 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMere Contrastive Learning for Cross-Domain Sentiment Analysis
Aug 18, 2022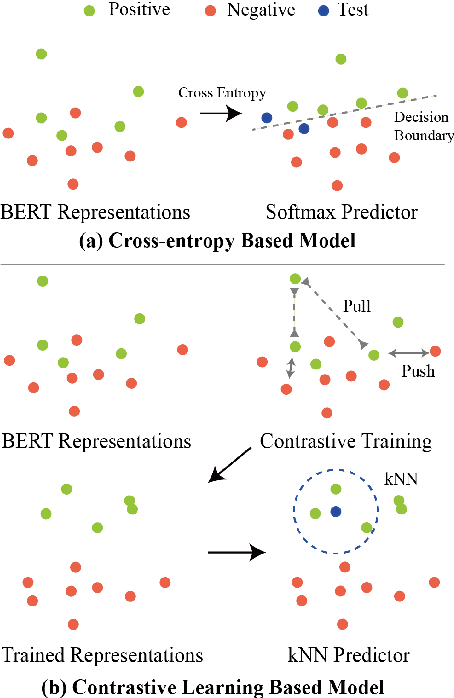
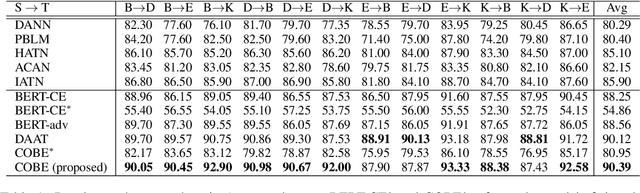
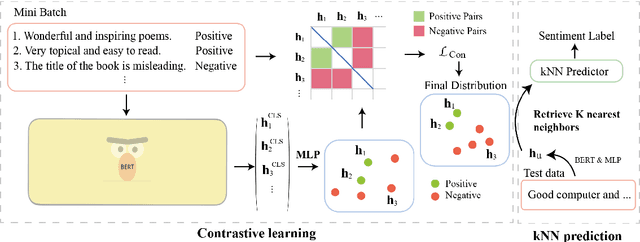
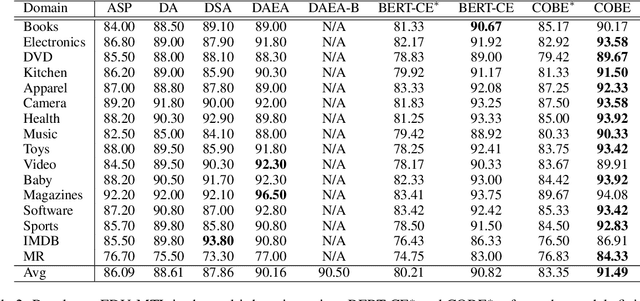
Cross-domain sentiment analysis aims to predict the sentiment of texts in the target domain using the model trained on the source domain to cope with the scarcity of labeled data. Previous studies are mostly cross-entropy-based methods for the task, which suffer from instability and poor generalization. In this paper, we explore contrastive learning on the cross-domain sentiment analysis task. We propose a modified contrastive objective with in-batch negative samples so that the sentence representations from the same class will be pushed close while those from the different classes become further apart in the latent space. Experiments on two widely used datasets show that our model can achieve state-of-the-art performance in both cross-domain and multi-domain sentiment analysis tasks. Meanwhile, visualizations demonstrate the effectiveness of transferring knowledge learned in the source domain to the target domain and the adversarial test verifies the robustness of our model.
Are Gradients on Graph Structure Reliable in Gray-box Attacks?
