 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSBench: A Figure Skating Benchmark for Advancing Artistic Sports Understanding
Apr 28, 2025



Figure skating, known as the "Art on Ice," is among the most artistic sports, challenging to understand due to its blend of technical elements (like jumps and spins) and overall artistic expression. Existing figure skating datasets mainly focus on single tasks, such as action recognition or scoring, lacking comprehensive annotations for both technical and artistic evaluation. Current sports research is largely centered on ball games, with limited relevance to artistic sports like figure skating. To address this, we introduce FSAnno, a large-scale dataset advancing artistic sports understanding through figure skating. FSAnno includes an open-access training and test dataset, alongside a benchmark dataset, FSBench, for fair model evaluation. FSBench consists of FSBench-Text, with multiple-choice questions and explanations, and FSBench-Motion, containing multimodal data and Question and Answer (QA) pairs, supporting tasks from technical analysis to performance commentary. Initial tests on FSBench reveal significant limitations in existing models' understanding of artistic sports. We hope FSBench will become a key tool for evaluating and enhancing model comprehension of figure skating.
DEEMO: De-identity Multimodal Emotion Recognition and Reasoning
Apr 28, 2025Emotion understanding is a critical yet challenging task. Most existing approaches rely heavily on identity-sensitive information, such as facial expressions and speech, which raises concerns about personal privacy. To address this, we introduce the De-identity Multimodal Emotion Recognition and Reasoning (DEEMO), a novel task designed to enable emotion understanding using de-identified video and audio inputs. The DEEMO dataset consists of two subsets: DEEMO-NFBL, which includes rich annotations of Non-Facial Body Language (NFBL), and DEEMO-MER, an instruction dataset for Multimodal Emotion Recognition and Reasoning using identity-free cues. This design supports emotion understanding without compromising identity privacy. In addition, we propose DEEMO-LLaMA, a Multimodal Large Language Model (MLLM) that integrates de-identified audio, video, and textual information to enhance both emotion recognition and reasoning. Extensive experiments show that DEEMO-LLaMA achieves state-of-the-art performance on both tasks, outperforming existing MLLMs by a significant margin, achieving 74.49% accuracy and 74.45% F1-score in de-identity emotion recognition, and 6.20 clue overlap and 7.66 label overlap in de-identity emotion reasoning. Our work contributes to ethical AI by advancing privacy-preserving emotion understanding and promoting responsible affective computing.
EALD-MLLM: Emotion Analysis in Long-sequential and De-identity videos with Multi-modal Large Language Model
May 01, 2024Emotion AI is the ability of computers to understand human emotional states. Existing works have achieved promising progress, but two limitations remain to be solved: 1) Previous studies have been more focused on short sequential video emotion analysis while overlooking long sequential video. However, the emotions in short sequential videos only reflect instantaneous emotions, which may be deliberately guided or hidden. In contrast, long sequential videos can reveal authentic emotions; 2) Previous studies commonly utilize various signals such as facial, speech, and even sensitive biological signals (e.g., electrocardiogram). However, due to the increasing demand for privacy, developing Emotion AI without relying on sensitive signals is becoming important. To address the aforementioned limitations, in this paper, we construct a dataset for Emotion Analysis in Long-sequential and De-identity videos called EALD by collecting and processing the sequences of athletes' post-match interviews. In addition to providing annotations of the overall emotional state of each video, we also provide the Non-Facial Body Language (NFBL) annotations for each player. NFBL is an inner-driven emotional expression and can serve as an identity-free clue to understanding the emotional state. Moreover, we provide a simple but effective baseline for further research. More precisely, we evaluate the Multimodal Large Language Models (MLLMs) with de-identification signals (e.g., visual, speech, and NFBLs) to perform emotion analysis. Our experimental results demonstrate that: 1) MLLMs can achieve comparable, even better performance than the supervised single-modal models, even in a zero-shot scenario; 2) NFBL is an important cue in long sequential emotion analysis. EALD will be available on the open-source platform.
