 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManiSkill: Learning-from-Demonstrations Benchmark for Generalizable Manipulation Skills
Aug 09, 2021
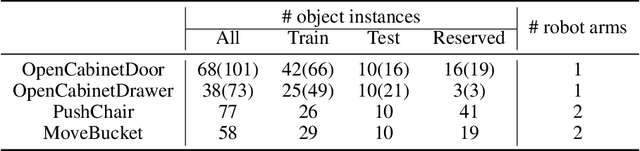
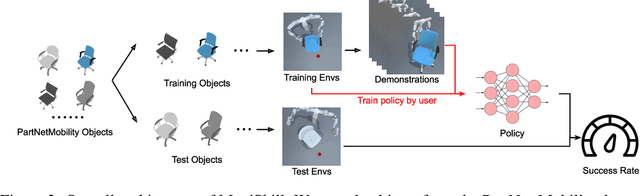

Learning generalizable manipulation skills is central for robots to achieve task automation in environments with endless scene and object variations. However, existing robot learning environments are limited in both scale and diversity of 3D assets (especially of articulated objects), making it difficult to train and evaluate the generalization ability of agents over novel objects. In this work, we focus on object-level generalization and propose SAPIEN Manipulation Skill Benchmark (abbreviated as ManiSkill), a large-scale learning-from-demonstrations benchmark for articulated object manipulation with 3D visual input (point cloud and RGB-D image). ManiSkill supports object-level variations by utilizing a rich and diverse set of articulated objects, and each task is carefully designed for learning manipulations on a single category of objects. We equip ManiSkill with a large number of high-quality demonstrations to facilitate learning-from-demonstrations approaches and perform evaluations on baseline algorithms. We believe that ManiSkill can encourage the robot learning community to explore more on learning generalizable object manipulation skills.
PlasticineLab: A Soft-Body Manipulation Benchmark with Differentiable Physics
Apr 07, 2021
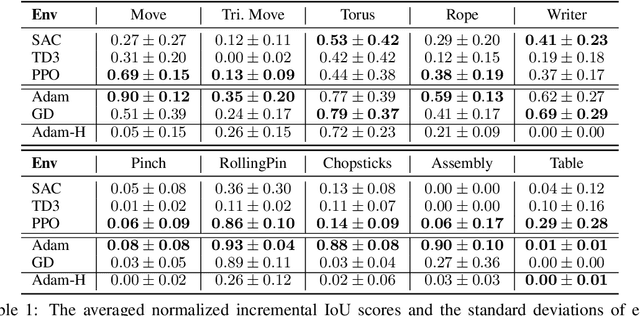
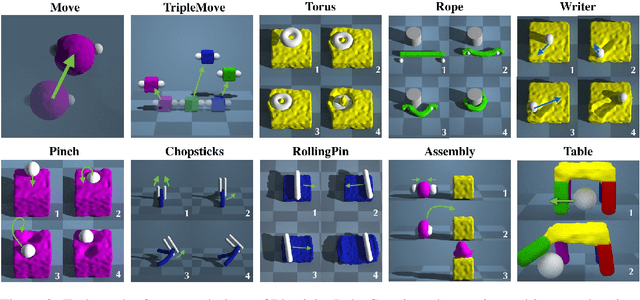
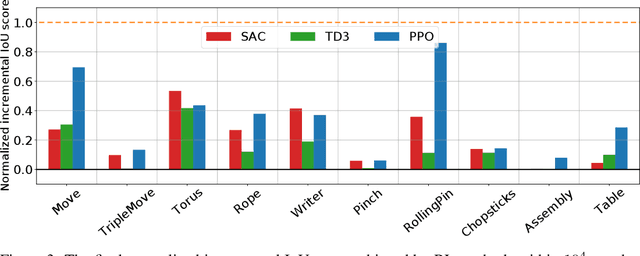
Simulated virtual environments serve as one of the main driving forces behind developing and evaluating skill learning algorithms. However, existing environments typically only simulate rigid body physics. Additionally, the simulation process usually does not provide gradients that might be useful for planning and control optimizations. We introduce a new differentiable physics benchmark called PasticineLab, which includes a diverse collection of soft body manipulation tasks. In each task, the agent uses manipulators to deform the plasticine into the desired configuration. The underlying physics engine supports differentiable elastic and plastic deformation using the DiffTaichi system, posing many under-explored challenges to robotic agents. We evaluate several existing reinforcement learning (RL) methods and gradient-based methods on this benchmark. Experimental results suggest that 1) RL-based approaches struggle to solve most of the tasks efficiently; 2) gradient-based approaches, by optimizing open-loop control sequences with the built-in differentiable physics engine, can rapidly find a solution within tens of iterations, but still fall short on multi-stage tasks that require long-term planning. We expect that PlasticineLab will encourage the development of novel algorithms that combine differentiable physics and RL for more complex physics-based skill learning tasks.
