 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStreaming Video Model
Mar 30, 2023



Video understanding tasks have traditionally been modeled by two separate architectures, specially tailored for two distinct tasks. Sequence-based video tasks, such as action recognition, use a video backbone to directly extract spatiotemporal features, while frame-based video tasks, such as multiple object tracking (MOT), rely on single fixed-image backbone to extract spatial features. In contrast, we propose to unify video understanding tasks into one novel streaming video architecture, referred to as Streaming Vision Transformer (S-ViT). S-ViT first produces frame-level features with a memory-enabled temporally-aware spatial encoder to serve the frame-based video tasks. Then the frame features are input into a task-related temporal decoder to obtain spatiotemporal features for sequence-based tasks. The efficiency and efficacy of S-ViT is demonstrated by the state-of-the-art accuracy in the sequence-based action recognition task and the competitive advantage over conventional architecture in the frame-based MOT task. We believe that the concept of streaming video model and the implementation of S-ViT are solid steps towards a unified deep learning architecture for video understanding. Code will be available at https://github.com/yuzhms/Streaming-Video-Model.
Spatial-Aware Token for Weakly Supervised Object Localization
Mar 18, 2023



Weakly supervised object localization (WSOL) is a challenging task aiming to localize objects with only image-level supervision. Recent works apply visual transformer to WSOL and achieve significant success by exploiting the long-range feature dependency in self-attention mechanism. However, existing transformer-based methods synthesize the classification feature maps as the localization map, which leads to optimization conflicts between classification and localization tasks. To address this problem, we propose to learn a task-specific spatial-aware token (SAT) to condition localization in a weakly supervised manner. Specifically, a spatial token is first introduced in the input space to aggregate representations for localization task. Then a spatial aware attention module is constructed, which allows spatial token to generate foreground probabilities of different patches by querying and to extract localization knowledge from the classification task. Besides, for the problem of sparse and unbalanced pixel-level supervision obtained from the image-level label, two spatial constraints, including batch area loss and normalization loss, are designed to compensate and enhance this supervision. Experiments show that the proposed SAT achieves state-of-the-art performance on both CUB-200 and ImageNet, with 98.45% and 73.13% GT-known Loc, respectively. Even under the extreme setting of using only 1 image per class from ImageNet for training, SAT already exceeds the SOTA method by 2.1% GT-known Loc. Code and models are available at https://github.com/wpy1999/SAT.
Grounding 3D Object Affordance from 2D Interactions in Images
Mar 18, 2023Grounding 3D object affordance seeks to locate objects' ''action possibilities'' regions in the 3D space, which serves as a link between perception and operation for embodied agents. Existing studies primarily focus on connecting visual affordances with geometry structures, e.g. relying on annotations to declare interactive regions of interest on the object and establishing a mapping between the regions and affordances. However, the essence of learning object affordance is to understand how to use it, and the manner that detaches interactions is limited in generalization. Normally, humans possess the ability to perceive object affordances in the physical world through demonstration images or videos. Motivated by this, we introduce a novel task setting: grounding 3D object affordance from 2D interactions in images, which faces the challenge of anticipating affordance through interactions of different sources. To address this problem, we devise a novel Interaction-driven 3D Affordance Grounding Network (IAG), which aligns the region feature of objects from different sources and models the interactive contexts for 3D object affordance grounding. Besides, we collect a Point-Image Affordance Dataset (PIAD) to support the proposed task. Comprehensive experiments on PIAD demonstrate the reliability of the proposed task and the superiority of our method. The project is available at https://github.com/yyvhang/IAGNet.
Neural Dependencies Emerging from Learning Massive Categories
Nov 21, 2022



This work presents two astonishing findings on neural networks learned for large-scale image classification. 1) Given a well-trained model, the logits predicted for some category can be directly obtained by linearly combining the predictions of a few other categories, which we call \textbf{neural dependency}. 2) Neural dependencies exist not only within a single model, but even between two independently learned models, regardless of their architectures. Towards a theoretical analysis of such phenomena, we demonstrate that identifying neural dependencies is equivalent to solving the Covariance Lasso (CovLasso) regression problem proposed in this paper. Through investigating the properties of the problem solution, we confirm that neural dependency is guaranteed by a redundant logit covariance matrix, which condition is easily met given massive categories, and that neural dependency is highly sparse, implying that one category correlates to only a few others. We further empirically show the potential of neural dependencies in understanding internal data correlations, generalizing models to unseen categories, and improving model robustness with a dependency-derived regularizer. Code for this work will be made publicly available.