Aug 07, 2022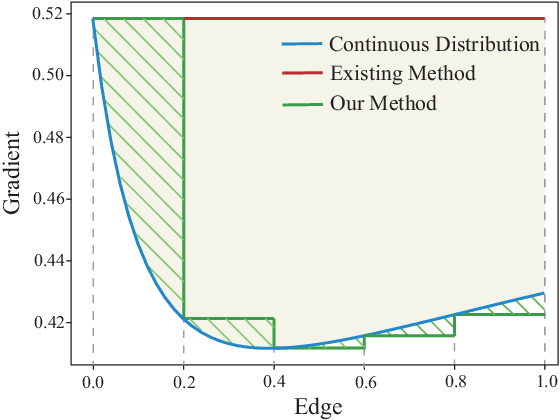
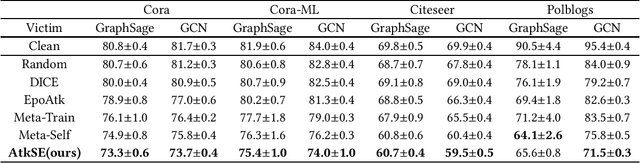
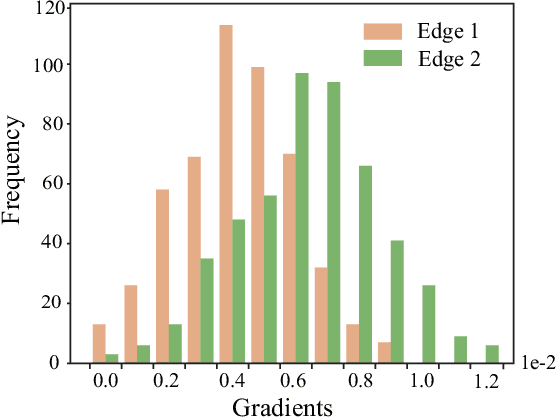

Graph edge perturbations are dedicated to damaging the prediction of graph neural networks by modifying the graph structure. Previous gray-box attackers employ gradients from the surrogate model to locate the vulnerable edges to perturb the graph structure. However, unreliability exists in gradients on graph structures, which is rarely studied by previous works. In this paper, we discuss and analyze the errors caused by the unreliability of the structural gradients. These errors arise from rough gradient usage due to the discreteness of the graph structure and from the unreliability in the meta-gradient on the graph structure. In order to address these problems, we propose a novel attack model with methods to reduce the errors inside the structural gradients. We propose edge discrete sampling to select the edge perturbations associated with hierarchical candidate selection to ensure computational efficiency. In addition, semantic invariance and momentum gradient ensemble are proposed to address the gradient fluctuation on semantic-augmented graphs and the instability of the surrogate model. Experiments are conducted in untargeted gray-box poisoning scenarios and demonstrate the improvement in the performance of our approach.
Learning the Evolutionary and Multi-scale Graph Structure for Multivariate Time Series Forecasting
Jun 28, 2022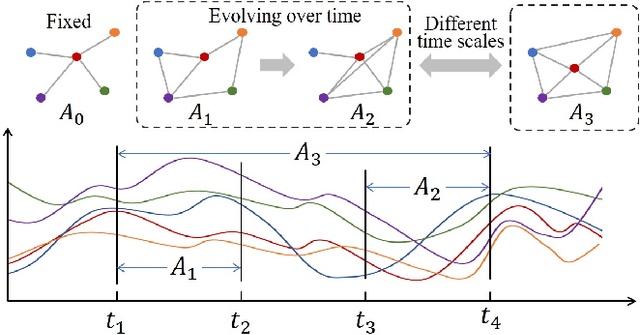

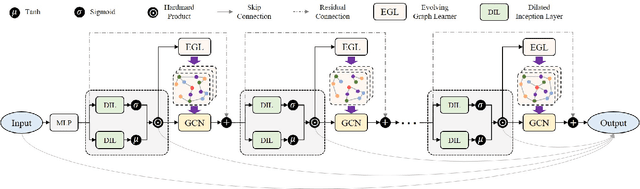
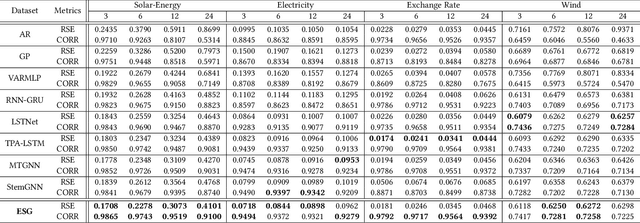
Recent studies have shown great promise in applying graph neural networks for multivariate time series forecasting, where the interactions of time series are described as a graph structure and the variables are represented as the graph nodes. Along this line, existing methods usually assume that the graph structure (or the adjacency matrix), which determines the aggregation manner of graph neural network, is fixed either by definition or self-learning. However, the interactions of variables can be dynamic and evolutionary in real-world scenarios. Furthermore, the interactions of time series are quite different if they are observed at different time scales. To equip the graph neural network with a flexible and practical graph structure, in this paper, we investigate how to model the evolutionary and multi-scale interactions of time series. In particular, we first provide a hierarchical graph structure cooperated with the dilated convolution to capture the scale-specific correlations among time series. Then, a series of adjacency matrices are constructed under a recurrent manner to represent the evolving correlations at each layer. Moreover, a unified neural network is provided to integrate the components above to get the final prediction. In this way, we can capture the pair-wise correlations and temporal dependency simultaneously. Finally, experiments on both single-step and multi-step forecasting tasks demonstrate the superiority of our method over the state-of-the-art approaches.
