 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Group-Level Fairness Disparities in Federated Visual Language Models
May 03, 2025Visual language models (VLMs) have shown remarkable capabilities in multimodal tasks but face challenges in maintaining fairness across demographic groups, particularly when deployed in federated learning (FL) environments. This paper addresses the critical issue of group fairness in federated VLMs by introducing FVL-FP, a novel framework that combines FL with fair prompt tuning techniques. We focus on mitigating demographic biases while preserving model performance through three innovative components: (1) Cross-Layer Demographic Fair Prompting (CDFP), which adjusts potentially biased embeddings through counterfactual regularization; (2) Demographic Subspace Orthogonal Projection (DSOP), which removes demographic bias in image representations by mapping fair prompt text to group subspaces; and (3) Fair-aware Prompt Fusion (FPF), which dynamically balances client contributions based on both performance and fairness metrics. Extensive evaluations across four benchmark datasets demonstrate that our approach reduces demographic disparity by an average of 45\% compared to standard FL approaches, while maintaining task performance within 6\% of state-of-the-art results. FVL-FP effectively addresses the challenges of non-IID data distributions in federated settings and introduces minimal computational overhead while providing significant fairness benefits. Our work presents a parameter-efficient solution to the critical challenge of ensuring equitable performance across demographic groups in privacy-preserving multimodal systems.
FSBench: A Figure Skating Benchmark for Advancing Artistic Sports Understanding
Apr 28, 2025



Figure skating, known as the "Art on Ice," is among the most artistic sports, challenging to understand due to its blend of technical elements (like jumps and spins) and overall artistic expression. Existing figure skating datasets mainly focus on single tasks, such as action recognition or scoring, lacking comprehensive annotations for both technical and artistic evaluation. Current sports research is largely centered on ball games, with limited relevance to artistic sports like figure skating. To address this, we introduce FSAnno, a large-scale dataset advancing artistic sports understanding through figure skating. FSAnno includes an open-access training and test dataset, alongside a benchmark dataset, FSBench, for fair model evaluation. FSBench consists of FSBench-Text, with multiple-choice questions and explanations, and FSBench-Motion, containing multimodal data and Question and Answer (QA) pairs, supporting tasks from technical analysis to performance commentary. Initial tests on FSBench reveal significant limitations in existing models' understanding of artistic sports. We hope FSBench will become a key tool for evaluating and enhancing model comprehension of figure skating.
A detection-task-specific deep-learning method to improve the quality of sparse-view myocardial perfusion SPECT images
Apr 22, 2025Myocardial perfusion imaging (MPI) with single-photon emission computed tomography (SPECT) is a widely used and cost-effective diagnostic tool for coronary artery disease. However, the lengthy scanning time in this imaging procedure can cause patient discomfort, motion artifacts, and potentially inaccurate diagnoses due to misalignment between the SPECT scans and the CT-scans which are acquired for attenuation compensation. Reducing projection angles is a potential way to shorten scanning time, but this can adversely impact the quality of the reconstructed images. To address this issue, we propose a detection-task-specific deep-learning method for sparse-view MPI SPECT images. This method integrates an observer loss term that penalizes the loss of anthropomorphic channel features with the goal of improving performance in perfusion defect-detection task. We observed that, on the task of detecting myocardial perfusion defects, the proposed method yielded an area under the receiver operating characteristic (ROC) curve (AUC) significantly larger than the sparse-view protocol. Further, the proposed method was observed to be able to restore the structure of the left ventricle wall, demonstrating ability to overcome sparse-sampling artifacts. Our preliminary results motivate further evaluations of the method.
AU-TTT: Vision Test-Time Training model for Facial Action Unit Detection
Mar 30, 2025



Facial Action Units (AUs) detection is a cornerstone of objective facial expression analysis and a critical focus in affective computing. Despite its importance, AU detection faces significant challenges, such as the high cost of AU annotation and the limited availability of datasets. These constraints often lead to overfitting in existing methods, resulting in substantial performance degradation when applied across diverse datasets. Addressing these issues is essential for improving the reliability and generalizability of AU detection methods. Moreover, many current approaches leverage Transformers for their effectiveness in long-context modeling, but they are hindered by the quadratic complexity of self-attention. Recently, Test-Time Training (TTT) layers have emerged as a promising solution for long-sequence modeling. Additionally, TTT applies self-supervised learning for iterative updates during both training and inference, offering a potential pathway to mitigate the generalization challenges inherent in AU detection tasks. In this paper, we propose a novel vision backbone tailored for AU detection, incorporating bidirectional TTT blocks, named AU-TTT. Our approach introduces TTT Linear to the AU detection task and optimizes image scanning mechanisms for enhanced performance. Additionally, we design an AU-specific Region of Interest (RoI) scanning mechanism to capture fine-grained facial features critical for AU detection. Experimental results demonstrate that our method achieves competitive performance in both within-domain and cross-domain scenarios.
