large Language Models (LLMs). While cutting-edge diffusion models such as Stable Diffusion (SD) and SDXL rely on supervised fine-tuning, their performance inevitably plateaus after seeing a certain volume of data. Recently, reinforcement learning (RL) has been employed to fine-tune diffusion models with human preference data, but it requires at least two images ("winner" and "loser" images) for each text prompt. In this paper, we introduce an innovative technique called self-play fine-tuning for diffusion models (SPIN-Diffusion), where the diffusion model engages in competition with its earlier versions, facilitating an iterative self-improvement process. Our approach offers an alternative to conventional supervised fine-tuning and RL strategies, significantly improving both model performance and alignment. Our experiments on the Pick-a-Pic dataset reveal that SPIN-Diffusion outperforms the existing supervised fine-tuning method in aspects of human preference alignment and visual appeal right from its first iteration. By the second iteration, it exceeds the performance of RLHF-based methods across all metrics, achieving these results with less data.
Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models
Jan 02, 2024



Harnessing the power of human-annotated data through Supervised Fine-Tuning (SFT) is pivotal for advancing Large Language Models (LLMs). In this paper, we delve into the prospect of growing a strong LLM out of a weak one without the need for acquiring additional human-annotated data. We propose a new fine-tuning method called Self-Play fIne-tuNing (SPIN), which starts from a supervised fine-tuned model. At the heart of SPIN lies a self-play mechanism, where the LLM refines its capability by playing against instances of itself. More specifically, the LLM generates its own training data from its previous iterations, refining its policy by discerning these self-generated responses from those obtained from human-annotated data. Our method progressively elevates the LLM from a nascent model to a formidable one, unlocking the full potential of human-annotated demonstration data for SFT. Theoretically, we prove that the global optimum to the training objective function of our method is achieved only when the LLM policy aligns with the target data distribution. Empirically, we evaluate our method on several benchmark datasets including the HuggingFace Open LLM Leaderboard, MT-Bench, and datasets from Big-Bench. Our results show that SPIN can significantly improve the LLM's performance across a variety of benchmarks and even outperform models trained through direct preference optimization (DPO) supplemented with extra GPT-4 preference data. This sheds light on the promise of self-play, enabling the achievement of human-level performance in LLMs without the need for expert opponents.