Towards Scale-Invariant Graph-related Problem Solving by Iterative Homogeneous Graph Neural Networks
Oct 26, 2020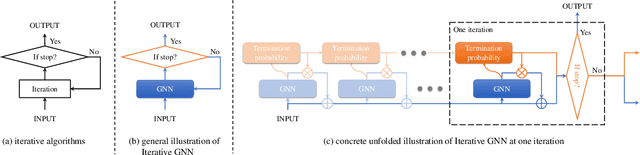
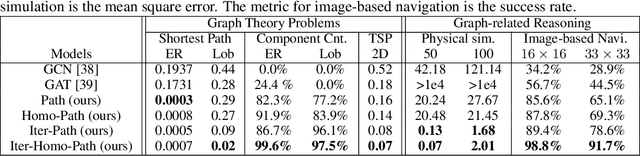
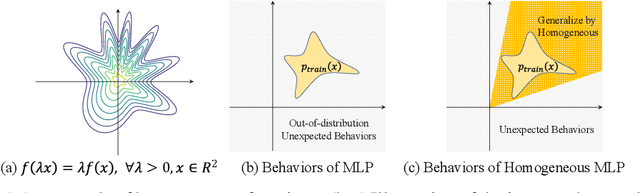

Current graph neural networks (GNNs) lack generalizability with respect to scales (graph sizes, graph diameters, edge weights, etc..) when solving many graph analysis problems. Taking the perspective of synthesizing graph theory programs, we propose several extensions to address the issue. First, inspired by the dependency of the iteration number of common graph theory algorithms on graph size, we learn to terminate the message passing process in GNNs adaptively according to the computation progress. Second, inspired by the fact that many graph theory algorithms are homogeneous with respect to graph weights, we introduce homogeneous transformation layers that are universal homogeneous function approximators, to convert ordinary GNNs to be homogeneous. Experimentally, we show that our GNN can be trained from small-scale graphs but generalize well to large-scale graphs for a number of basic graph theory problems. It also shows generalizability for applications of multi-body physical simulation and image-based navigation problems.
Learning to Group: A Bottom-Up Framework for 3D Part Discovery in Unseen Categories
Feb 16, 2020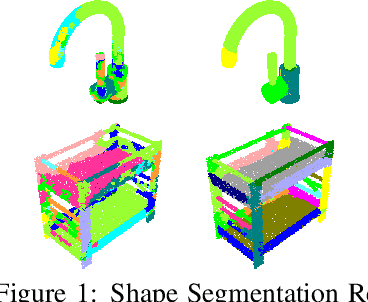
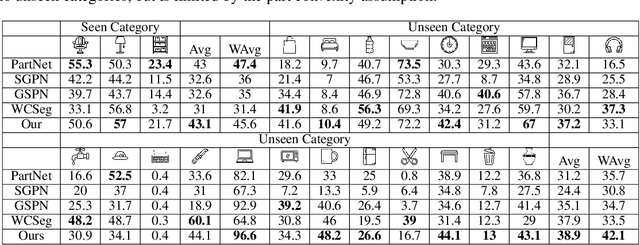
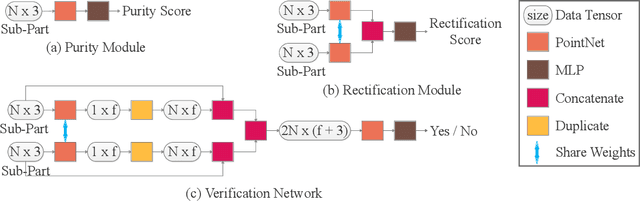
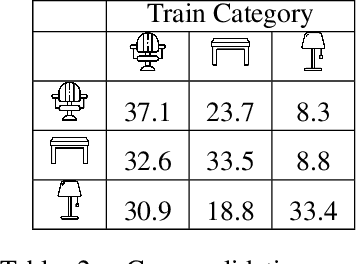
We address the problem of discovering 3D parts for objects in unseen categories. Being able to learn the geometry prior of parts and transfer this prior to unseen categories pose fundamental challenges on data-driven shape segmentation approaches. Formulated as a contextual bandit problem, we propose a learning-based agglomerative clustering framework which learns a grouping policy to progressively group small part proposals into bigger ones in a bottom-up