 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplication of Deep Q Learning with Stimulation Results for Elevator Optimization
Sep 30, 2022
This paper presents a methodology for combining programming and mathematics to optimize elevator wait times. Based on simulated user data generated according to the canonical three-peak model of elevator traffic, we first develop a naive model from an intuitive understanding of the logic behind elevators. We take into consideration a general array of features including capacity, acceleration, and maximum wait time thresholds to adequately model realistic circumstances. Using the same evaluation framework, we proceed to develop a Deep Q Learning model in an attempt to match the hard-coded naive approach for elevator control. Throughout the majority of the paper, we work under a Markov Decision Process (MDP) schema, but later explore how the assumption fails to characterize the highly stochastic overall Elevator Group Control System (EGCS).
SPACE-2: Tree-Structured Semi-Supervised Contrastive Pre-training for Task-Oriented Dialog Understanding
Sep 14, 2022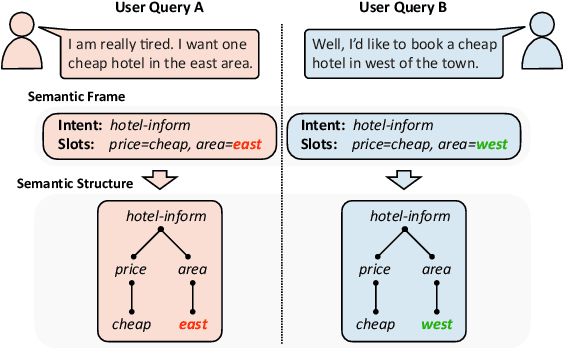
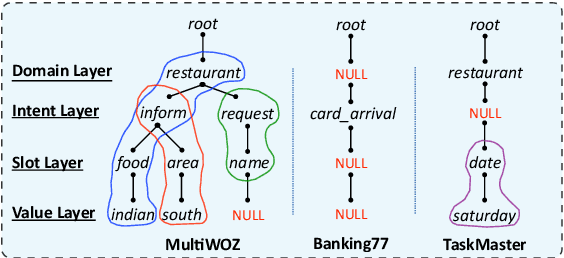
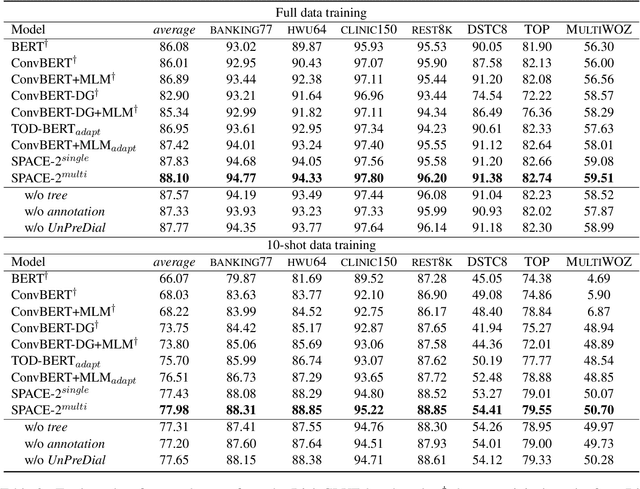
Pre-training methods with contrastive learning objectives have shown remarkable success in dialog understanding tasks. However, current contrastive learning solely considers the self-augmented dialog samples as positive samples and treats all other dialog samples as negative ones, which enforces dissimilar representations even for dialogs that are semantically related. In this paper, we propose SPACE-2, a tree-structured pre-trained conversation model, which learns dialog representations from limited labeled dialogs and large-scale unlabeled dialog corpora via semi-supervised contrastive pre-training. Concretely, we first define a general semantic tree structure (STS) to unify the inconsistent annotation schema across different dialog datasets, so that the rich structural information stored in all labeled data can be exploited. Then we propose a novel multi-view score function to increase the relevance of all possible dialogs that share similar STSs and only push away other completely different dialogs during supervised contrastive pre-training. To fully exploit unlabeled dialogs, a basic self-supervised contrastive loss is also added to refine the learned representations. Experiments show that our method can achieve new state-of-the-art results on the DialoGLUE benchmark consisting of seven datasets and four popular dialog understanding tasks. For reproducibility, we release the code and data at https://github.com/AlibabaResearch/DAMO-ConvAI/tree/main/space-2.