SNP2Vec: Scalable Self-Supervised Pre-Training for Genome-Wide Association Study
Apr 14, 2022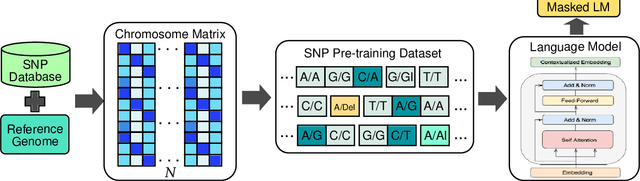
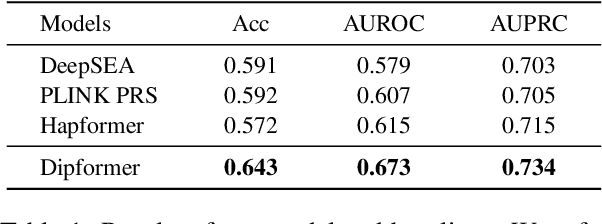
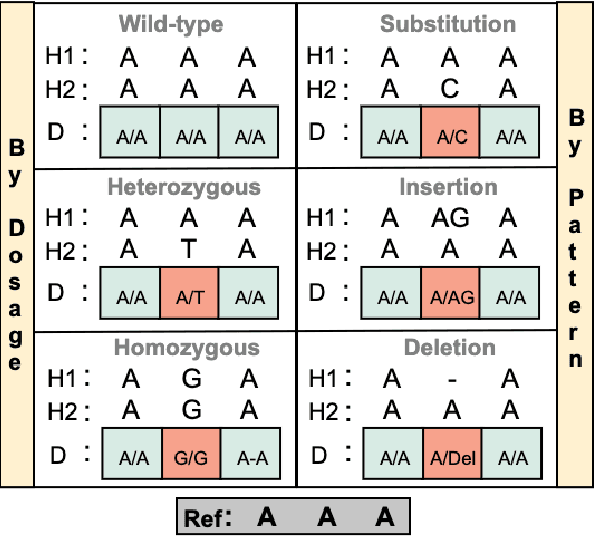

Self-supervised pre-training methods have brought remarkable breakthroughs in the understanding of text, image, and speech. Recent developments in genomics has also adopted these pre-training methods for genome understanding. However, they focus only on understanding haploid sequences, which hinders their applicability towards understanding genetic variations, also known as single nucleotide polymorphisms (SNPs), which is crucial for genome-wide association study. In this paper, we introduce SNP2Vec, a scalable self-supervised pre-training approach for understanding SNP. We apply SNP2Vec to perform long-sequence genomics modeling, and we evaluate the effectiveness of our approach on predicting Alzheimer's disease risk in a Chinese cohort. Our approach significantly outperforms existing polygenic risk score methods and all other baselines, including the model that is trained entirely with haploid sequences. We release our code and dataset on https://github.com/HLTCHKUST/snp2vec.