Which Facial Expressions Can Reveal Your Gender? A Study With 3D Faces
May 01, 2018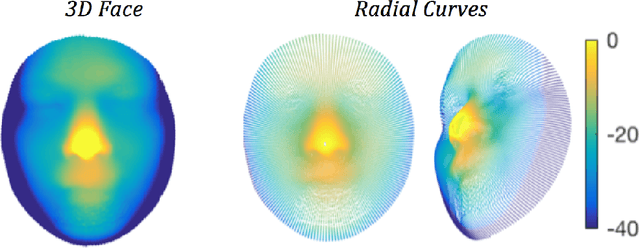
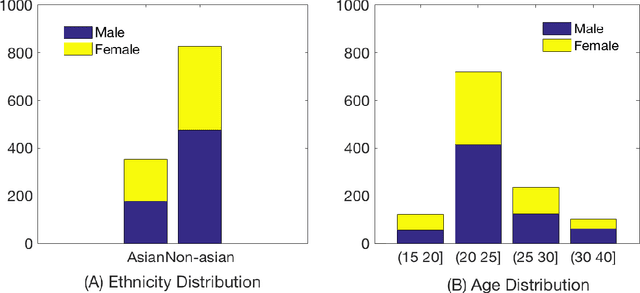
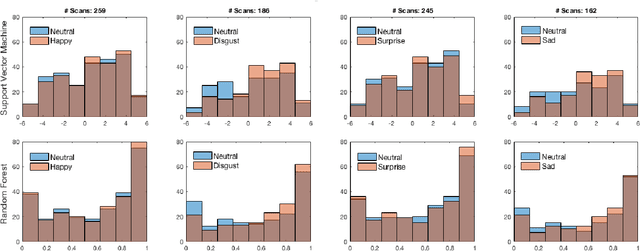
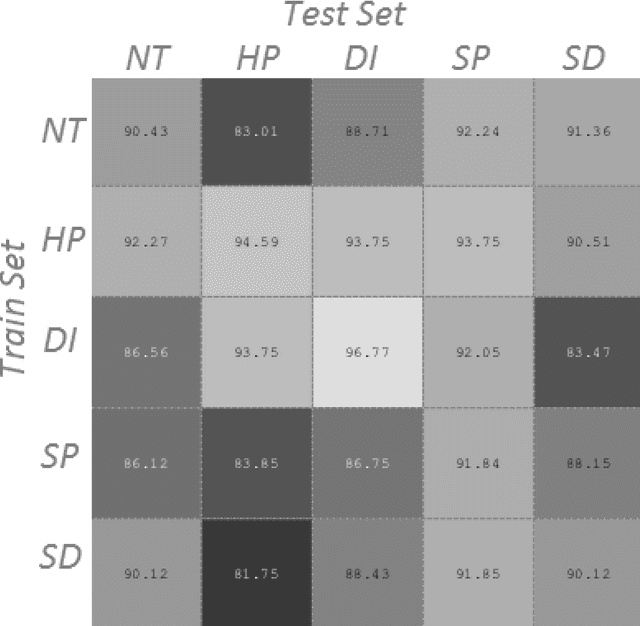
Human exhibit rich gender cues in both appearance and behavior. In computer vision domain, gender recognition from facial appearance have been extensively studied, while facial behavior based gender recognition studies remain rare. In this work, we first demonstrate that facial expressions influence the gender patterns presented in 3D face, and gender recognition performance increases when training and testing within the same expression. In further, we design experiments which directly extract the morphological changes resulted from facial expressions as features, for expression-based gender recognition. Experimental results demonstrate that gender can be recognized with considerable accuracy in Happy and Disgust expressions, while Surprise and Sad expressions do not convey much gender related information. This is the first work in the literature which investigates expression-based gender classification with 3D faces, and reveals the strength of gender patterns incorporated in different types of expressions, namely the Happy, the Disgust, the Surprise and the Sad expressions.