 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Model Averaging of Support Vector Machines in Diverging Model Spaces
Dec 30, 2021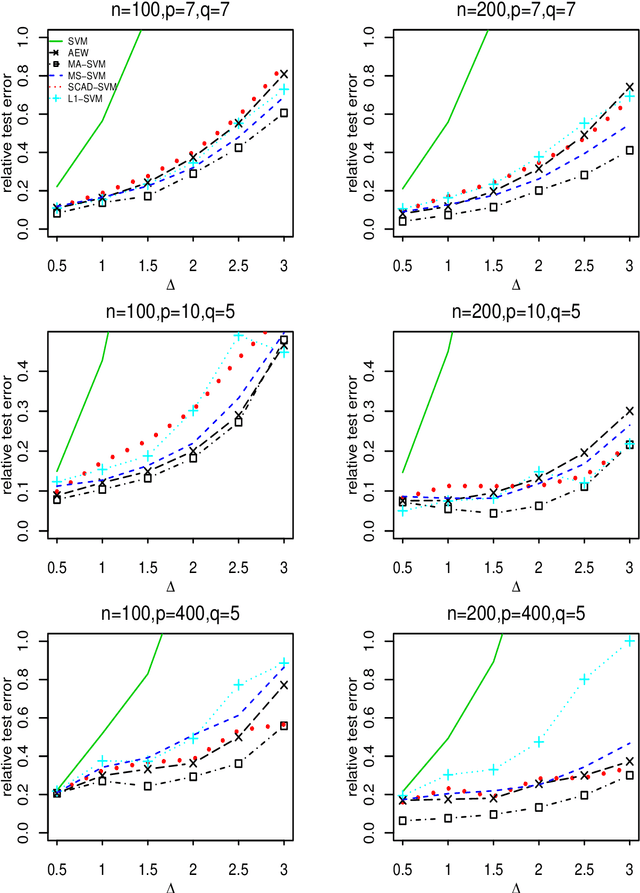
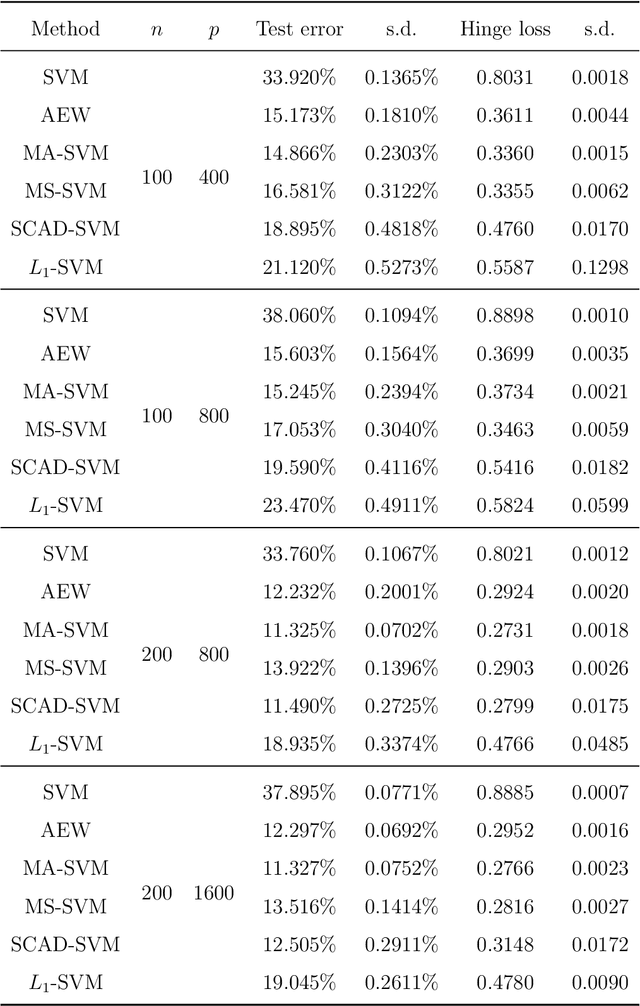
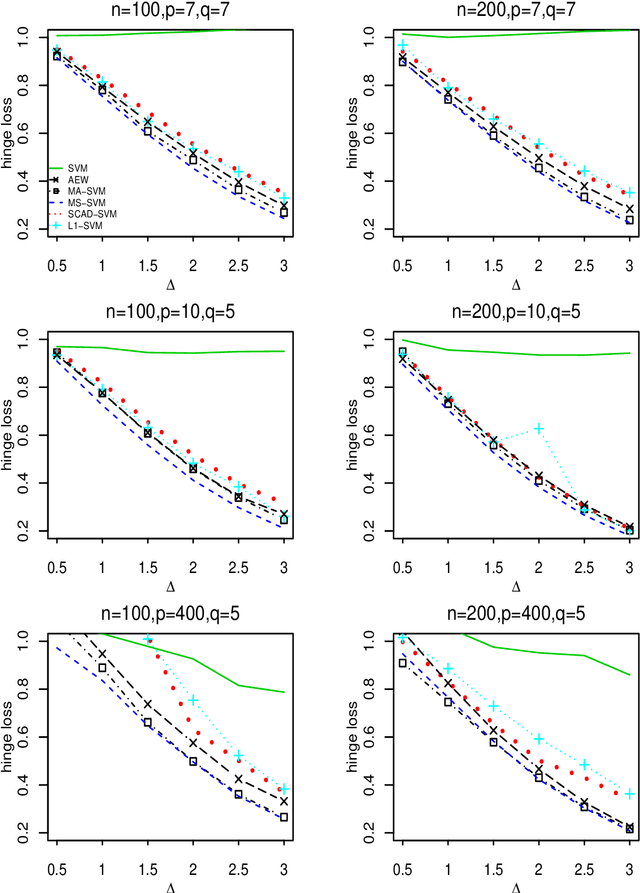
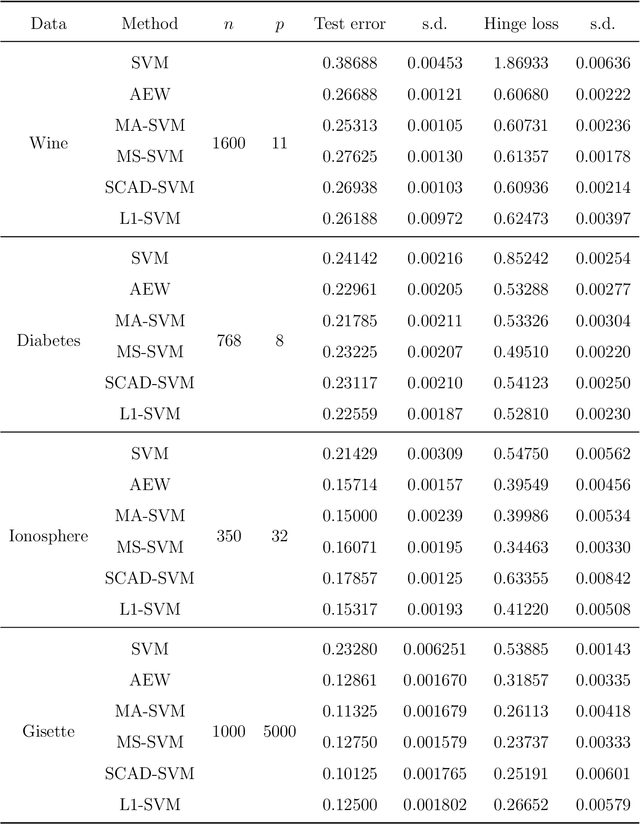
Support vector machine (SVM) is a powerful classification method that has achieved great success in many fields. Since its performance can be seriously impaired by redundant covariates, model selection techniques are widely used for SVM with high dimensional covariates. As an alternative to model selection, significant progress has been made in the area of model averaging in the past decades. Yet no frequentist model averaging method was considered for SVM. This work aims to fill the gap and to propose a frequentist model averaging procedure for SVM which selects the optimal weight by cross validation. Even when the number of covariates diverges at an exponential rate of the sample size, we show asymptotic optimality of the proposed method in the sense that the ratio of its hinge loss to the lowest possible loss converges to one. We also derive the convergence rate which provides more insights to model averaging. Compared to model selection methods of SVM which require a tedious but critical task of tuning parameter selection, the model averaging method avoids the task and shows promising performances in the empirical studies.