Entity-enhanced Adaptive Reconstruction Network for Weakly Supervised Referring Expression Grounding
Jul 18, 2022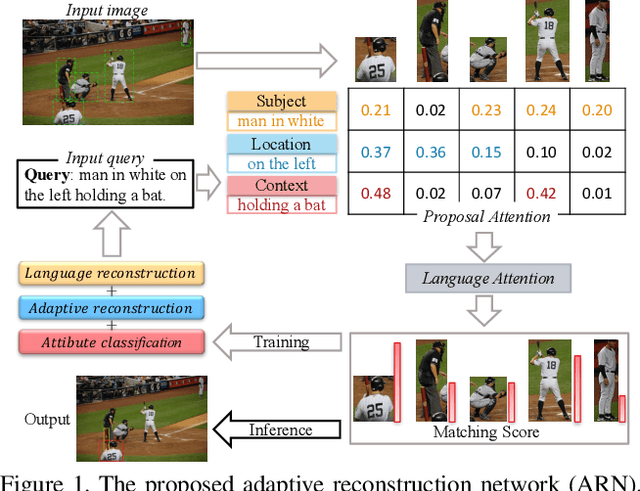
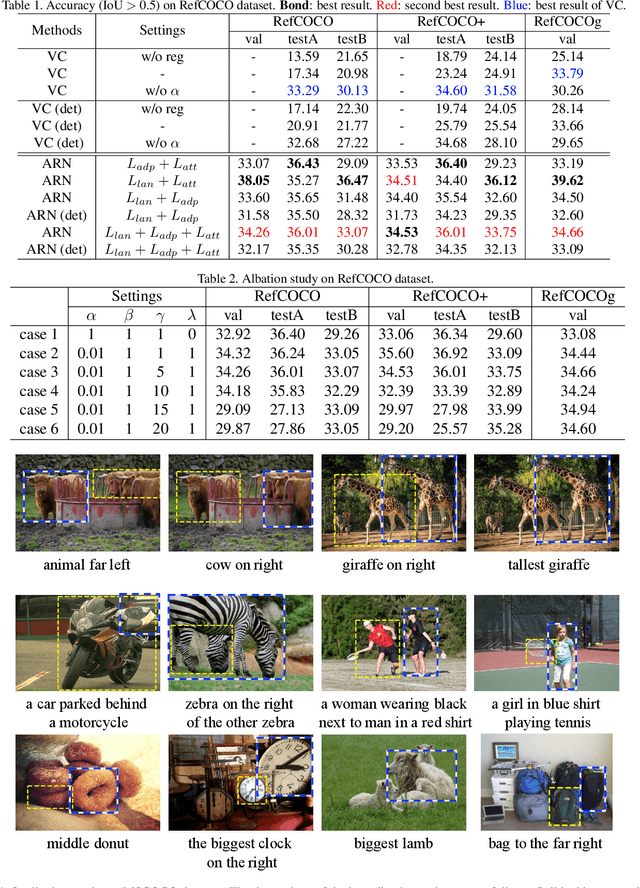
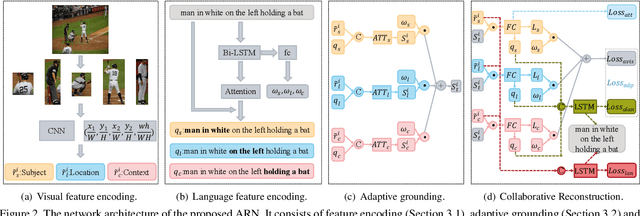
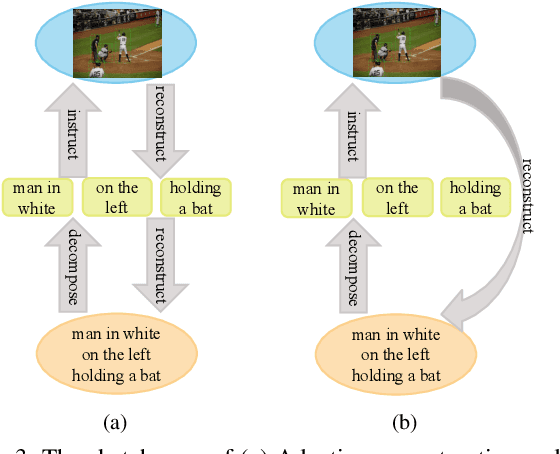
Weakly supervised Referring Expression Grounding (REG) aims to ground a particular target in an image described by a language expression while lacking the correspondence between target and expression. Two main problems exist in weakly supervised REG. First, the lack of region-level annotations introduces ambiguities between proposals and queries. Second, most previous weakly supervised REG methods ignore the discriminative location and context of the referent, causing difficulties in distinguishing the target from other same-category objects. To address the above challenges, we design an entity-enhanced adaptive reconstruction network (EARN). Specifically, EARN includes three modules: entity enhancement, adaptive grounding, and collaborative reconstruction. In entity enhancement, we calculate semantic similarity as supervision to select the candidate proposals. Adaptive grounding calculates the ranking score of candidate proposals upon subject, location and context with hierarchical attention. Collaborative reconstruction measures the ranking result from three perspectives: adaptive reconstruction, language reconstruction and attribute classification. The adaptive mechanism helps to alleviate the variance of different referring expressions. Experiments on five datasets show EARN outperforms existing state-of-the-art methods. Qualitative results demonstrate that the proposed EARN can better handle the situation where multiple objects of a particular category are situated together.