Multi-Stage Prompting for Knowledgeable Dialogue Generation
Mar 16, 2022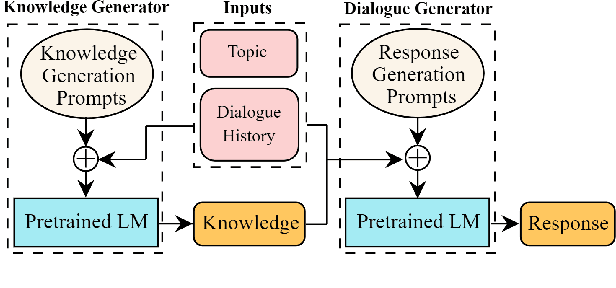
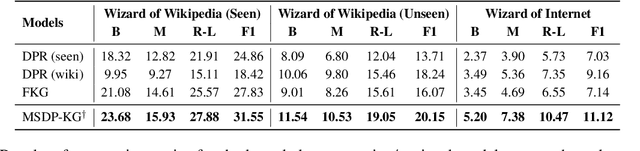
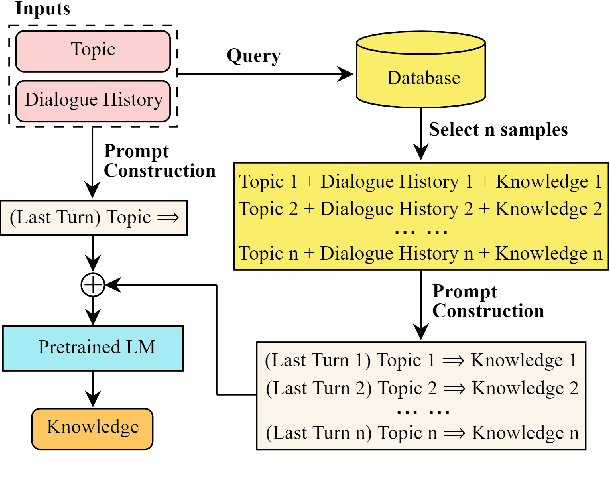

Existing knowledge-grounded dialogue systems typically use finetuned versions of a pretrained language model (LM) and large-scale knowledge bases. These models typically fail to generalize on topics outside of the knowledge base, and require maintaining separate potentially large checkpoints each time finetuning is needed. In this paper, we aim to address these limitations by leveraging the inherent knowledge stored in the pretrained LM as well as its powerful generation ability. We propose a multi-stage prompting approach to generate knowledgeable responses from a single pretrained LM. We first prompt the LM to generate knowledge based on the dialogue context. Then, we further prompt it to generate responses based on the dialogue context and the previously generated knowledge. Results show that our knowledge generator outperforms the state-of-the-art retrieval-based model by 5.8% when combining knowledge relevance and correctness. In addition, our multi-stage prompting outperforms the finetuning-based dialogue model in terms of response knowledgeability and engagement by up to 10% and 5%, respectively. Furthermore, we scale our model up to 530 billion parameters and show that larger LMs improve the generation correctness score by up to 10%, and response relevance, knowledgeability and engagement by up to 10%. Our code is available at: https://github.com/NVIDIA/Megatron-LM.
ASCEND: A Spontaneous Chinese-English Dataset for Code-switching in Multi-turn Conversation
Jan 07, 2022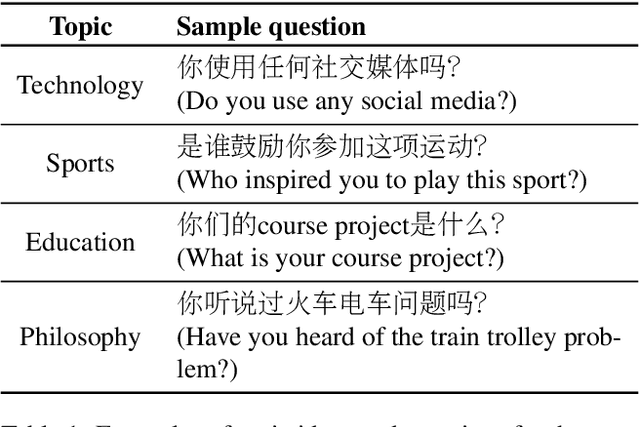

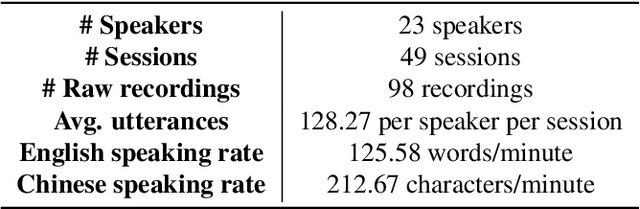
Code-switching is a speech phenomenon when a speaker switches language during a conversation. Despite the spontaneous nature of code-switching in conversational spoken language, most existing works collect code-switching data through read speech instead of spontaneous speech. ASCEND (A Spontaneous Chinese-English Dataset) introduces a high-quality resource of spontaneous multi-turn conversational dialogue Chinese-English code-switching corpus collected in Hong Kong. We report ASCEND's design and procedure of collecting the speech data, including the annotations in this work. ASCEND includes 23 bilinguals that are fluent in both Chinese and English and consists of 10.62 hours clean speech corpus. We also conduct a baseline experiment using pre-trained wav2vec 2.0 models, achieving the best performance of 22.69% character error rate and 27.05% mixed error rate.