Insta-VAX: A Multimodal Benchmark for Anti-Vaccine and Misinformation Posts Detection on Social Media
Dec 15, 2021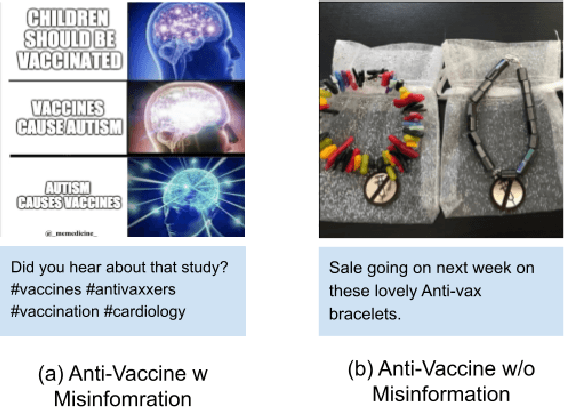
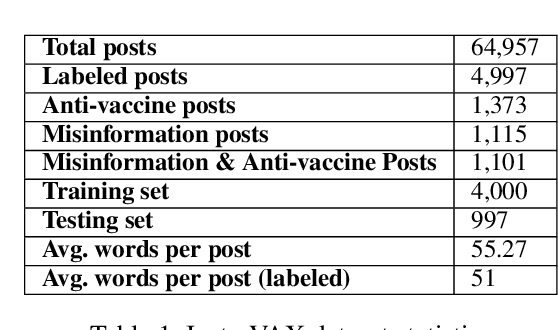
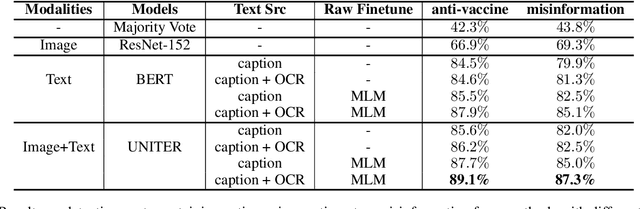

Sharing of anti-vaccine posts on social media, including misinformation posts, has been shown to create confusion and reduce the publics confidence in vaccines, leading to vaccine hesitancy and resistance. Recent years have witnessed the fast rise of such anti-vaccine posts in a variety of linguistic and visual forms in online networks, posing a great challenge for effective content moderation and tracking. Extending previous work on leveraging textual information to understand vaccine information, this paper presents Insta-VAX, a new multi-modal dataset consisting of a sample of 64,957 Instagram posts related to human vaccines. We applied a crowdsourced annotation procedure verified by two trained expert judges to this dataset. We then bench-marked several state-of-the-art NLP and computer vision classifiers to detect whether the posts show anti-vaccine attitude and whether they contain misinformation. Extensive experiments and analyses demonstrate the multimodal models can classify the posts more accurately than the uni-modal models, but still need improvement especially on visual context understanding and external knowledge cooperation. The dataset and classifiers contribute to monitoring and tracking of vaccine discussions for social scientific and public health efforts in combating the problem of vaccine misinformation.
ErAConD : Error Annotated Conversational Dialog Dataset for Grammatical Error Correction
Dec 15, 2021


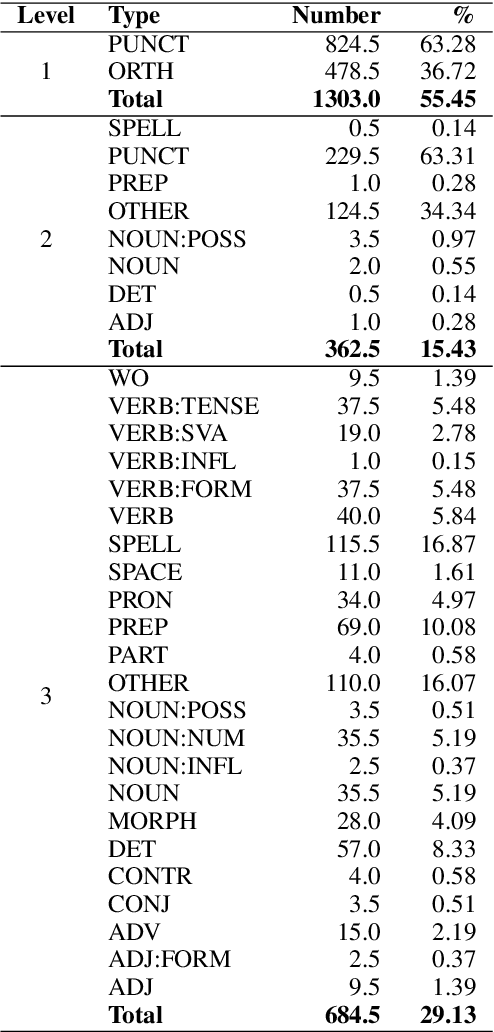
Currently available grammatical error correction (GEC) datasets are compiled using well-formed written text, limiting the applicability of these datasets to other domains such as informal writing and dialog. In this paper, we present a novel parallel GEC dataset drawn from open-domain chatbot conversations; this dataset is, to our knowledge, the first GEC dataset targeted to a conversational setting. To demonstrate the utility of the dataset, we use our annotated data to fine-tune a state-of-the-art GEC model, resulting in a 16 point increase in model precision. This is of particular importance in a GEC model, as model precision is considered more important than recall in GEC tasks since false positives could lead to serious confusion in language learners. We also present a detailed annotation scheme which ranks errors by perceived impact on comprehensibility, making our dataset both reproducible and extensible. Experimental results show the effectiveness of our data in improving GEC model performance in conversational scenario.