Application of Convolutional Neural Networks with Quasi-Reversibility Method Results for Option Forecasting
Aug 25, 2022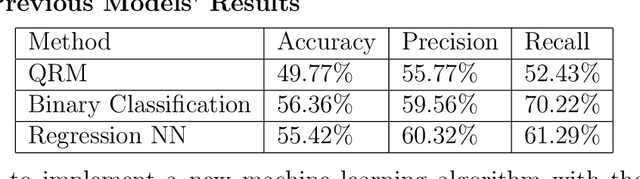
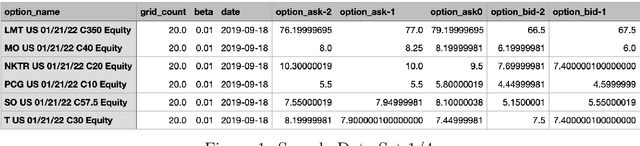
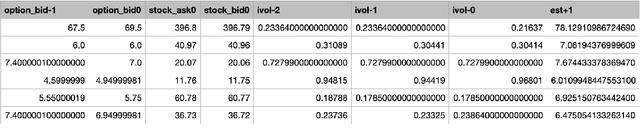
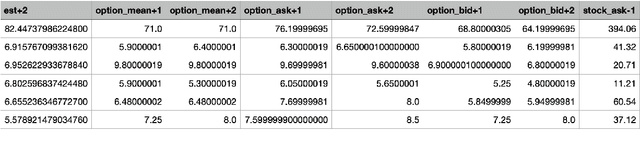
This paper presents a novel way to apply mathematical finance and machine learning (ML) to forecast stock options prices. Following results from the paper Quasi-Reversibility Method and Neural Network Machine Learning to Solution of Black-Scholes Equations (appeared on the AMS Contemporary Mathematics journal), we create and evaluate new empirical mathematical models for the Black-Scholes equation to analyze data for 92,846 companies. We solve the Black-Scholes (BS) equation forwards in time as an ill-posed inverse problem, using the Quasi-Reversibility Method (QRM), to predict option price for the future one day. For each company, we have 13 elements including stock and option daily prices, volatility, minimizer, etc. Because the market is so complicated that there exists no perfect model, we apply ML to train algorithms to make the best prediction. The current stage of research combines QRM with Convolutional Neural Networks (CNN), which learn information across a large number of data points simultaneously. We implement CNN to generate new results by validating and testing on sample market data. We test different ways of applying CNN and compare our CNN models with previous models to see if achieving a higher profit rate is possible.
