 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Centric Embodied Question Answer
Paper and Code
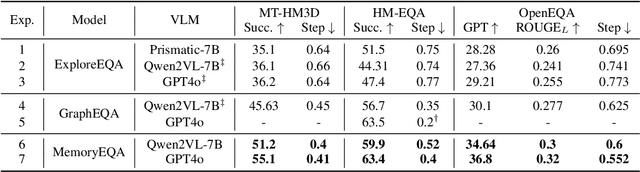
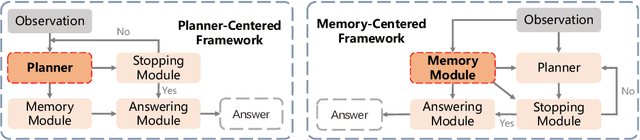
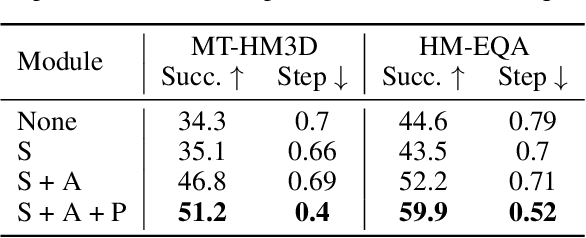
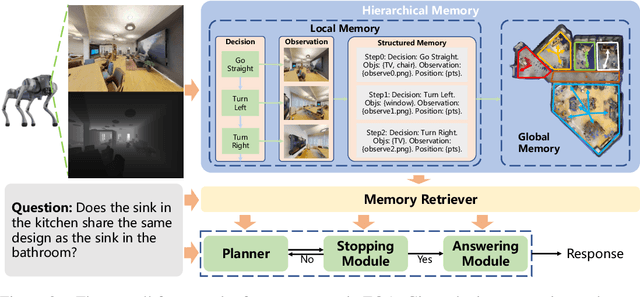
Embodied Question Answering (EQA) requires agents to autonomously explore and understand the environment to answer context-dependent questions. Existing frameworks typically center around the planner, which guides the stopping module, memory module, and answering module for reasoning. In this paper, we propose a memory-centric EQA framework named MemoryEQA. Unlike planner-centric EQA models where the memory module cannot fully interact with other modules, MemoryEQA flexible feeds memory information into all modules, thereby enhancing efficiency and accuracy in handling complex tasks, such as those involving multiple targets across different regions. Specifically, we establish a multi-modal hierarchical memory mechanism, which is divided into global memory that stores language-enhanced scene maps, and local memory that retains historical observations and state information. When performing EQA tasks, the multi-modal large language model is leveraged to convert memory information into the required input formats for injection into different modules. To evaluate EQA models' memory capabilities, we constructed the MT-HM3D dataset based on HM3D, comprising 1,587 question-answer pairs involving multiple targets across various regions, which requires agents to maintain memory of exploration-acquired target information. Experimental results on HM-EQA, MT-HM3D, and OpenEQA demonstrate the effectiveness of our framework, where a 19.8% performance gain on MT-HM3D compared to baseline model further underscores memory capability's pivotal role in resolving complex tasks.