Database Search Results Disambiguation for Task-Oriented Dialog Systems
Dec 15, 2021


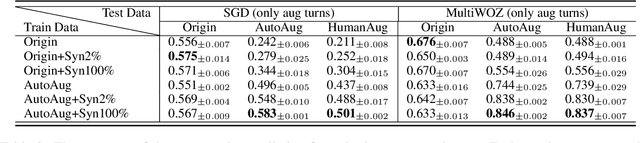
As task-oriented dialog systems are becoming increasingly popular in our lives, more realistic tasks have been proposed and explored. However, new practical challenges arise. For instance, current dialog systems cannot effectively handle multiple search results when querying a database, due to the lack of such scenarios in existing public datasets. In this paper, we propose Database Search Result (DSR) Disambiguation, a novel task that focuses on disambiguating database search results, which enhances user experience by allowing them to choose from multiple options instead of just one. To study this task, we augment the popular task-oriented dialog datasets (MultiWOZ and SGD) with turns that resolve ambiguities by (a) synthetically generating turns through a pre-defined grammar, and (b) collecting human paraphrases for a subset. We find that training on our augmented dialog data improves the model's ability to deal with ambiguous scenarios, without sacrificing performance on unmodified turns. Furthermore, pre-fine tuning and multi-task learning help our model to improve performance on DSR-disambiguation even in the absence of in-domain data, suggesting that it can be learned as a universal dialog skill. Our data and code will be made publicly available.
DG2: Data Augmentation Through Document Grounded Dialogue Generation
Dec 15, 2021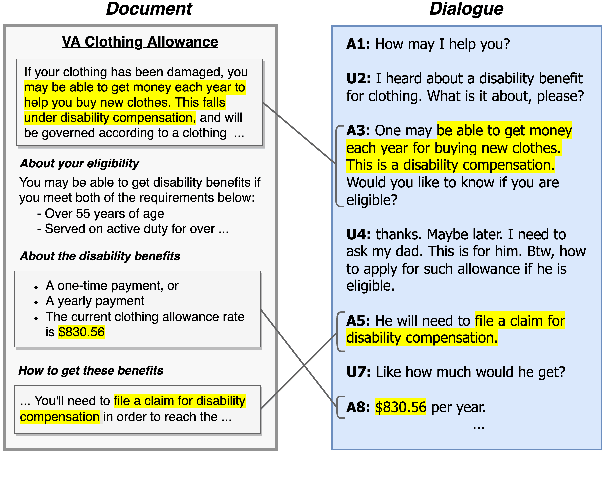
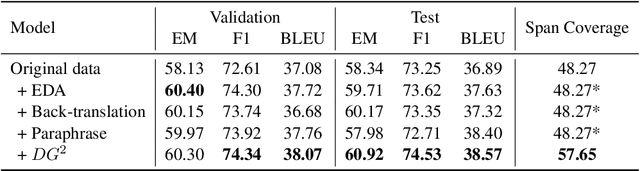
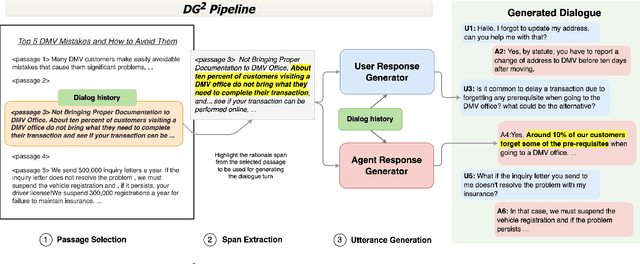

Collecting data for training dialog systems can be extremely expensive due to the involvement of human participants and need for extensive annotation. Especially in document-grounded dialog systems, human experts need to carefully read the unstructured documents to answer the users' questions. As a result, existing document-grounded dialog datasets are relatively small-scale and obstruct the effective training of dialogue systems. In this paper, we propose an automatic data augmentation technique grounded on documents through a generative dialogue model. The dialogue model consists of a user bot and agent bot that can synthesize diverse dialogues given an input document, which are then used to train a downstream model. When supplementing the original dataset, our method achieves significant improvement over traditional data augmentation methods. We also achieve great performance in the low-resource setting.