mPLUG: Effective and Efficient Vision-Language Learning by Cross-modal Skip-connections
May 25, 2022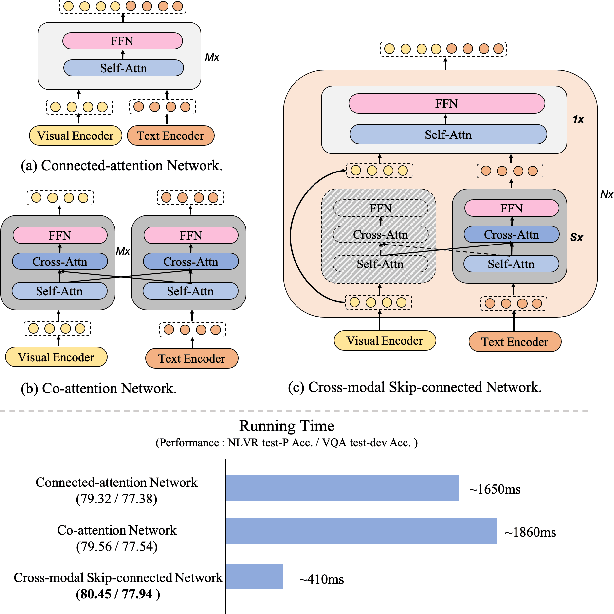
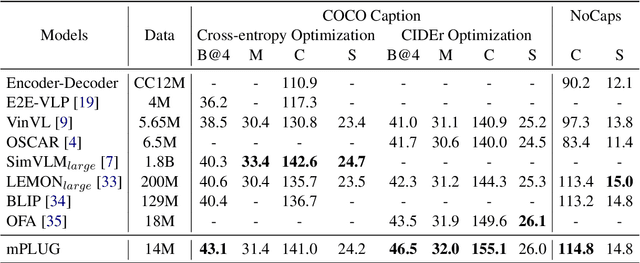
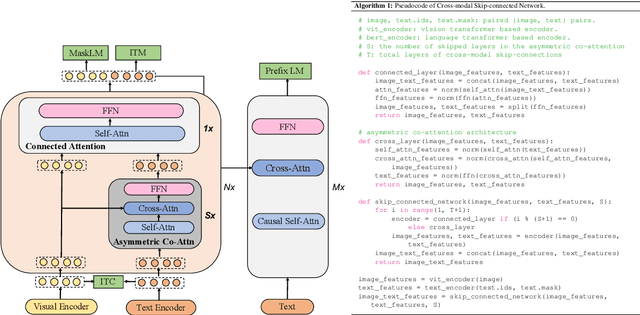
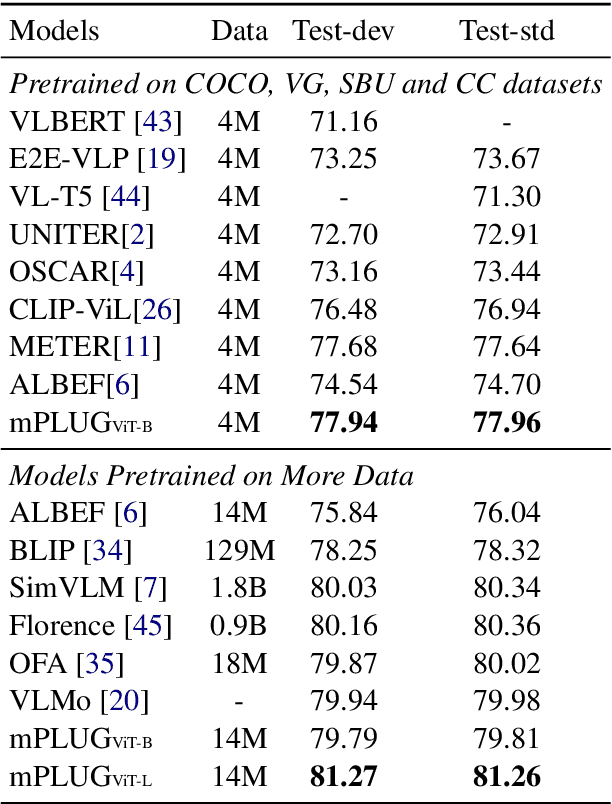
Large-scale pretrained foundation models have been an emerging paradigm for building artificial intelligence (AI) systems, which can be quickly adapted to a wide range of downstream tasks. This paper presents mPLUG, a new vision-language foundation model for both cross-modal understanding and generation. Most existing pre-trained models suffer from the problems of low computational efficiency and information asymmetry brought by the long visual sequence in cross-modal alignment. To address these problems, mPLUG introduces an effective and efficient vision-language architecture with novel cross-modal skip-connections, which creates inter-layer shortcuts that skip a certain number of layers for time-consuming full self-attention on the vision side. mPLUG is pre-trained end-to-end on large-scale image-text pairs with both discriminative and generative objectives. It achieves state-of-the-art results on a wide range of vision-language downstream tasks, such as image captioning, image-text retrieval, visual grounding and visual question answering. mPLUG also demonstrates strong zero-shot transferability when directly transferred to multiple video-language tasks.