NER-BERT: A Pre-trained Model for Low-Resource Entity Tagging
Dec 01, 2021
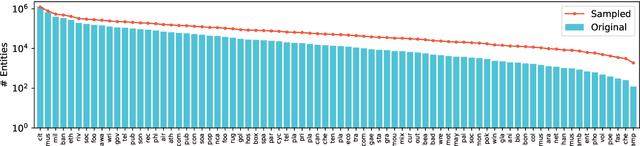

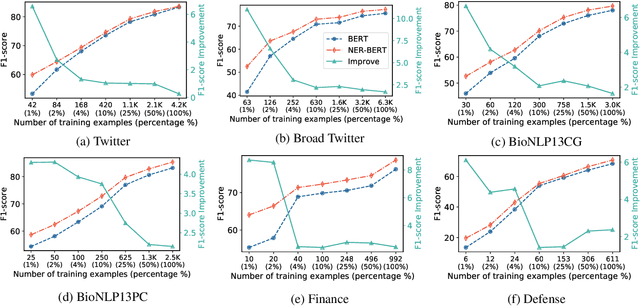
Named entity recognition (NER) models generally perform poorly when large training datasets are unavailable for low-resource domains. Recently, pre-training a large-scale language model has become a promising direction for coping with the data scarcity issue. However, the underlying discrepancies between the language modeling and NER task could limit the models' performance, and pre-training for the NER task has rarely been studied since the collected NER datasets are generally small or large but with low quality. In this paper, we construct a massive NER corpus with a relatively high quality, and we pre-train a NER-BERT model based on the created dataset. Experimental results show that our pre-trained model can significantly outperform BERT as well as other strong baselines in low-resource scenarios across nine diverse domains. Moreover, a visualization of entity representations further indicates the effectiveness of NER-BERT for categorizing a variety of entities.
Boosting Discriminative Visual Representation Learning with Scenario-Agnostic Mixup
Nov 30, 2021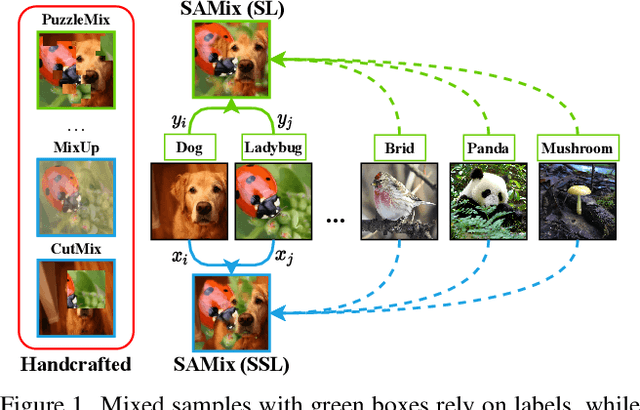
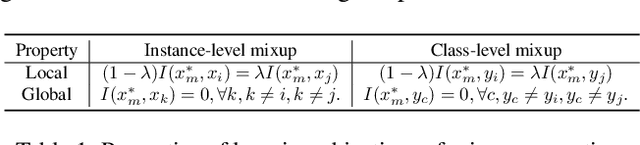
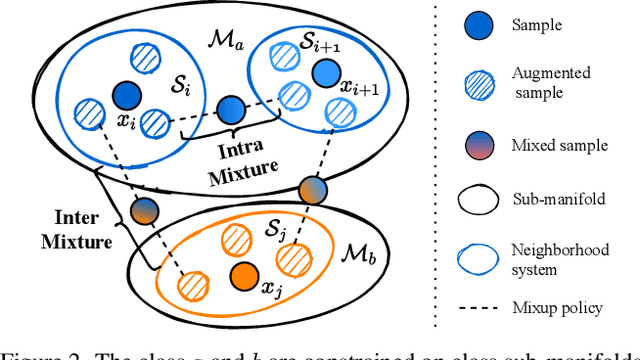
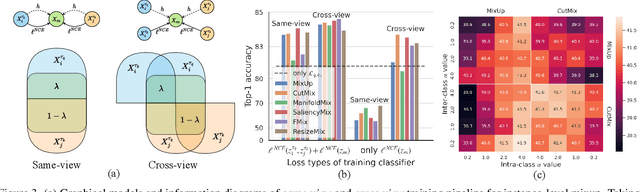
Mixup is a popular data-dependent augmentation technique for deep neural networks, which contains two sub-tasks, mixup generation and classification. The community typically confines mixup to supervised learning (SL) and the objective of generation sub-task is fixed to the sampled pairs instead of considering the whole data manifold. To overcome such limitations, we systematically study the objectives of two sub-tasks and propose Scenario-Agostic Mixup for both SL