AllWOZ: Towards Multilingual Task-Oriented Dialog Systems for All
Dec 15, 2021

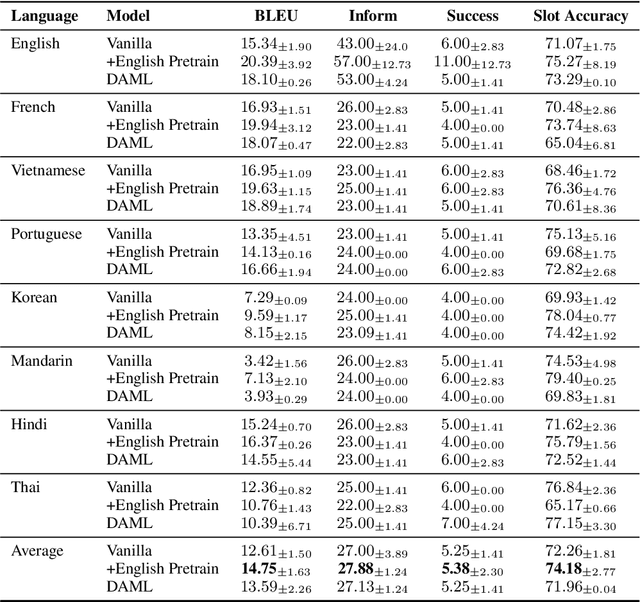
A commonly observed problem of the state-of-the-art natural language technologies, such as Amazon Alexa and Apple Siri, is that their services do not extend to most developing countries' citizens due to language barriers. Such populations suffer due to the lack of available resources in their languages to build NLP products. This paper presents AllWOZ, a multilingual multi-domain task-oriented customer service dialog dataset covering eight languages: English, Mandarin, Korean, Vietnamese, Hindi, French, Portuguese, and Thai. Furthermore, we create a benchmark for our multilingual dataset by applying mT5 with meta-learning.
Improving Conversational Recommendation Systems' Quality with Context-Aware Item Meta Information
Dec 15, 2021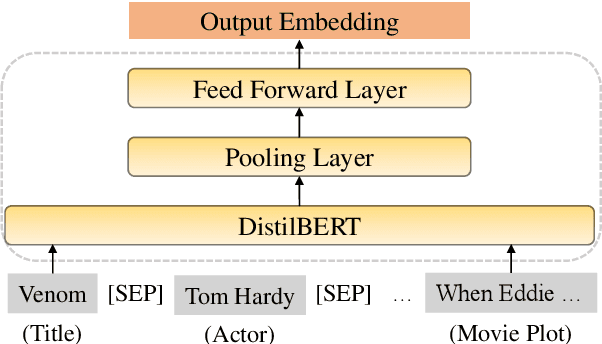
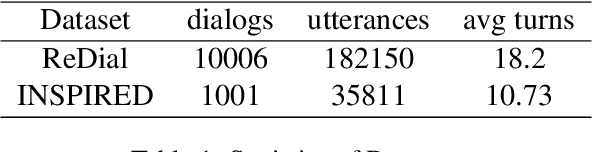
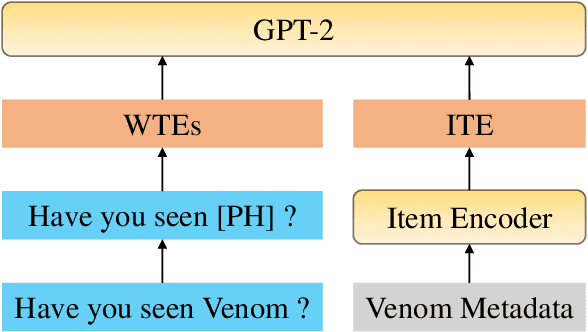
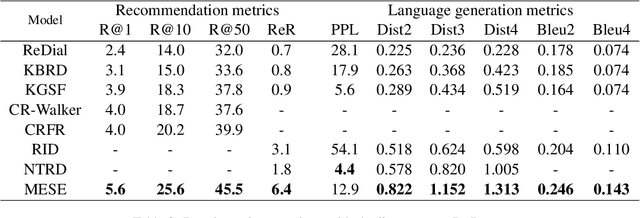
Conversational recommendation systems (CRS) engage with users by inferring user preferences from dialog history, providing accurate recommendations, and generating appropriate responses. Previous CRSs use knowledge graph (KG) based recommendation modules and integrate KG with language models for response generation. Although KG-based approaches prove effective, two issues remain to be solved. First, KG-based approaches ignore the information in the conversational context but only rely on entity relations and bag of words to recommend items. Second, it requires substantial engineering efforts to maintain KGs that model domain-specific relations, thus leading to less flexibility. In this paper, we propose a simple yet effective architecture comprising a pre-trained language model (PLM) and an item metadata encoder. The encoder learns to map item metadata to embeddings that can reflect the semantic information in the dialog context. The PLM then consumes the semantic-aligned item embeddings together with dialog context to generate high-quality recommendations and responses. Instead of modeling entity relations with KGs, our model reduces engineering complexity by directly converting each item to an embedding. Experimental results on the benchmark dataset ReDial show that our model obtains state-of-the-art results on both recommendation and response generation tasks.
Knowledge-Grounded Dialogue Generation with a Unified Knowledge Representation
Dec 15, 2021