GALAXY: A Generative Pre-trained Model for Task-Oriented Dialog with Semi-Supervised Learning and Explicit Policy Injection
Dec 27, 2021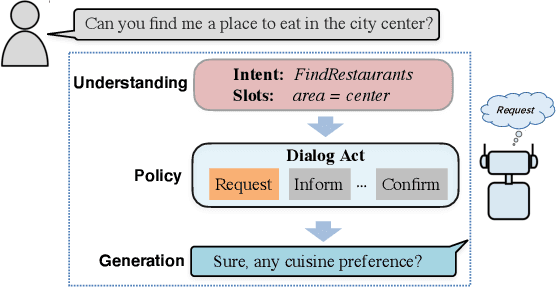

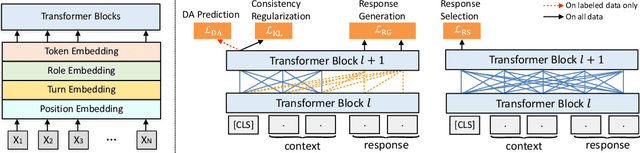
Pre-trained models have proved to be powerful in enhancing task-oriented dialog systems. However, current pre-training methods mainly focus on enhancing dialog understanding and generation tasks while neglecting the exploitation of dialog policy. In this paper, we propose GALAXY, a novel pre-trained dialog model that explicitly learns dialog policy from limited labeled dialogs and large-scale unlabeled dialog corpora via semi-supervised learning. Specifically, we introduce a dialog act prediction task for policy optimization during pre-training and employ a consistency regularization term to refine the learned representation with the help of unlabeled dialogs. We also implement a gating mechanism to weigh suitable unlabeled dialog samples. Empirical results show that GALAXY substantially improves the performance of task-oriented dialog systems, and achieves new state-of-the-art results on benchmark datasets: In-Car, MultiWOZ2.0 and MultiWOZ2.1, improving their end-to-end combined scores by 2.5, 5.3 and 5.5 points, respectively. We also show that GALAXY has a stronger few-shot ability than existing models under various low-resource settings.
Achieving Human Parity on Visual Question Answering
Nov 19, 2021
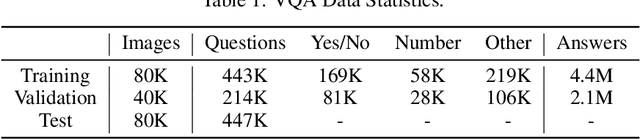
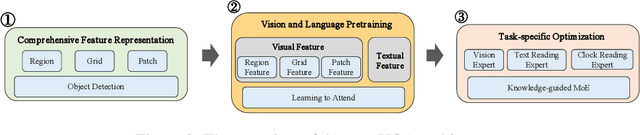
The Visual Question Answering (VQA) task utilizes both visual image and language analysis to answer a textual question with respect to an image. It has been a popular research topic with an increasing number of real-world applications in the last decade. This paper describes our recent research of AliceMind-MMU (ALIbaba's Collection of Encoder-decoders