AdaMHF: Adaptive Multimodal Hierarchical Fusion for Survival Prediction
Mar 27, 2025The integration of pathologic images and genomic data for survival analysis has gained increasing attention with advances in multimodal learning. However, current methods often ignore biological characteristics, such as heterogeneity and sparsity, both within and across modalities, ultimately limiting their adaptability to clinical practice. To address these challenges, we propose AdaMHF: Adaptive Multimodal Hierarchical Fusion, a framework designed for efficient, comprehensive, and tailored feature extraction and fusion. AdaMHF is specifically adapted to the uniqueness of medical data, enabling accurate predictions with minimal resource consumption, even under challenging scenarios with missing modalities. Initially, AdaMHF employs an experts expansion and residual structure to activate specialized experts for extracting heterogeneous and sparse features. Extracted tokens undergo refinement via selection and aggregation, reducing the weight of non-dominant features while preserving comprehensive information. Subsequently, the encoded features are hierarchically fused, allowing multi-grained interactions across modalities to be captured. Furthermore, we introduce a survival prediction benchmark designed to resolve scenarios with missing modalities, mirroring real-world clinical conditions. Extensive experiments on TCGA datasets demonstrate that AdaMHF surpasses current state-of-the-art (SOTA) methods, showcasing exceptional performance in both complete and incomplete modality settings.
TC-GS: Tri-plane based compression for 3D Gaussian Splatting
Mar 26, 2025



Recently, 3D Gaussian Splatting (3DGS) has emerged as a prominent framework for novel view synthesis, providing high fidelity and rapid rendering speed. However, the substantial data volume of 3DGS and its attributes impede its practical utility, requiring compression techniques for reducing memory cost. Nevertheless, the unorganized shape of 3DGS leads to difficulties in compression. To formulate unstructured attributes into normative distribution, we propose a well-structured tri-plane to encode Gaussian attributes, leveraging the distribution of attributes for compression. To exploit the correlations among adjacent Gaussians, K-Nearest Neighbors (KNN) is used when decoding Gaussian distribution from the Tri-plane. We also introduce Gaussian position information as a prior of the position-sensitive decoder. Additionally, we incorporate an adaptive wavelet loss, aiming to focus on the high-frequency details as iterations increase. Our approach has achieved results that are comparable to or surpass that of SOTA 3D Gaussians Splatting compression work in extensive experiments across multiple datasets. The codes are released at https://github.com/timwang2001/TC-GS.
MoEdit: On Learning Quantity Perception for Multi-object Image Editing
Mar 13, 2025Multi-object images are prevalent in various real-world scenarios, including augmented reality, advertisement design, and medical imaging. Efficient and precise editing of these images is critical for these applications. With the advent of Stable Diffusion (SD), high-quality image generation and editing have entered a new era. However, existing methods often struggle to consider each object both individually and part of the whole image editing, both of which are crucial for ensuring consistent quantity perception, resulting in suboptimal perceptual performance. To address these challenges, we propose MoEdit, an auxiliary-free multi-object image editing framework. MoEdit facilitates high-quality multi-object image editing in terms of style transfer, object reinvention, and background regeneration, while ensuring consistent quantity perception between inputs and outputs, even with a large number of objects. To achieve this, we introduce the Feature Compensation (FeCom) module, which ensures the distinction and separability of each object attribute by minimizing the in-between interlacing. Additionally, we present the Quantity Attention (QTTN) module, which perceives and preserves quantity consistency by effective control in editing, without relying on auxiliary tools. By leveraging the SD model, MoEdit enables customized preservation and modification of specific concepts in inputs with high quality. Experimental results demonstrate that our MoEdit achieves State-Of-The-Art (SOTA) performance in multi-object image editing. Data and codes will be available at https://github.com/Tear-kitty/MoEdit.
BeamLLM: Vision-Empowered mmWave Beam Prediction with Large Language Models
Mar 13, 2025In this paper, we propose BeamLLM, a vision-aided millimeter-wave (mmWave) beam prediction framework leveraging large language models (LLMs) to address the challenges of high training overhead and latency in mmWave communication systems. By combining computer vision (CV) with LLMs' cross-modal reasoning capabilities, the framework extracts user equipment (UE) positional features from RGB images and aligns visual-temporal features with LLMs' semantic space through reprogramming techniques. Evaluated on a realistic vehicle-to-infrastructure (V2I) scenario, the proposed method achieves 61.01% top-1 accuracy and 97.39% top-3 accuracy in standard prediction tasks, significantly outperforming traditional deep learning models. In few-shot prediction scenarios, the performance degradation is limited to 12.56% (top-1) and 5.55% (top-3) from time sample 1 to 10, demonstrating superior prediction capability.
