 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMindGYM: Enhancing Vision-Language Models via Synthetic Self-Challenging Questions
Mar 12, 2025



Large vision-language models (VLMs) face challenges in achieving robust, transferable reasoning abilities due to reliance on labor-intensive manual instruction datasets or computationally expensive self-supervised methods. To address these issues, we introduce MindGYM, a framework that enhances VLMs through synthetic self-challenging questions, consisting of three stages: (1) Seed Single-Hop Question Synthesis, generating cognitive questions across textual (e.g., logical deduction) and multimodal contexts (e.g., diagram-based queries) spanning eight semantic areas like ethical analysis; (2) Challenging Multi-Hop Question Synthesis, combining seed questions via diverse principles like bridging, visual-textual alignment, to create multi-step problems demanding deeper reasoning; and (3) Thinking-Induced Curriculum Fine-Tuning, a structured pipeline that progressively trains the model from scaffolded reasoning to standalone inference. By leveraging the model's self-synthesis capability, MindGYM achieves high data efficiency (e.g., +16% gains on MathVision-Mini with only 400 samples), computational efficiency (reducing both training and inference costs), and robust generalization across tasks. Extensive evaluations on seven benchmarks demonstrate superior performance over strong baselines, with notable improvements (+15.77% win rates) in reasoning depth and breadth validated via GPT-based scoring. MindGYM underscores the viability of self-challenging for refining VLM capabilities while minimizing human intervention and resource demands. Code and data are released to advance multimodal reasoning research.
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
Mar 11, 2025DeepSeek-R1-Zero has successfully demonstrated the emergence of reasoning capabilities in LLMs purely through Reinforcement Learning (RL). Inspired by this breakthrough, we explore how RL can be utilized to enhance the reasoning capability of MLLMs. However, direct training with RL struggles to activate complex reasoning capabilities such as questioning and reflection in MLLMs, due to the absence of substantial high-quality multimodal reasoning data. To address this issue, we propose the reasoning MLLM, Vision-R1, to improve multimodal reasoning capability. Specifically, we first construct a high-quality multimodal CoT dataset without human annotations by leveraging an existing MLLM and DeepSeek-R1 through modality bridging and data filtering to obtain a 200K multimodal CoT dataset, Vision-R1-cold dataset. It serves as cold-start initialization data for Vision-R1. To mitigate the optimization challenges caused by overthinking after cold start, we propose Progressive Thinking Suppression Training (PTST) strategy and employ Group Relative Policy Optimization (GRPO) with the hard formatting result reward function to gradually refine the model's ability to learn correct and complex reasoning processes on a 10K multimodal math dataset. Comprehensive experiments show our model achieves an average improvement of $\sim$6% across various multimodal math reasoning benchmarks. Vision-R1-7B achieves a 73.5% accuracy on the widely used MathVista benchmark, which is only 0.4% lower than the leading reasoning model, OpenAI O1. The datasets and code will be released in: https://github.com/Osilly/Vision-R1 .
Parametric Value Approximation for General-sum Differential Games with State Constraints
Mar 10, 2025General-sum differential games can approximate values solved by Hamilton-Jacobi-Isaacs (HJI) equations for efficient inference when information is incomplete. However, solving such games through conventional methods encounters the curse of dimensionality (CoD). Physics-informed neural networks (PINNs) offer a scalable approach to alleviate the CoD and approximate values, but there exist convergence issues for value approximations through vanilla PINNs when state constraints lead to values with large Lipschitz constants, particularly in safety-critical applications. In addition to addressing CoD, it is necessary to learn a generalizable value across a parametric space of games, rather than training multiple ones for each specific player-type configuration. To overcome these challenges, we propose a Hybrid Neural Operator (HNO), which is an operator that can map parameter functions for games to value functions. HNO leverages informative supervised data and samples PDE-driven data across entire spatial-temporal space for model refinement. We evaluate HNO on 9D and 13D scenarios with nonlinear dynamics and state constraints, comparing it against a Supervised Neural Operator (a variant of DeepONet). Under the same computational budget and training data, HNO outperforms SNO for safety performance. This work provides a step toward scalable and generalizable value function approximation, enabling real-time inference for complex human-robot or multi-agent interactions.
