 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA physics-informed foundation model for quantitative diffusion MRI
May 29, 2026Understanding the human brain requires access to its microscopic tissue architecture. Diffusion magnetic resonance imaging (MRI) provides the only noninvasive window into whole-brain microstructure in vivo, yet reliable quantitative mapping remains confined to specialized research settings requiring dense sampling and optimized acquisition protocols. To address this gap, we present a physics-informed generative microstructure network (PIGMENT) that learns a universal generative prior of human brain microstructure and adapts it zero-shot to each participant's measured data to recover subject-specific maps. Trained on 11375 scans spanning multiple sites, vendors, and field strengths, PIGMENT enabled reliable quantitative mapping for tensor, kurtosis, and NODDI models across external datasets from five independent centers. It remains effective where conventional fitting becomes unreliable, recovering meaningful maps from extremely sparse acquisitions while supporting downstream tractography and structural connectivity mapping. PIGMENT estimates demonstrated strong biological validity, preserving submillimeter cortical microarchitectural patterns and early-childhood white matter developmental trajectories from 10-fold accelerated scans. Furthermore, PIGMENT enables reliable quantitative tensor mapping on cost-efficient low-field systems and the extraction of tumor-related biomarkers using ultra-fast clinical protocols. Together, these results establish PIGMENT as a physics-informed foundation model that extends quantitative diffusion MRI into regimes traditionally too sparse, heterogeneous, or clinically constrained for reliable analysis.
VFLGAN-TS: Vertical Federated Learning-based Generative Adversarial Networks for Publication of Vertically Partitioned Time-Series Data
Sep 05, 2024



In the current artificial intelligence (AI) era, the scale and quality of the dataset play a crucial role in training a high-quality AI model. However, often original data cannot be shared due to privacy concerns and regulations. A potential solution is to release a synthetic dataset with a similar distribution to the private dataset. Nevertheless, in some scenarios, the attributes required to train an AI model are distributed among different parties, and the parties cannot share the local data for synthetic data construction due to privacy regulations. In PETS 2024, we recently introduced the first Vertical Federated Learning-based Generative Adversarial Network (VFLGAN) for publishing vertically partitioned static data. However, VFLGAN cannot effectively handle time-series data, presenting both temporal and attribute dimensions. In this article, we proposed VFLGAN-TS, which combines the ideas of attribute discriminator and vertical federated learning to generate synthetic time-series data in the vertically partitioned scenario. The performance of VFLGAN-TS is close to that of its counterpart, which is trained in a centralized manner and represents the upper limit for VFLGAN-TS. To further protect privacy, we apply a Gaussian mechanism to make VFLGAN-TS satisfy an $(\epsilon,\delta)$-differential privacy. Besides, we develop an enhanced privacy auditing scheme to evaluate the potential privacy breach through the framework of VFLGAN-TS and synthetic datasets.
Large Language Model assisted End-to-End Network Health Management based on Multi-Scale Semanticization
Jun 12, 2024



Network device and system health management is the foundation of modern network operations and maintenance. Traditional health management methods, relying on expert identification or simple rule-based algorithms, struggle to cope with the dynamic heterogeneous networks (DHNs) environment. Moreover, current state-of-the-art distributed anomaly detection methods, which utilize specific machine learning techniques, lack multi-scale adaptivity for heterogeneous device information, resulting in unsatisfactory diagnostic accuracy for DHNs. In this paper, we develop an LLM-assisted end-to-end intelligent network health management framework. The framework first proposes a Multi-Scale Semanticized Anomaly Detection Model (MSADM), incorporating semantic rule trees with an attention mechanism to address the multi-scale anomaly detection problem in DHNs. Secondly, a chain-of-thought-based large language model is embedded in downstream to adaptively analyze the fault detection results and produce an analysis report with detailed fault information and optimization strategies. Experimental results show that the accuracy of our proposed MSADM for heterogeneous network entity anomaly detection is as high as 91.31\%.