from Machine IntelligeNce lab of Damo academy - MultiMedia Understanding) that obtains similar or even slightly better results than human being does on VQA. This is achieved by systematically improving the VQA pipeline including: (1) pre-training with comprehensive visual and textual feature representation; (2) effective cross-modal interaction with learning to attend; and (3) A novel knowledge mining framework with specialized expert modules for the complex VQA task. Treating different types of visual questions with corresponding expertise needed plays an important role in boosting the performance of our VQA architecture up to the human level. An extensive set of experiments and analysis are conducted to demonstrate the effectiveness of the new research work.
SDCUP: Schema Dependency-Enhanced Curriculum Pre-Training for Table Semantic Parsing
Nov 18, 2021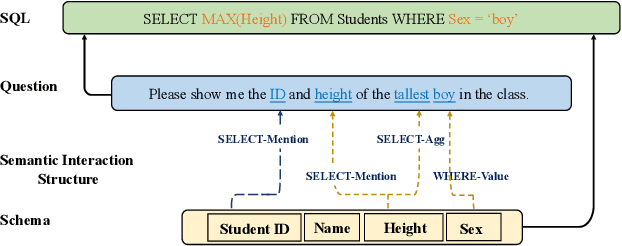
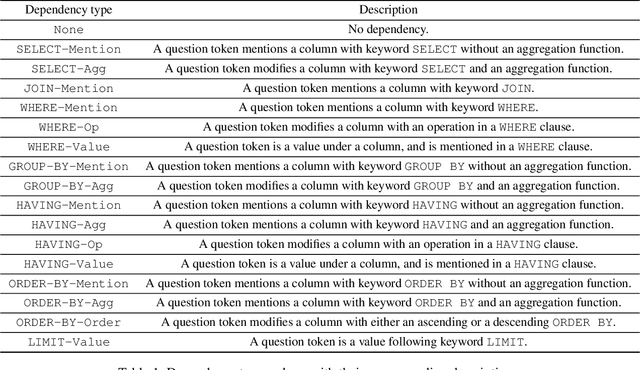
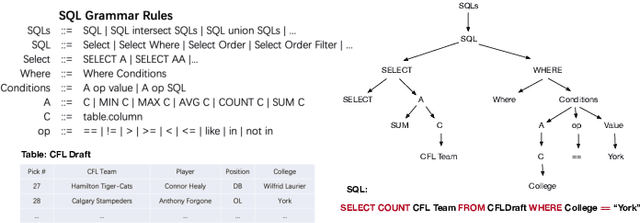

Recently pre-training models have significantly improved the performance of various NLP tasks by leveraging large-scale text corpora to improve the contextual representation ability of the neural network. The large pre-training language model has also been applied in the area of table semantic parsing. However, existing pre-training approaches have not carefully explored explicit interaction relationships between a question and the corresponding database schema, which is a key ingredient for uncovering their semantic and structural correspondence. Furthermore, the question-aware representation learning in the schema grounding context has received less attention in pre-training objective.To alleviate these issues, this paper designs two novel pre-training objectives to impose the desired inductive bias into the learned representations for table pre-training. We further propose