VLRMBench: A Comprehensive and Challenging Benchmark for Vision-Language Reward Models
Mar 10, 2025



Although large visual-language models (LVLMs) have demonstrated strong performance in multimodal tasks, errors may occasionally arise due to biases during the reasoning process. Recently, reward models (RMs) have become increasingly pivotal in the reasoning process. Specifically, process RMs evaluate each reasoning step, outcome RMs focus on the assessment of reasoning results, and critique RMs perform error analysis on the entire reasoning process, followed by corrections. However, existing benchmarks for vision-language RMs (VLRMs) typically assess only a single aspect of their capabilities (e.g., distinguishing between two answers), thus limiting the all-round evaluation and restricting the development of RMs in the visual-language domain. To address this gap, we propose a comprehensive and challenging benchmark, dubbed as VLRMBench, encompassing 12,634 questions. VLRMBench is constructed based on three distinct types of datasets, covering mathematical reasoning, hallucination understanding, and multi-image understanding. We design 12 tasks across three major categories, focusing on evaluating VLRMs in the aspects of process understanding, outcome judgment, and critique generation. Extensive experiments are conducted on 21 open-source models and 5 advanced closed-source models, highlighting the challenges posed by VLRMBench. For instance, in the `Forecasting Future', a binary classification task, the advanced GPT-4o achieves only a 76.0% accuracy. Additionally, we perform comprehensive analytical studies, offering valuable insights for the future development of VLRMs. We anticipate that VLRMBench will serve as a pivotal benchmark in advancing VLRMs. Code and datasets will be available at https://github.com/JCruan519/VLRMBench.
FedSemiDG: Domain Generalized Federated Semi-supervised Medical Image Segmentation
Jan 13, 2025Medical image segmentation is challenging due to the diversity of medical images and the lack of labeled data, which motivates recent developments in federated semi-supervised learning (FSSL) to leverage a large amount of unlabeled data from multiple centers for model training without sharing raw data. However, what remains under-explored in FSSL is the domain shift problem which may cause suboptimal model aggregation and low effectivity of the utilization of unlabeled data, eventually leading to unsatisfactory performance in unseen domains. In this paper, we explore this previously ignored scenario, namely domain generalized federated semi-supervised learning (FedSemiDG), which aims to learn a model in a distributed manner from multiple domains with limited labeled data and abundant unlabeled data such that the model can generalize well to unseen domains. We present a novel framework, Federated Generalization-Aware SemiSupervised Learning (FGASL), to address the challenges in FedSemiDG by effectively tackling critical issues at both global and local levels. Globally, we introduce Generalization-Aware Aggregation (GAA), assigning adaptive weights to local models based on their generalization performance. Locally, we use a Dual-Teacher Adaptive Pseudo Label Refinement (DR) strategy to combine global and domain-specific knowledge, generating more reliable pseudo labels. Additionally, Perturbation-Invariant Alignment (PIA) enforces feature consistency under perturbations, promoting domain-invariant learning. Extensive experiments on three medical segmentation tasks (cardiac MRI, spine MRI and bladder cancer MRI) demonstrate that our method significantly outperforms state-of-the-art FSSL and domain generalization approaches, achieving robust generalization on unseen domains.