fashion. At the core of our approach is to restrict the local context for extracting part-level features, which encourages the generalizability to unseen categories. On the large-scale fine-grained 3D part dataset, PartNet, we demonstrate that our method can transfer knowledge of parts learned from 3 training categories to 21 unseen testing categories without seeing any annotated samples. Quantitative comparisons against four shape segmentation baselines shows that our approach achieve the state-of-the-art performance.
Mapping State Space using Landmarks for Universal Goal Reaching
Aug 15, 2019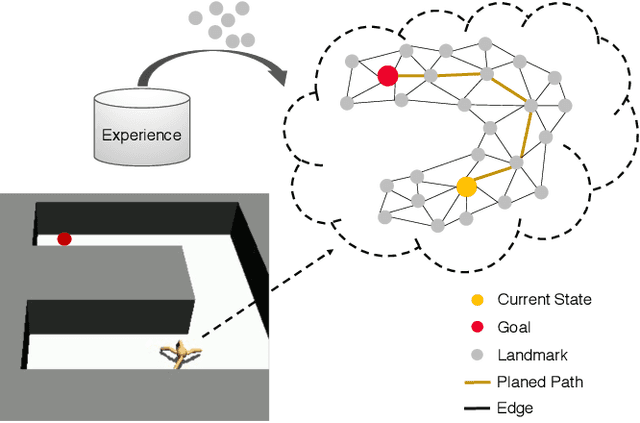
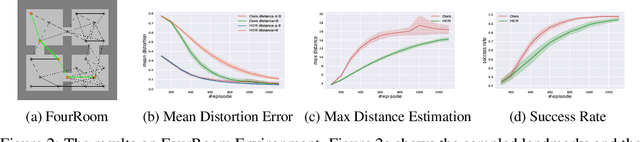
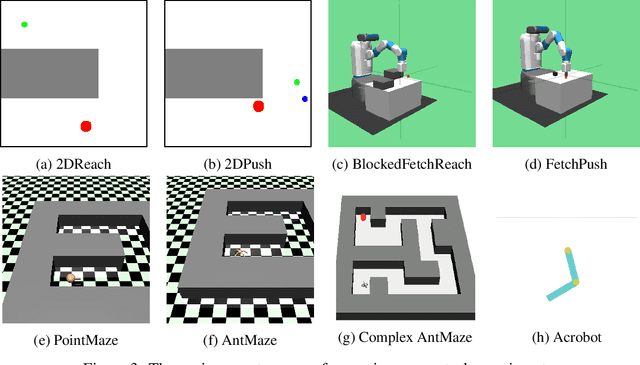
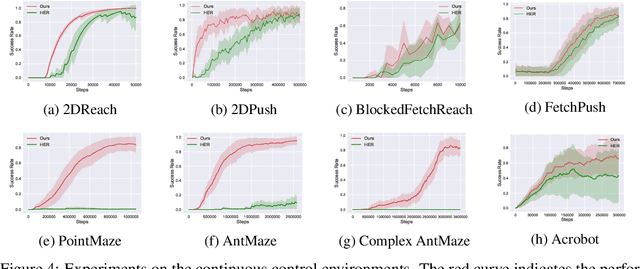
An agent that has well understood the environment should be able to apply its skills for any given goals, leading to the fundamental problem of learning the Universal Value Function Approximator (UVFA). A UVFA learns to predict the cumulative rewards between all state-goal pairs. However, empirically, the value function for long-range goals is always hard to estimate and may consequently result in failed policy. This has presented challenges to the learning process and the capability of neural networks. We propose a method to address this issue in large MDPs with sparse rewards, in which exploration and routing across remote states are both extremely challenging. Our method explicitly models the environment in a hierarchical manner, with a high-level dynamic landmark-based map abstracting the visited state space, and a low-level value network to derive precise local decisions. We use farthest point sampling to select landmark states from past experience, which has improved exploration compared with simple uniform sampling. Experimentally we showed that our method enables the agent to reach long-range goals at the early training stage, and achieve better performance than standard RL algorithms for a number of challenging tasks.