a schema-aware curriculum learning approach to mitigate the impact of noise and learn effectively from the pre-training data in an easy-to-hard manner. We evaluate our pre-trained framework by fine-tuning it on two benchmarks, Spider and SQUALL. The results demonstrate the effectiveness of our pre-training objective and curriculum compared to a variety of baselines.
AIBench: Scenario-distilling AI Benchmarking
May 06, 2020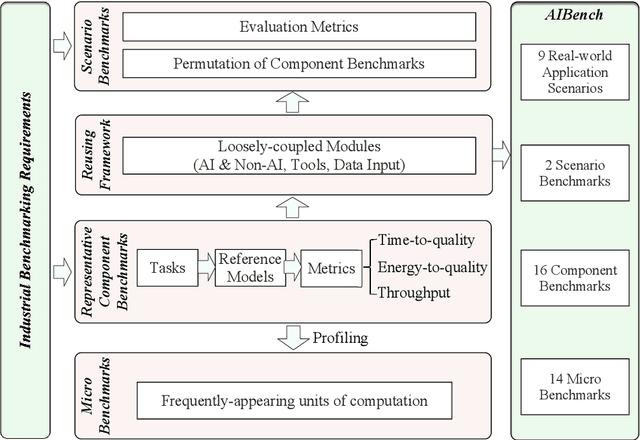
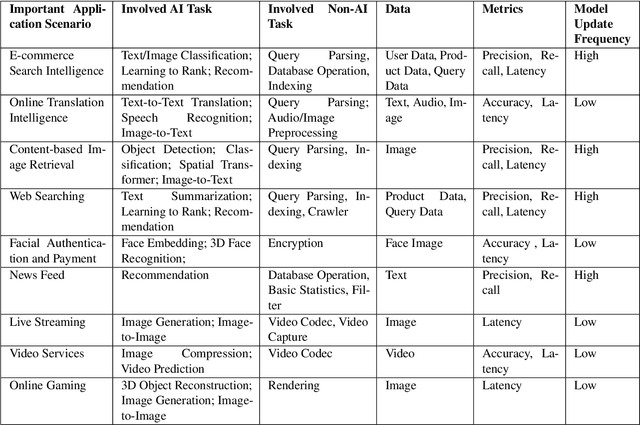
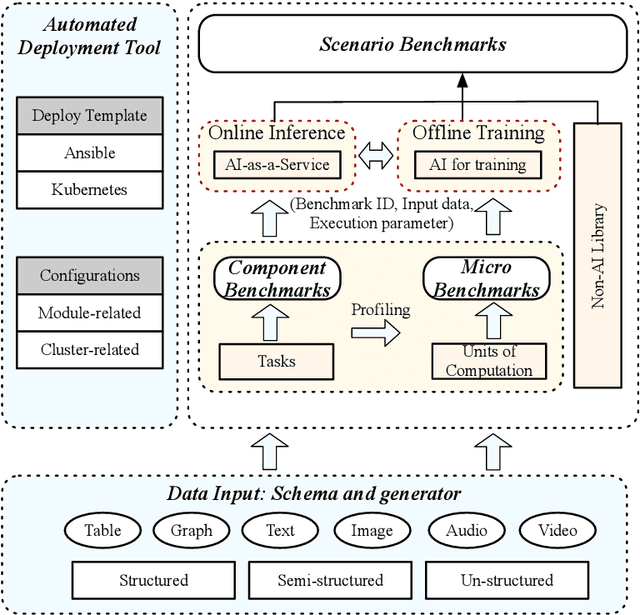
Real-world application scenarios like modern Internet services consist of diversity of AI and non-AI modules with very long and complex execution paths. Using component or micro AI benchmarks alone can lead to error-prone conclusions. This paper proposes a scenario-distilling AI benchmarking methodology. Instead of using real-world applications, we propose the permutations of essential AI and non-AI tasks as a scenario-distilling benchmark. We consider scenario-distilling benchmarks, component and micro benchmarks as three indispensable parts of a benchmark suite. Together with seventeen industry partners, we identify nine important real-world application scenarios. We design and implement a highly extensible, configurable, and flexible benchmark framework. On the basis of the framework, we propose the guideline for building scenario-distilling benchmarks, and present two Internet service AI ones. The preliminary evaluation shows the advantage of scenario-distilling AI benchmarking against using component or micro AI benchmarks alone. The specifications, source code, testbed, and results are publicly available from the web site \url{http://www.benchcouncil.org/AIBench/index.html}.
AIBench: An Industry Standard AI Benchmark Suite from Internet Services
Apr 30, 2020
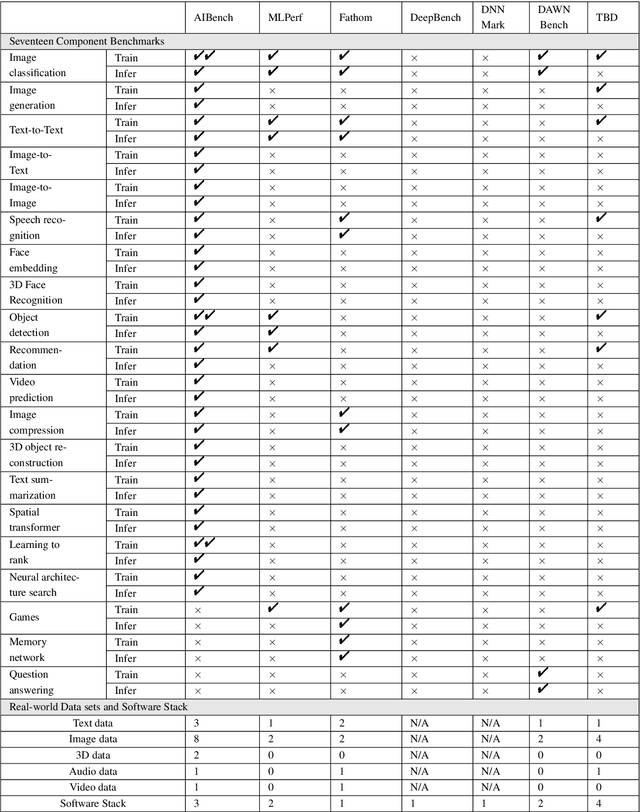