Knowledge-grounded dialogue systems are challenging to build due to the lack of training data and heterogeneous knowledge sources. Existing systems perform poorly on unseen topics due to limited topics covered in the training data. In addition, heterogeneous knowledge sources make it challenging for systems to generalize to other tasks because knowledge sources in different knowledge representations require different knowledge encoders. To address these challenges, we present PLUG, a language model that homogenizes different knowledge sources to a unified knowledge representation for knowledge-grounded dialogue generation tasks. PLUG is pre-trained on a dialogue generation task conditioned on a unified essential knowledge representation. It can generalize to different downstream knowledge-grounded dialogue generation tasks with a few training examples. The empirical evaluation on two benchmarks shows that our model generalizes well across different knowledge-grounded tasks. It can achieve comparable performance with state-of-the-art methods under a fully-supervised setting and significantly outperforms other methods in zero-shot and few-shot settings.
IconQA: A New Benchmark for Abstract Diagram Understanding and Visual Language Reasoning
Nov 07, 2021
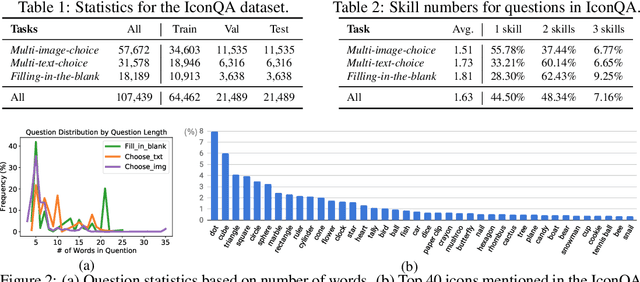
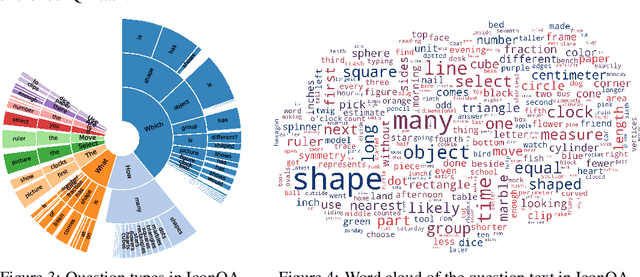

Current visual question answering (VQA) tasks mainly consider answering human-annotated questions for natural images. However, aside from natural images, abstract diagrams with semantic richness are still understudied in visual understanding and reasoning research. In this work, we introduce a new challenge of Icon Question Answering (IconQA) with the goal of answering a question in an icon image context. We release IconQA, a large-scale dataset that consists of 107,439 questions and three sub-tasks: multi-image-choice, multi-text-choice, and filling-in-the-blank. The IconQA dataset is inspired by real-world diagram word problems that highlight the importance of abstract diagram understanding and comprehensive cognitive reasoning. Thus, IconQA requires not only perception skills like object recognition and text understanding, but also diverse cognitive reasoning skills, such as geometric reasoning, commonsense reasoning, and arithmetic reasoning. To facilitate potential IconQA models to learn semantic representations for icon images, we further release an icon dataset Icon645 which contains 645,687 colored icons on 377 classes. We conduct extensive user studies and blind experiments and reproduce a wide range of advanced VQA methods to benchmark the IconQA task. Also, we develop a strong IconQA baseline Patch-TRM that applies a pyramid cross-modal Transformer with input diagram embeddings pre-trained on the icon dataset. IconQA and Icon645 are available at https://iconqa.github.io.