Object-Oriented Dynamics Predictor
Oct 30, 2018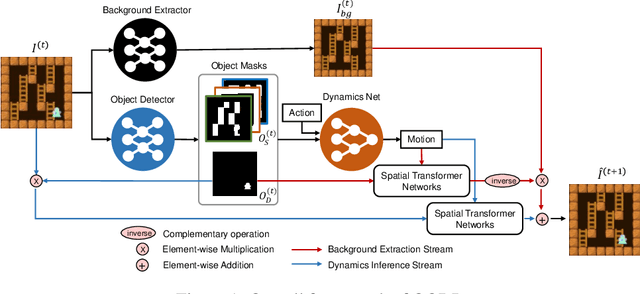
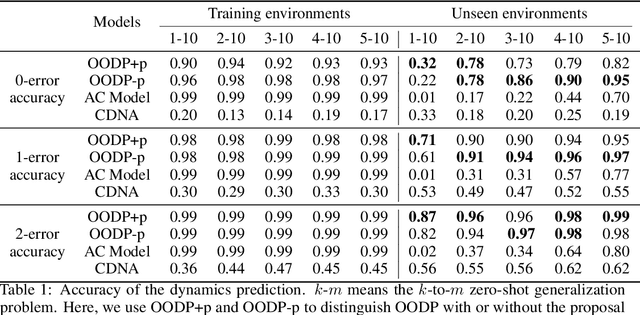
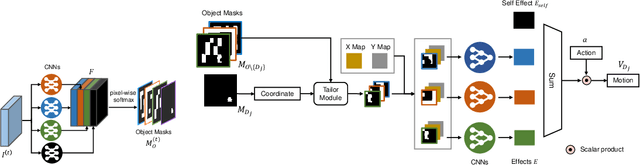
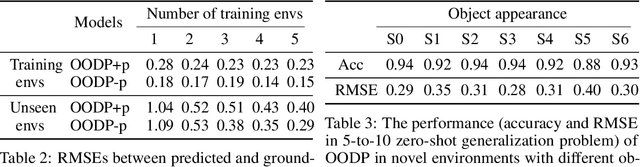
Generalization has been one of the major challenges for learning dynamics models in model-based reinforcement learning. However, previous work on action-conditioned dynamics prediction focuses on learning the pixel-level motion and thus does not generalize well to novel environments with different object layouts. In this paper, we present a novel object-oriented framework, called object-oriented dynamics predictor (OODP), which decomposes the environment into objects and predicts the dynamics of objects conditioned on both actions and object-to-object relations. It is an end-to-end neural network and can be trained in an unsupervised manner. To enable the generalization ability of dynamics learning, we design a novel CNN-based relation mechanism that is class-specific (rather than object-specific) and exploits the locality principle. Empirical results show that OODP significantly outperforms previous methods in terms of generalization over novel environments with various object layouts. OODP is able to learn from very few environments and accurately predict dynamics in a large number of unseen environments. In addition, OODP learns semantically and visually interpretable dynamics models.