Enhancement by Your Aesthetic: An Intelligible Unsupervised Personalized Enhancer for Low-Light Images
Jul 15, 2022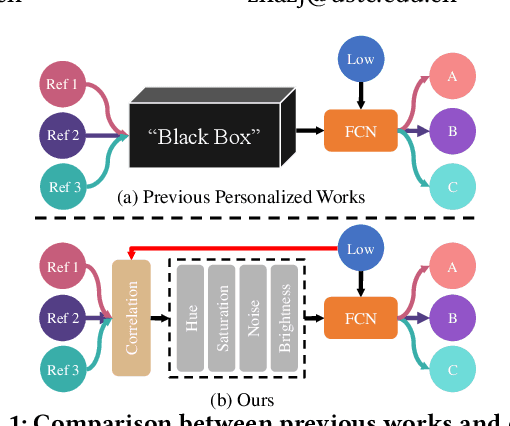
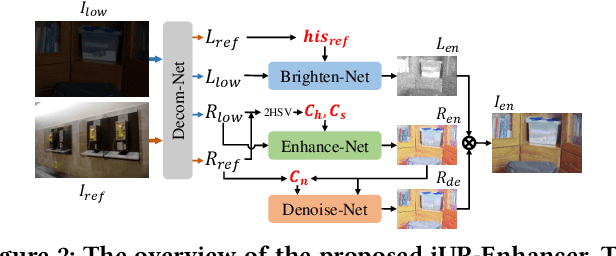
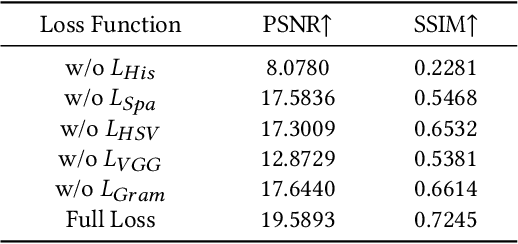
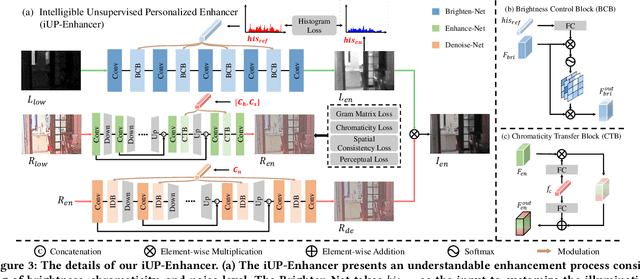
Low-light image enhancement is an inherently subjective process whose targets vary with the user's aesthetic. Motivated by this, several personalized enhancement methods have been investigated. However, the enhancement process based on user preferences in these techniques is invisible, i.e., a "black box". In this work, we propose an intelligible unsupervised personalized enhancer (iUPEnhancer) for low-light images, which establishes the correlations between the low-light and the unpaired reference images with regard to three user-friendly attributions (brightness, chromaticity, and noise). The proposed iUP-Enhancer is trained with the guidance of these correlations and the corresponding unsupervised loss functions. Rather than a "black box" process, our iUP-Enhancer presents an intelligible enhancement process with the above attributions. Extensive experiments demonstrate that the proposed algorithm produces competitive qualitative and quantitative results while maintaining excellent flexibility and scalability. This can be validated by personalization with single/multiple references, cross-attribution references, or merely adjusting parameters.