and Self-supervised Learning (SSL) scenarios, named SAMix. Specifically, we hypothesize and verify the core objective of mixup generation as optimizing the local smoothness between two classes subject to global discrimination from other classes. Based on this discovery, $\eta$-balanced mixup loss is proposed for complementary training of the two sub-tasks. Meanwhile, the generation sub-task is parameterized as an optimizable module, Mixer, which utilizes an attention mechanism to generate mixed samples without label dependency. Extensive experiments on SL and SSL tasks demonstrate that SAMix consistently outperforms leading methods by a large margin.
Surrogate Representation Learning with Isometric Mapping for Gray-box Graph Adversarial Attacks
Oct 25, 2021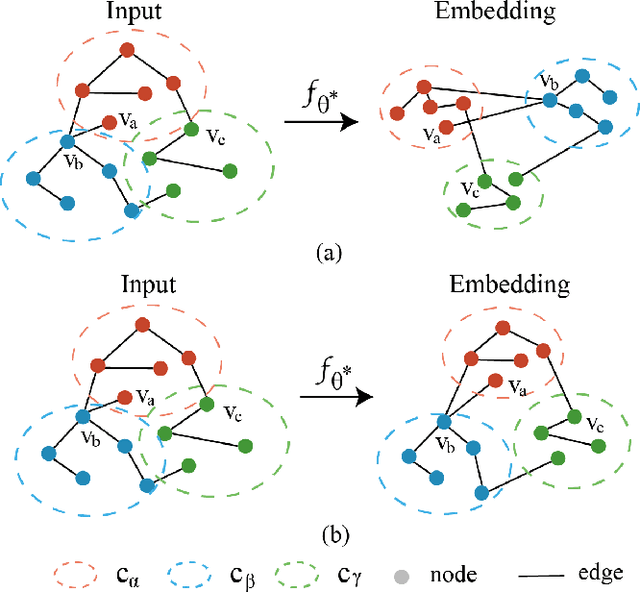
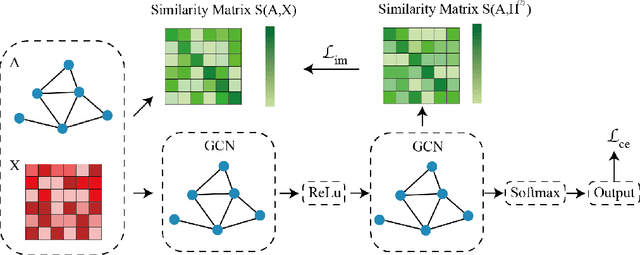
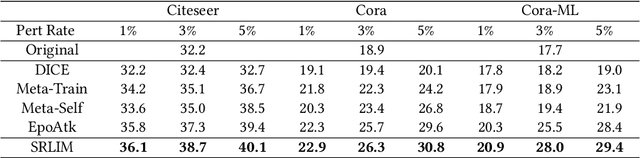
Gray-box graph attacks aim at disrupting the performance of the victim model by using inconspicuous attacks with limited knowledge of the victim model. The parameters of the victim model and the labels of the test nodes are invisible to the attacker. To obtain the gradient on the node attributes or graph structure, the attacker constructs an imaginary surrogate model trained under supervision. However, there is a lack of discussion on the training of surrogate models and the robustness of provided gradient information. The general node classification model loses the topology of the nodes on the graph, which is, in fact, an exploitable prior for the attacker. This paper investigates the effect of representation learning of surrogate models on the transferability of gray-box graph adversarial attacks. To reserve the topology in the surrogate embedding, we propose Surrogate Representation Learning with Isometric Mapping (SRLIM). By using Isometric mapping method, our