VFLGAN: Vertical Federated Learning-based Generative Adversarial Network for Vertically Partitioned Data Publication
Apr 15, 2024In the current artificial intelligence (AI) era, the scale and quality of the dataset play a crucial role in training a high-quality AI model. However, good data is not a free lunch and is always hard to access due to privacy regulations like the General Data Protection Regulation (GDPR). A potential solution is to release a synthetic dataset with a similar distribution to that of the private dataset. Nevertheless, in some scenarios, it has been found that the attributes needed to train an AI model belong to different parties, and they cannot share the raw data for synthetic data publication due to privacy regulations. In PETS 2023, Xue et al. proposed the first generative adversary network-based model, VertiGAN, for vertically partitioned data publication. However, after thoroughly investigating, we found that VertiGAN is less effective in preserving the correlation among the attributes of different parties. This article proposes a Vertical Federated Learning-based Generative Adversarial Network, VFLGAN, for vertically partitioned data publication to address the above issues. Our experimental results show that compared with VertiGAN, VFLGAN significantly improves the quality of synthetic data. Taking the MNIST dataset as an example, the quality of the synthetic dataset generated by VFLGAN is 3.2 times better than that generated by VertiGAN w.r.t. the Fr\'echet Distance. We also designed a more efficient and effective Gaussian mechanism for the proposed VFLGAN to provide the synthetic dataset with a differential privacy guarantee. On the other hand, differential privacy only gives the upper bound of the worst-case privacy guarantee. This article also proposes a practical auditing scheme that applies membership inference attacks to estimate privacy leakage through the synthetic dataset.
An Effective LSTM-DDPM Scheme for Energy Theft Detection and Forecasting in Smart Grid
Aug 03, 2023Energy theft detection (ETD) and energy consumption forecasting (ECF) are two interconnected challenges in smart grid systems. Addressing these issues collectively is crucial for ensuring system security. This paper addresses the interconnected challenges of ETD and ECF in smart grid systems. The proposed solution combines long short-term memory (LSTM) and a denoising diffusion probabilistic model (DDPM) to generate input reconstruction and forecasting. By leveraging the reconstruction and forecasting errors, the system identifies instances of energy theft, with the methods based on reconstruction error and forecasting error complementing each other in detecting different types of attacks. Through extensive experiments on real-world and synthetic datasets, the proposed scheme outperforms baseline methods in ETD and ECF problems. The ensemble method significantly enhances ETD performance, accurately detecting energy theft attacks that baseline methods fail to detect. The research offers a comprehensive and effective solution for addressing ETD and ECF challenges, demonstrating promising results and improved security in smart grid systems.
Using Chatbots to Teach Languages
Jul 31, 2022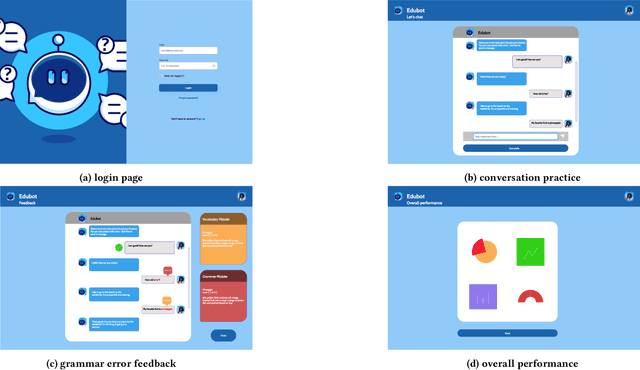

This paper reports on progress towards building an online language learning tool to provide learners with conversational experience by using dialog systems as conversation practice partners. Our system can adapt to users' language proficiency on the fly. We also provide automatic grammar error feedback to help users learn from their mistakes. According to our first adopters, our system is entertaining and useful. Furthermore, we will provide the learning technology community a large-scale conversation dataset on language learning and grammar correction. Our next step is to make our system more adaptive to user profile information by using reinforcement learning algorithms.