Rank Diminishing in Deep Neural Networks
Jun 13, 2022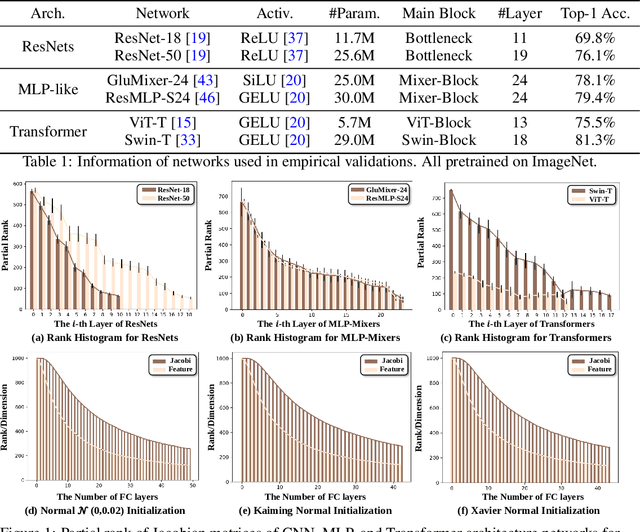
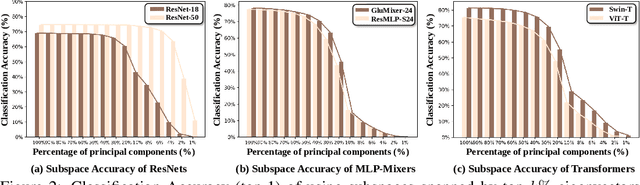
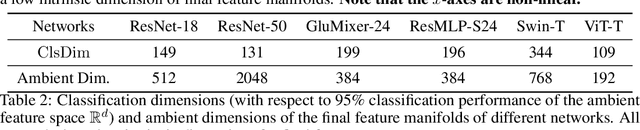
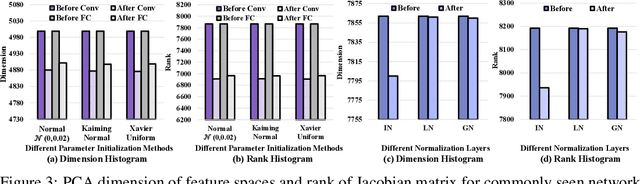
The rank of neural networks measures information flowing across layers. It is an instance of a key structural condition that applies across broad domains of machine learning. In particular, the assumption of low-rank feature representations leads to algorithmic developments in many architectures. For neural networks, however, the intrinsic mechanism that yields low-rank structures remains vague and unclear. To fill this gap, we perform a rigorous study on the behavior of network rank, focusing particularly on the notion of rank deficiency. We theoretically establish a universal monotonic decreasing property of network rank from the basic rules of differential and algebraic composition, and uncover rank deficiency of network blocks and deep function coupling. By virtue of our numerical tools, we provide the first empirical analysis of the per-layer behavior of network rank in practical settings, i.e., ResNets, deep MLPs, and Transformers on ImageNet. These empirical results are in direct accord with our theory. Furthermore, we reveal a novel phenomenon of independence deficit caused by the rank deficiency of deep networks, where classification confidence of a given category can be linearly decided by the confidence of a handful of other categories. The theoretical results of this work, together with the empirical findings, may advance understanding of the inherent principles of deep neural networks.