proposed SRLIM can constrain the topological structure of nodes from the input layer to the embedding space, that is, to maintain the similarity of nodes in the propagation process. Experiments prove the effectiveness of our approach through the improvement in the performance of the adversarial attacks generated by the gradient-based attacker in untargeted poisoning gray-box setups.
Vision Guided Generative Pre-trained Language Models for Multimodal Abstractive Summarization
Oct 01, 2021
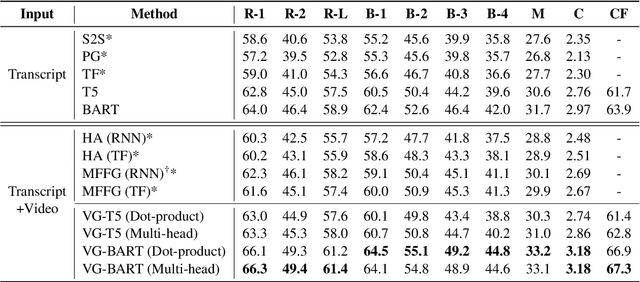
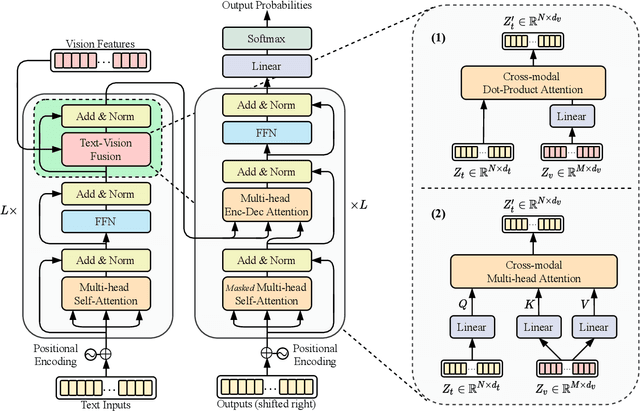

Multimodal abstractive summarization (MAS) models that summarize videos (vision modality) and their corresponding transcripts (text modality) are able to extract the essential information from massive multimodal data on the Internet. Recently, large-scale generative pre-trained language models (GPLMs) have been shown to be effective in text generation tasks. However, existing MAS models cannot leverage GPLMs' powerful generation ability. To fill this research gap, we aim to study two research questions: 1) how to inject visual information into GPLMs without hurting their generation ability; and 2) where is the optimal place in GPLMs to inject the visual information? In this paper, we present a simple yet effective method to construct vision guided (VG) GPLMs for the MAS task using attention-based add-on layers to incorporate visual information while maintaining their original text generation ability. Results show that our best model significantly surpasses the prior state-of-the-art model by 5.7 ROUGE-1, 5.3 ROUGE-2, and 5.1 ROUGE-L scores on the How2 dataset, and our visual guidance method contributes 83.6% of the overall improvement. Furthermore, we conduct thorough ablation studies to analyze the effectiveness of various modality fusion methods and fusion locations.