 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreeAdv: Tree-Structured Advantage Redistribution for Group-Based RL
Jan 07, 2026Reinforcement learning with group-based objectives, such as Group Relative Policy Optimization (GRPO), is a common framework for aligning large language models on complex reasoning tasks. However, standard GRPO treats each rollout trajectory as an independent flat sequence and assigns a single sequence-level advantage to all tokens, which leads to sample inefficiency and a length bias toward verbose, redundant chains of thought without improving logical depth. We introduce TreeAdv (Tree-Structured Advantage Redistribution for Group-Based RL), which makes the tree structure of group rollouts explicit for both exploration and advantage assignment. Specifically, TreeAdv builds a group of trees (a forest) based on an entropy-driven sampling method where each tree branches at high-uncertainty decisions while sharing low-uncertainty tokens across rollouts. Then, TreeAdv aggregates token-level advantages for internal tree segments by redistributing the advantages of complete rollouts (all leaf nodes), and TreeAdv can easily apply to group-based objectives such as GRPO or GSPO. Across 10 math reasoning benchmarks, TreeAdv consistently outperforms GRPO and GSPO, while using substantially fewer generated tokens under identical supervision, data, and decoding budgets.
Is PRM Necessary? Problem-Solving RL Implicitly Induces PRM Capability in LLMs
May 16, 2025The development of reasoning capabilities represents a critical frontier in large language models (LLMs) research, where reinforcement learning (RL) and process reward models (PRMs) have emerged as predominant methodological frameworks. Contrary to conventional wisdom, empirical evidence from DeepSeek-R1 demonstrates that pure RL training focused on mathematical problem-solving can progressively enhance reasoning abilities without PRM integration, challenging the perceived necessity of process supervision. In this study, we conduct a systematic investigation of the relationship between RL training and PRM capabilities. Our findings demonstrate that problem-solving proficiency and process supervision capabilities represent complementary dimensions of reasoning that co-evolve synergistically during pure RL training. In particular, current PRMs underperform simple baselines like majority voting when applied to state-of-the-art models such as DeepSeek-R1 and QwQ-32B. To address this limitation, we propose Self-PRM, an introspective framework in which models autonomously evaluate and rerank their generated solutions through self-reward mechanisms. Although Self-PRM consistently improves the accuracy of the benchmark (particularly with larger sample sizes), analysis exposes persistent challenges: The approach exhibits low precision (<10\%) on difficult problems, frequently misclassifying flawed solutions as valid. These analyses underscore the need for continued RL scaling to improve reward alignment and introspective accuracy. Overall, our findings suggest that PRM may not be essential for enhancing complex reasoning, as pure RL not only improves problem-solving skills but also inherently fosters robust PRM capabilities. We hope these findings provide actionable insights for building more reliable and self-aware complex reasoning models.
Guided Discrete Diffusion for Electronic Health Record Generation
Apr 18, 2024



Electronic health records (EHRs) are a pivotal data source that enables numerous applications in computational medicine, e.g., disease progression prediction, clinical trial design, and health economics and outcomes research. Despite wide usability, their sensitive nature raises privacy and confidentially concerns, which limit potential use cases. To tackle these challenges, we explore the use of generative models to synthesize artificial, yet realistic EHRs. While diffusion-based methods have recently demonstrated state-of-the-art performance in generating other data modalities and overcome the training instability and mode collapse issues that plague previous GAN-based approaches, their applications in EHR generation remain underexplored. The discrete nature of tabular medical code data in EHRs poses challenges for high-quality data generation, especially for continuous diffusion models. To this end, we introduce a novel tabular EHR generation method, EHR-D3PM, which enables both unconditional and conditional generation using the discrete diffusion model. Our experiments demonstrate that EHR-D3PM significantly outperforms existing generative baselines on comprehensive fidelity and utility metrics while maintaining less membership vulnerability risks. Furthermore, we show EHR-D3PM is effective as a data augmentation method and enhances performance on downstream tasks when combined with real data.
Fast Sampling via De-randomization for Discrete Diffusion Models
Dec 14, 2023



Diffusion models have emerged as powerful tools for high-quality data generation, such as image generation. Despite its success in continuous spaces, discrete diffusion models, which apply to domains such as texts and natural languages, remain under-studied and often suffer from slow generation speed. In this paper, we propose a novel de-randomized diffusion process, which leads to an accelerated algorithm for discrete diffusion models. Our technique significantly reduces the number of function evaluations (i.e., calls to the neural network), making the sampling process much faster. Furthermore, we introduce a continuous-time (i.e., infinite-step) sampling algorithm that can provide even better sample qualities than its discrete-time (finite-step) counterpart. Extensive experiments on natural language generation and machine translation tasks demonstrate the superior performance of our method in terms of both generation speed and sample quality over existing methods for discrete diffusion models.
FHA-Kitchens: A Novel Dataset for Fine-Grained Hand Action Recognition in Kitchen Scenes
Jun 19, 2023