CardiacMamba: A Multimodal RGB-RF Fusion Framework with State Space Models for Remote Physiological Measurement
Feb 19, 2025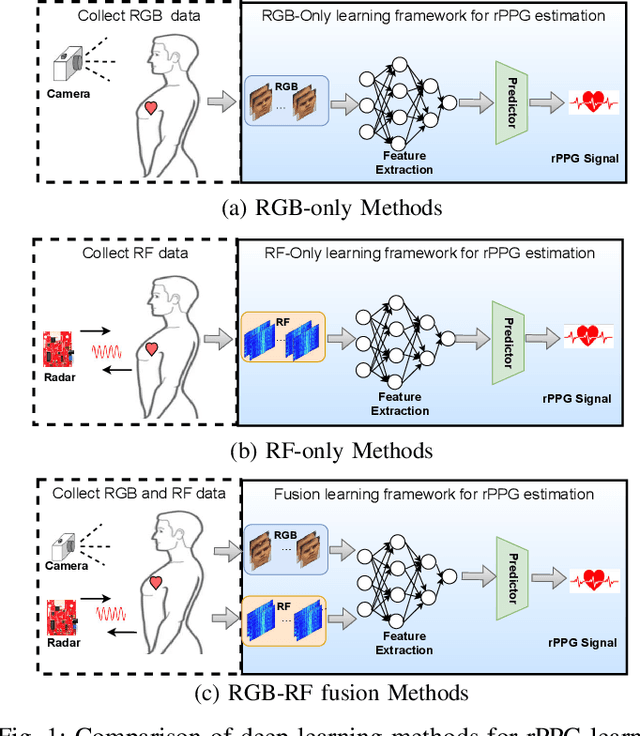
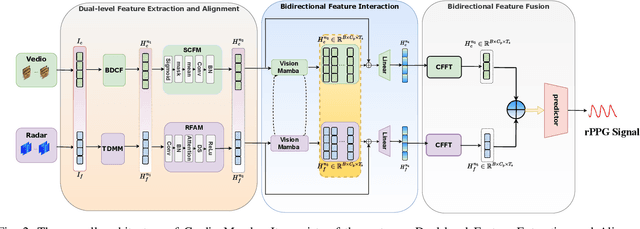
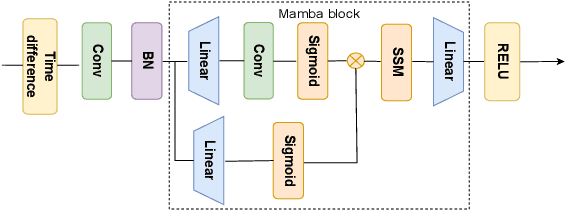
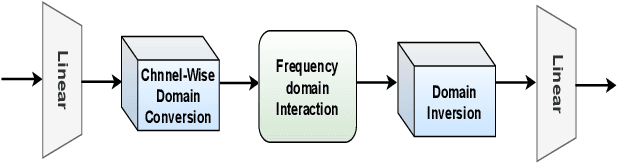
Heart rate (HR) estimation via remote photoplethysmography (rPPG) offers a non-invasive solution for health monitoring. However, traditional single-modality approaches (RGB or Radio Frequency (RF)) face challenges in balancing robustness and accuracy due to lighting variations, motion artifacts, and skin tone bias. In this paper, we propose CardiacMamba, a multimodal RGB-RF fusion framework that leverages the complementary strengths of both modalities. It introduces the Temporal Difference Mamba Module (TDMM) to capture dynamic changes in RF signals using timing differences between frames, enhancing the extraction of local and global features. Additionally, CardiacMamba employs a Bidirectional SSM for cross-modal alignment and a Channel-wise Fast Fourier Transform (CFFT) to effectively capture and refine the frequency domain characteristics of RGB and RF signals, ultimately improving heart rate estimation accuracy and periodicity detection. Extensive experiments on the EquiPleth dataset demonstrate state-of-the-art performance, achieving marked improvements in accuracy and robustness. CardiacMamba significantly mitigates skin tone bias, reducing performance disparities across demographic groups, and maintains resilience under missing-modality scenarios. By addressing critical challenges in fairness, adaptability, and precision, the framework advances rPPG technology toward reliable real-world deployment in healthcare. The codes are available at: https://github.com/WuZheng42/CardiacMamba.
Semi-rPPG: Semi-Supervised Remote Physiological Measurement with Curriculum Pseudo-Labeling
Feb 06, 2025



Remote Photoplethysmography (rPPG) is a promising technique to monitor physiological signals such as heart rate from facial videos. However, the labeled facial videos in this research are challenging to collect. Current rPPG research is mainly based on several small public datasets collected in simple environments, which limits the generalization and scale of the AI models. Semi-supervised methods that leverage a small amount of labeled data and abundant unlabeled data can fill this gap for rPPG learning. In this study, a novel semi-supervised learning method named Semi-rPPG that combines curriculum pseudo-labeling and consistency regularization is proposed to extract intrinsic physiological features from unlabelled data without impairing the model from noises. Specifically, a curriculum pseudo-labeling strategy with signal-to-noise ratio (SNR) criteria is proposed to annotate the unlabelled data while adaptively filtering out the low-quality unlabelled data. Besides, a novel consistency regularization term for quasi-periodic signals is proposed through weak and strong augmented clips. To benefit the research on semi-supervised rPPG measurement, we establish a novel semi-supervised benchmark for rPPG learning through intra-dataset and cross-dataset evaluation on four public datasets. The proposed Semi-rPPG method achieves the best results compared with three classical semi-supervised methods under different protocols. Ablation studies are conducted to prove the effectiveness of the proposed methods.