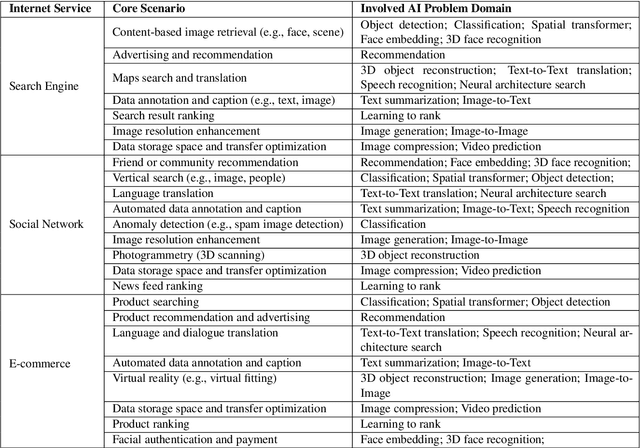
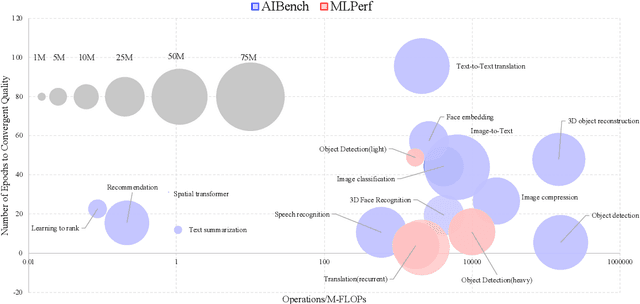
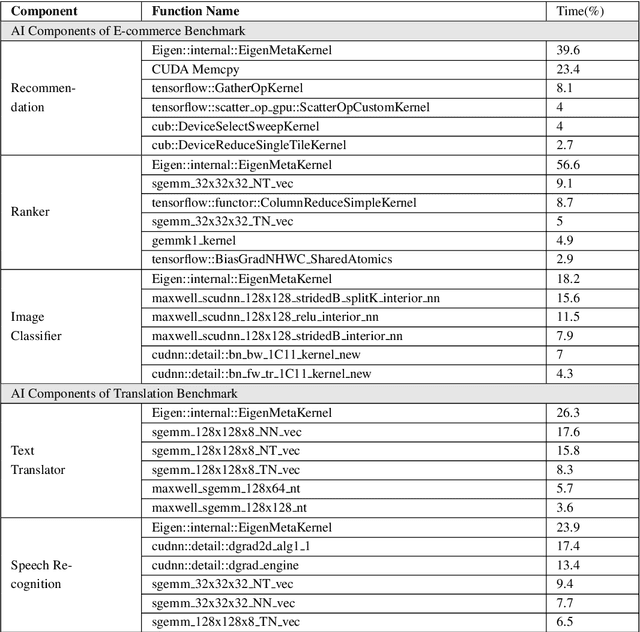
The booming successes of machine learning in different domains boost industry-scale deployments of innovative AI algorithms, systems, and architectures, and thus the importance of benchmarking grows. However, the confidential nature of the workloads, the paramount importance of the representativeness and diversity of benchmarks, and the prohibitive cost of training a state-of-the-art model mutually aggravate the AI benchmarking challenges. In this paper, we present a balanced AI benchmarking methodology for meeting the subtly different requirements of different stages in developing a new system/architecture and ranking/purchasing commercial off-the-shelf ones. Performing an exhaustive survey on the most important AI domain-Internet services with seventeen industry partners, we identify and include seventeen representative AI tasks to guarantee the representativeness and diversity of the benchmarks. Meanwhile, for reducing the benchmarking cost, we select a benchmark subset to a minimum-three tasks-according to the criteria: diversity of model complexity, computational cost, and convergence rate, repeatability, and having widely-accepted metrics or not. We contribute by far the most comprehensive AI benchmark suite-AIBench. The evaluations show AIBench outperforms MLPerf in terms of the diversity and representativeness of model complexity, computational cost, convergent rate, computation and memory access patterns, and hotspot functions. With respect to the AIBench full benchmarks, its subset shortens the benchmarking cost by 41%, while maintaining the primary workload characteristics. The specifications, source code, and performance numbers are publicly available from the web site http://www.benchcouncil.org/AIBench/index.html.