Learning with Noisy Labels by Targeted Relabeling
Oct 15, 2021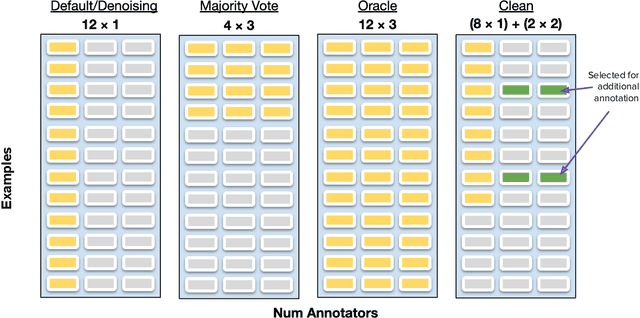

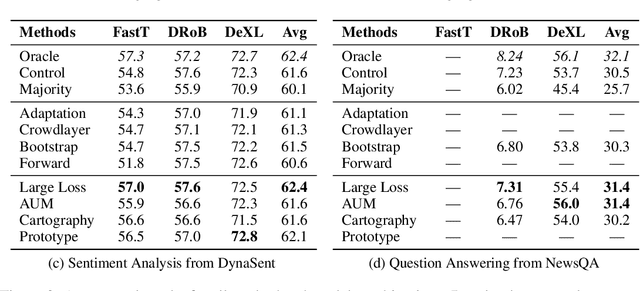
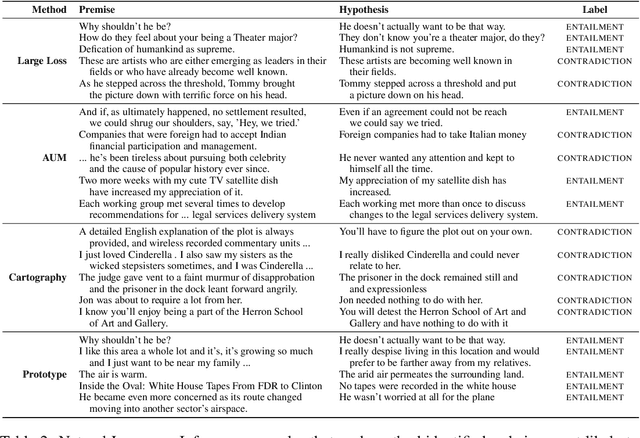
Crowdsourcing platforms are often used to collect datasets for training deep neural networks, despite higher levels of inaccurate labeling compared to expert labeling. There are two common strategies to manage the impact of this noise, the first involves aggregating redundant annotations, but comes at the expense of labeling substantially fewer examples. Secondly, prior works have also considered using the entire annotation budget to label as many examples as possible and subsequently apply denoising algorithms to implicitly clean up the dataset. We propose an approach which instead reserves a fraction of annotations to explicitly relabel highly probable labeling errors. In particular, we allocate a large portion of the labeling budget to form an initial dataset used to train a model. This model is then used to identify specific examples that appear most likely to be incorrect, which we spend the remaining budget to relabel. Experiments across three model variations and four natural language processing tasks show our approach outperforms both label aggregation and advanced denoising methods designed to handle noisy labels when allocated the same annotation budget.