Automatic Relation-aware Graph Network Proliferation
May 31, 2022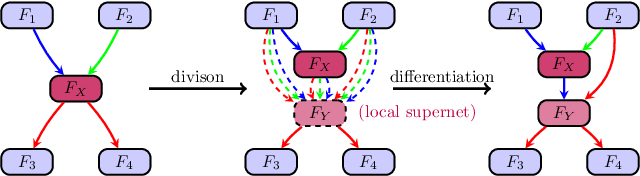
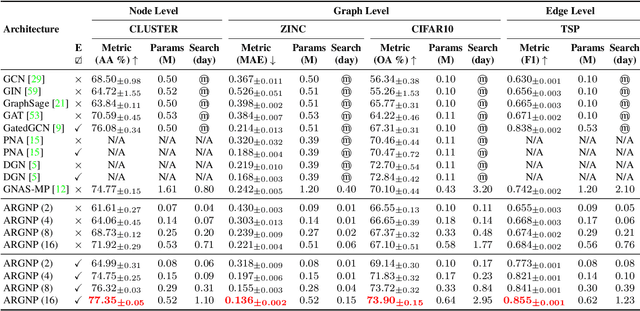
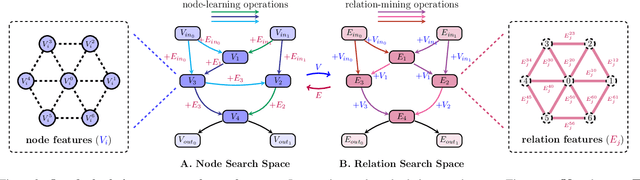
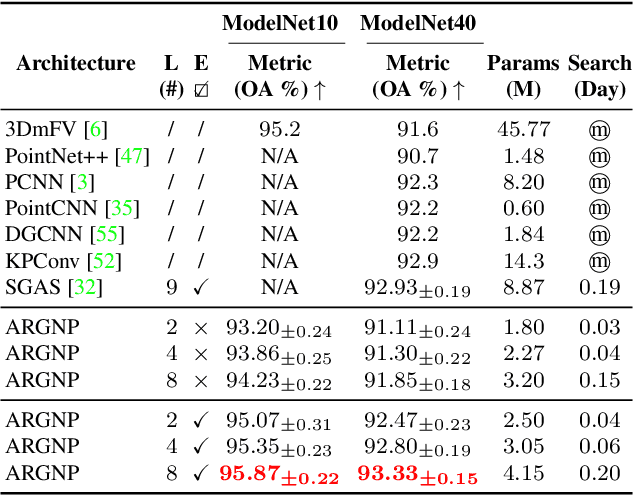
Graph neural architecture search has sparked much attention as Graph Neural Networks (GNNs) have shown powerful reasoning capability in many relational tasks. However, the currently used graph search space overemphasizes learning node features and neglects mining hierarchical relational information. Moreover, due to diverse mechanisms in the message passing, the graph search space is much larger than that of CNNs. This hinders the straightforward application of classical search strategies for exploring complicated graph search space. We propose Automatic Relation-aware Graph Network Proliferation (ARGNP) for efficiently searching GNNs with a relation-guided message passing mechanism. Specifically, we first devise a novel dual relation-aware graph search space that comprises both node and relation learning operations. These operations can extract hierarchical node/relational information and provide anisotropic guidance for message passing on a graph. Second, analogous to cell proliferation, we design a network proliferation search paradigm to progressively determine the GNN architectures by iteratively performing network division and differentiation. The experiments on six datasets for four graph learning tasks demonstrate that GNNs produced by our method are superior to the current state-of-the-art hand-crafted and search-based GNNs. Codes are available at https://github.com/phython96/ARGNP.
Principled Knowledge Extrapolation with GANs
May 21, 2022
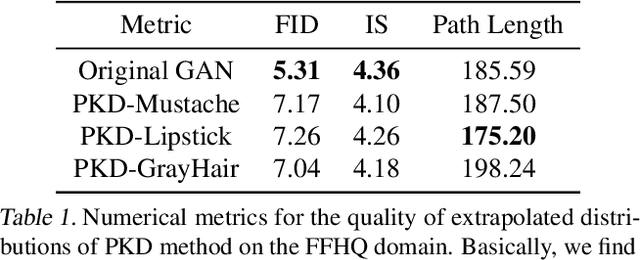
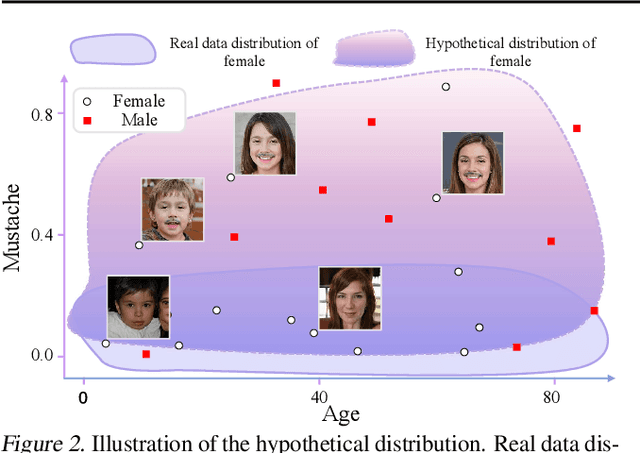

Human can extrapolate well, generalize daily knowledge into unseen scenarios, raise and answer counterfactual questions. To imitate this ability via generative models, previous works have extensively studied explicitly encoding Structural Causal Models (SCMs) into architectures of generator networks. This methodology, however, limits the flexibility of the generator as they must be carefully crafted to follow the causal graph, and demands a ground truth SCM with strong ignorability assumption as prior, which is a nontrivial assumption in many real scenarios. Thus, many current causal GAN methods fail to generate high fidelity counterfactual results as they cannot easily leverage state-of-the-art generative models. In this paper, we propose to study counterfactual synthesis from a new perspective of knowledge extrapolation, where a given knowledge dimension of the data distribution is extrapolated, but the remaining knowledge is kept indistinguishable from the original distribution. We show that an adversarial game with a closed-form discriminator can be used to address the knowledge extrapolation problem, and a novel principal knowledge descent method can efficiently estimate the extrapolated distribution through the adversarial game. Our method enjoys both elegant theoretical guarantees and superior performance in many scenarios.