ErAConD : Error Annotated Conversational Dialog Dataset for Grammatical Error Correction
Dec 15, 2021


Currently available grammatical error correction (GEC) datasets are compiled using well-formed written text, limiting the applicability of these datasets to other domains such as informal writing and dialog. In this paper, we present a novel parallel GEC dataset drawn from open-domain chatbot conversations; this dataset is, to our knowledge, the first GEC dataset targeted to a conversational setting. To demonstrate the utility of the dataset, we use our annotated data to fine-tune a state-of-the-art GEC model, resulting in a 16 point increase in model precision. This is of particular importance in a GEC model, as model precision is considered more important than recall in GEC tasks since false positives could lead to serious confusion in language learners. We also present a detailed annotation scheme which ranks errors by perceived impact on comprehensibility, making our dataset both reproducible and extensible. Experimental results show the effectiveness of our data in improving GEC model performance in conversational scenario.
Realtime CNN-based Keypoint Detector with Sobel Filter and CNN-based Descriptor Trained with Keypoint Candidates
Nov 04, 2020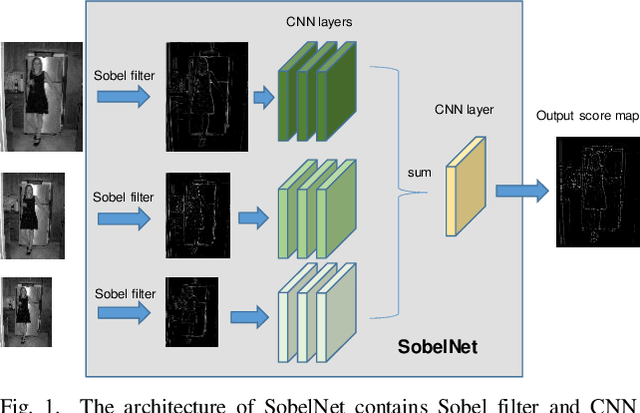
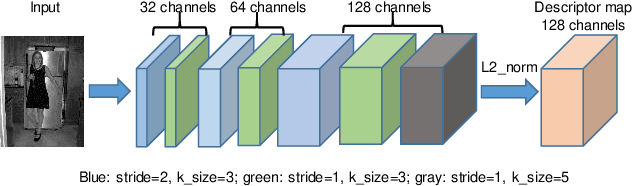
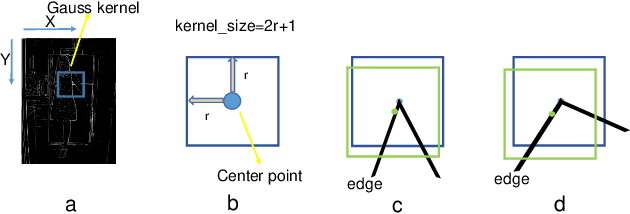
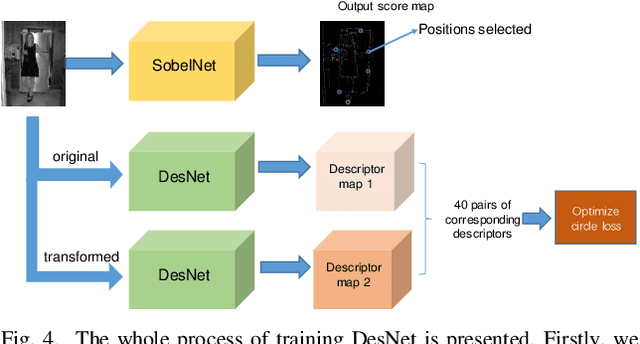
The local feature detector and descriptor are essential in many computer vision tasks, such as SLAM and 3D reconstruction. In this paper, we introduce two separate CNNs, lightweight SobelNet and DesNet, to detect key points and to compute dense local descriptors. The detector and the descriptor work in parallel. Sobel filter provides the edge structure of the input images as the input of CNN. The locations of key points will be obtained after exerting the non-maximum suppression (NMS) process on the output map of the CNN. We design Gaussian loss for the training process of SobelNet to detect corner points as keypoints. At the same time, the input of DesNet is the original grayscale image, and circle loss is used to train DesNet. Besides, output maps of SobelNet are needed while training DesNet. We have evaluated our method on several benchmarks including HPatches benchmark, ETH benchmark, and FM-Bench. SobelNet achieves better or comparable performance with less computation compared with SOTA methods in recent years. The inference time of an image of 640x480 is 7.59ms and 1.09ms for SobelNet and DesNet respectively on RTX 2070 SUPER.