A typical task in the field of video understanding is hand action recognition, which has a wide range of applications. Existing works either mainly focus on full-body actions, or the defined action categories are relatively coarse-grained. In this paper, we propose FHA-Kitchens, a novel dataset of fine-grained hand actions in kitchen scenes. In particular, we focus on human hand interaction regions and perform deep excavation to further refine hand action information and interaction regions. Our FHA-Kitchens dataset consists of 2,377 video clips and 30,047 images collected from 8 different types of dishes, and all hand interaction regions in each image are labeled with high-quality fine-grained action classes and bounding boxes. We represent the action information in each hand interaction region as a triplet, resulting in a total of 878 action triplets. Based on the constructed dataset, we benchmark representative action recognition and detection models on the following three tracks: (1) supervised learning for hand interaction region and object detection, (2) supervised learning for fine-grained hand action recognition, and (3) intra- and inter-class domain generalization for hand interaction region detection. The experimental results offer compelling empirical evidence that highlights the challenges inherent in fine-grained hand action recognition, while also shedding light on potential avenues for future research, particularly in relation to pre-training strategy, model design, and domain generalization. The dataset will be released at https://github.com/tingZ123/FHA-Kitchens.
Masked Spatial-Spectral Autoencoders Are Excellent Hyperspectral Defenders
Jul 16, 2022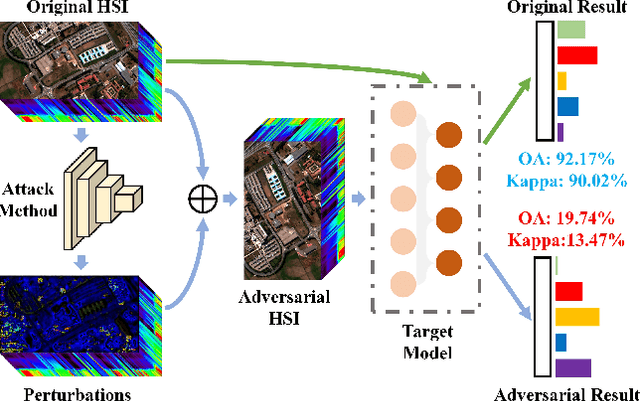
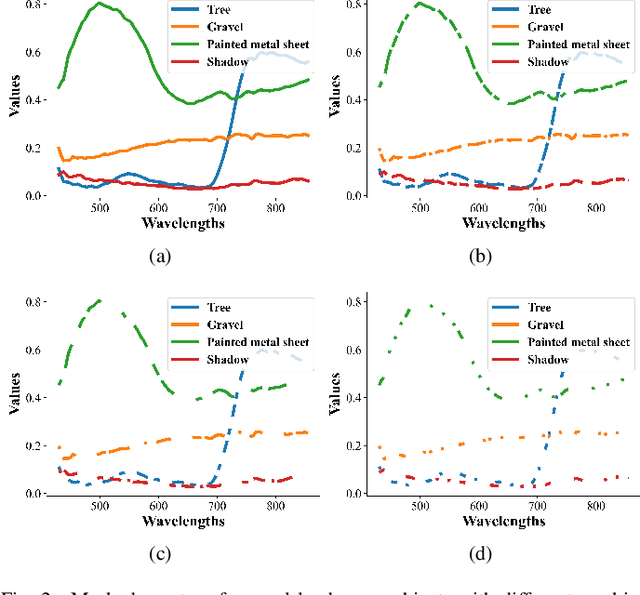

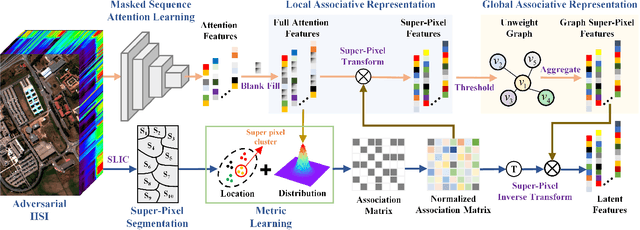
Deep learning methodology contributes a lot to the development of hyperspectral image (HSI) analysis community. However, it also makes HSI analysis systems vulnerable to adversarial attacks. To this end, we propose a masked spatial-spectral autoencoder (MSSA) in this paper under self-supervised learning theory, for enhancing the robustness of HSI analysis systems. First, a masked sequence attention learning module is conducted to promote the inherent robustness of HSI analysis systems along spectral channel. Then, we develop a graph convolutional network with learnable graph structure to establish global pixel-wise combinations.In this way, the attack effect would be dispersed by all the related pixels among each combination, and a better defense performance is achievable in spatial aspect.Finally, to improve the defense transferability and address the problem of limited labelled samples, MSSA employs spectra reconstruction as a pretext task and fits the datasets in a self-supervised manner.Comprehensive experiments over three benchmarks verify the effectiveness of MSSA in comparison with the state-of-the-art hyperspectral classification methods and representative adversarial defense strategies.