Associative Embedding: End-to-End Learning for Joint Detection and Grouping
Jun 09, 2017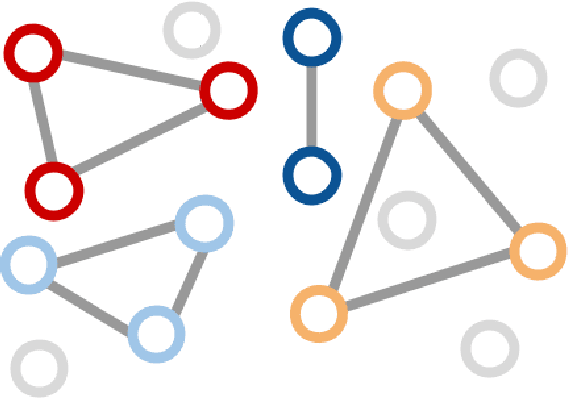

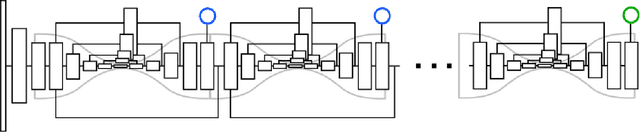
We introduce associative embedding, a novel method for supervising convolutional neural networks for the task of detection and grouping. A number of computer vision problems can be framed in this manner including multi-person pose estimation, instance segmentation, and multi-object tracking. Usually the grouping of detections is achieved with multi-stage pipelines, instead we propose an approach that teaches a network to simultaneously output detections and group assignments. This technique can be easily integrated into any state-of-the-art network architecture that produces pixel-wise predictions. We show how to apply this method to both multi-person pose estimation and instance segmentation and report state-of-the-art performance for multi-person pose on the MPII and MS-COCO datasets.
Coarse-to-fine Face Alignment with Multi-Scale Local Patch Regression
Nov 16, 2015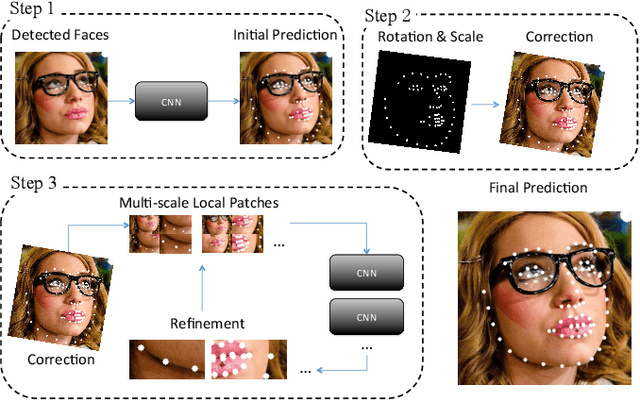

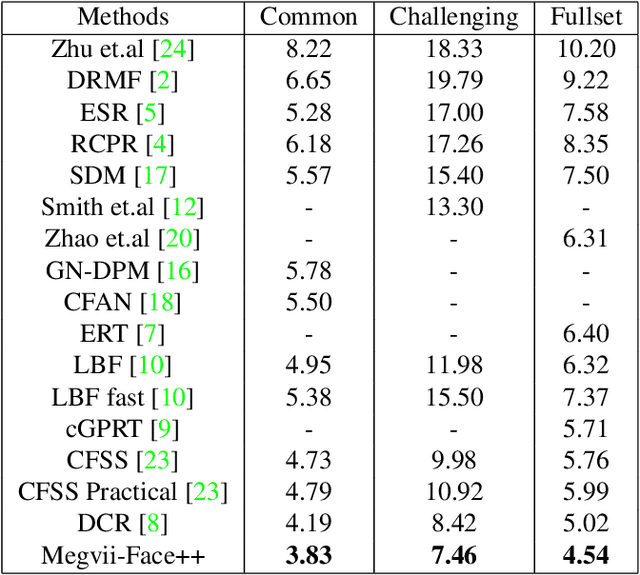

Facial landmark localization plays an important role in face recognition and analysis applications. In this paper, we give a brief introduction to a coarse-to-fine pipeline with neural networks and sequential regression. First, a global convolutional network is applied to the holistic facial image to give an initial landmark prediction. A pyramid of multi-scale local image patches is then cropped to feed to a new network for each landmark to refine the prediction. As the refinement network outputs a more accurate position estimation than the input, such procedure could be repeated several times until the estimation converges. We evaluate our system on the 300-W dataset [11] and it outperforms the recent state-of-the-arts.