Degradation-agnostic Correspondence from Resolution-asymmetric Stereo
Apr 04, 2022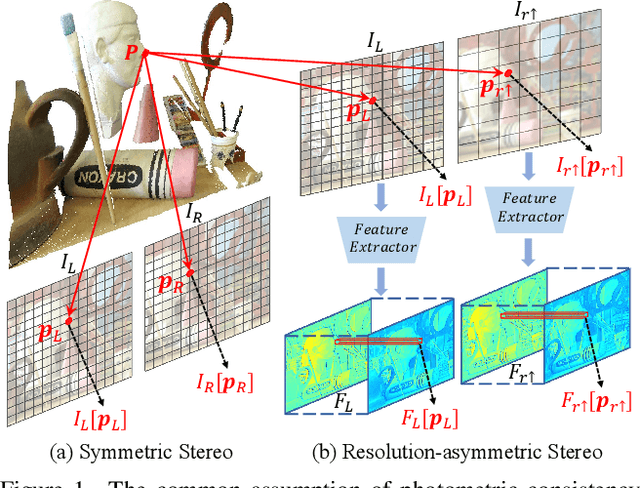
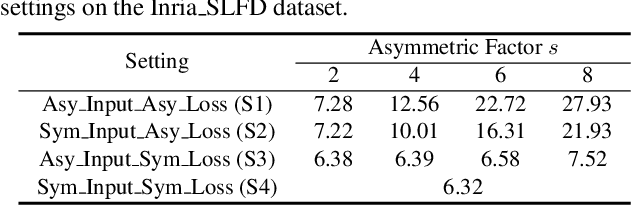
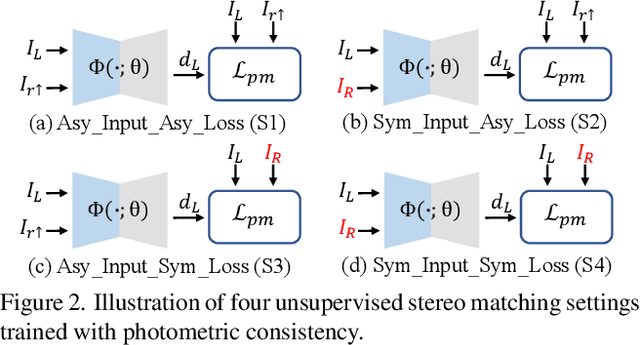
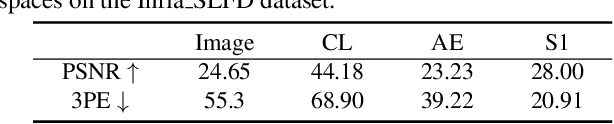
In this paper, we study the problem of stereo matching from a pair of images with different resolutions, e.g., those acquired with a tele-wide camera system. Due to the difficulty of obtaining ground-truth disparity labels in diverse real-world systems, we start from an unsupervised learning perspective. However, resolution asymmetry caused by unknown degradations between two views hinders the effectiveness of the generally assumed photometric consistency. To overcome this challenge, we propose to impose the consistency between two views in a feature space instead of the image space, named feature-metric consistency. Interestingly, we find that, although a stereo matching network trained with the photometric loss is not optimal, its feature extractor can produce degradation-agnostic and matching-specific features. These features can then be utilized to formulate a feature-metric loss to avoid the photometric inconsistency. Moreover, we introduce a self-boosting strategy to optimize the feature extractor progressively, which further strengthens the feature-metric consistency. Experiments on both simulated datasets with various degradations and a self-collected real-world dataset validate the superior performance of the proposed method over existing solutions.