AIBench: An Agile Domain-specific Benchmarking Methodology and an AI Benchmark Suite
Feb 17, 2020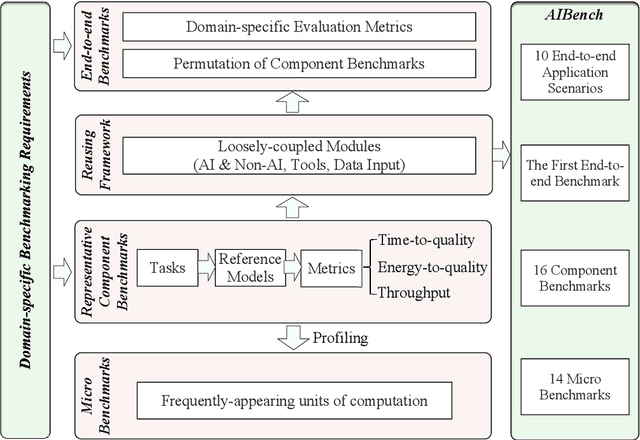
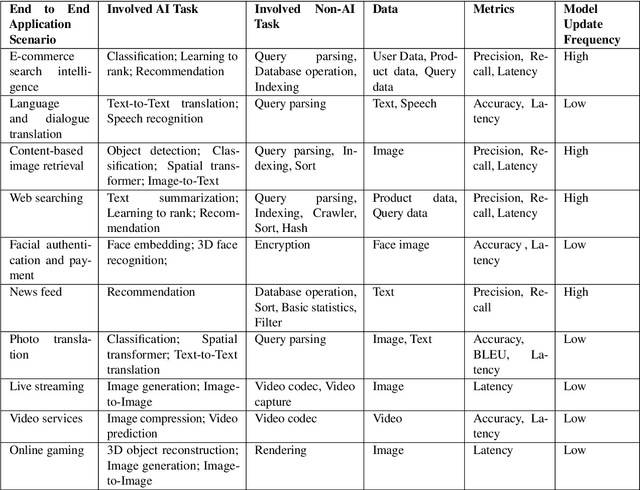
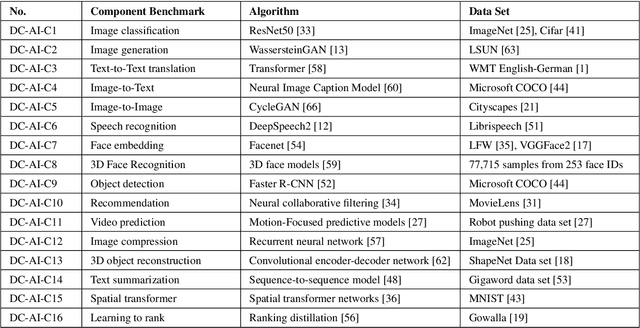
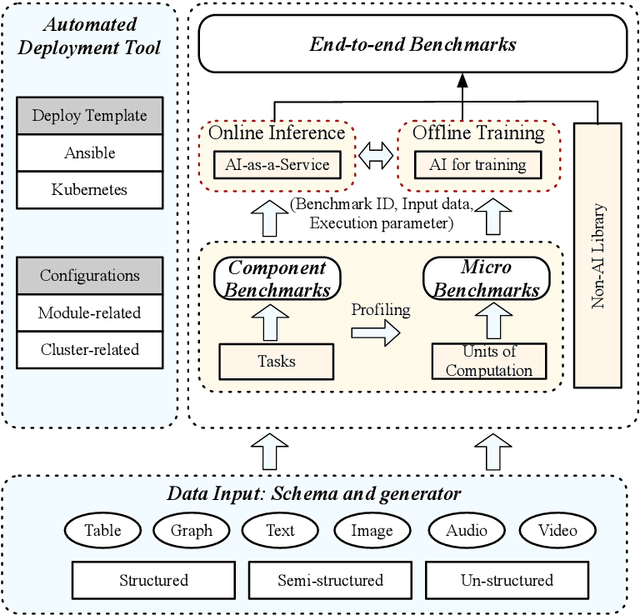
Domain-specific software and hardware co-design is encouraging as it is much easier to achieve efficiency for fewer tasks. Agile domain-specific benchmarking speeds up the process as it provides not only relevant design inputs but also relevant metrics, and tools. Unfortunately, modern workloads like Big data, AI, and Internet services dwarf the traditional one in terms of code size, deployment scale, and execution path, and hence raise serious benchmarking challenges. This paper proposes an agile domain-specific benchmarking methodology. Together with seventeen industry partners, we identify ten important end-to-end application scenarios, among which sixteen representative AI tasks are distilled as the AI component benchmarks. We propose the permutations of essential AI and non-AI component benchmarks as end-to-end benchmarks. An end-to-end benchmark is a distillation of the essential attributes of an industry-scale application. We design and implement a highly extensible, configurable, and flexible benchmark framework, on the basis of which, we propose the guideline for building end-to-end benchmarks, and present the first end-to-end Internet service AI benchmark. The preliminary evaluation shows the value of our benchmark suite---AIBench against MLPerf and TailBench for hardware and software designers, micro-architectural researchers, and code developers. The specifications, source code, testbed, and results are publicly available from the web site \url{http://www.benchcouncil.org/AIBench/index.html}.