VLABench: A Large-Scale Benchmark for Language-Conditioned Robotics Manipulation with Long-Horizon Reasoning Tasks
Dec 24, 2024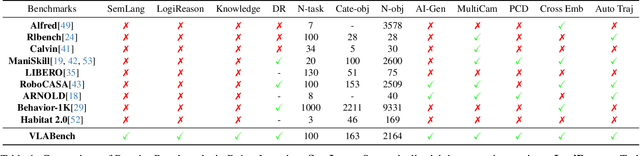
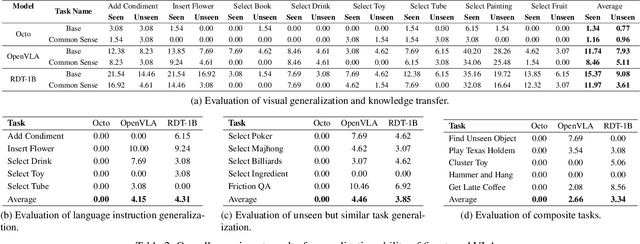

General-purposed embodied agents are designed to understand the users' natural instructions or intentions and act precisely to complete universal tasks. Recently, methods based on foundation models especially Vision-Language-Action models (VLAs) have shown a substantial potential to solve language-conditioned manipulation (LCM) tasks well. However, existing benchmarks do not adequately meet the needs of VLAs and relative algorithms. To better define such general-purpose tasks in the context of LLMs and advance the research in VLAs, we present VLABench, an open-source benchmark for evaluating universal LCM task learning. VLABench provides 100 carefully designed categories of tasks, with strong randomization in each category of task and a total of 2000+ objects. VLABench stands out from previous benchmarks in four key aspects: 1) tasks requiring world knowledge and common sense transfer, 2) natural language instructions with implicit human intentions rather than templates, 3) long-horizon tasks demanding multi-step reasoning, and 4) evaluation of both action policies and language model capabilities. The benchmark assesses multiple competencies including understanding of mesh\&texture, spatial relationship, semantic instruction, physical laws, knowledge transfer and reasoning, etc. To support the downstream finetuning, we provide high-quality training data collected via an automated framework incorporating heuristic skills and prior information. The experimental results indicate that both the current state-of-the-art pretrained VLAs and the workflow based on VLMs face challenges in our tasks.
THeGCN: Temporal Heterophilic Graph Convolutional Network
Dec 21, 2024Graph Neural Networks (GNNs) have exhibited remarkable efficacy in diverse graph learning tasks, particularly on static homophilic graphs. Recent attention has pivoted towards more intricate structures, encompassing (1) static heterophilic graphs encountering the edge heterophily issue in the spatial domain and (2) event-based continuous graphs in the temporal domain. State-of-the-art (SOTA) has been concurrently addressing these two lines of work but tends to overlook the presence of heterophily in the temporal domain, constituting the temporal heterophily issue. Furthermore, we highlight that the edge heterophily issue and the temporal heterophily issue often co-exist in event-based continuous graphs, giving rise to the temporal edge heterophily challenge. To tackle this challenge, this paper first introduces the temporal edge heterophily measurement. Subsequently, we propose the Temporal Heterophilic Graph Convolutional Network (THeGCN), an innovative model that incorporates the low/high-pass graph signal filtering technique to accurately capture both edge (spatial) heterophily and temporal heterophily. Specifically, the THeGCN model consists of two key components: a sampler and an aggregator. The sampler selects events relevant to a node at a given moment. Then, the aggregator executes message-passing, encoding temporal information, node attributes, and edge attributes into node embeddings. Extensive experiments conducted on 5 real-world datasets validate the efficacy of THeGCN.
Unlocking the Potential of Weakly Labeled Data: A Co-Evolutionary Learning Framework for Abnormality Detection and Report Generation
Dec 18, 2024



Anatomical abnormality detection and report generation of chest X-ray (CXR) are two essential tasks in clinical practice. The former aims at localizing and characterizing cardiopulmonary radiological findings in CXRs, while the latter summarizes the findings in a detailed report for further diagnosis and treatment. Existing methods often focused on either task separately, ignoring their correlation. This work proposes a co-evolutionary abnormality detection and report generation (CoE-DG) framework. The framework utilizes both fully labeled (with bounding box annotations and clinical reports) and weakly labeled (with reports only) data to achieve mutual promotion between the abnormality detection and report generation tasks. Specifically, we introduce a bi-directional information interaction strategy with generator-guided information propagation (GIP) and detector-guided information propagation (DIP). For semi-supervised abnormality detection, GIP takes the informative feature extracted by the generator as an auxiliary input to the detector and uses the generator's prediction to refine the detector's pseudo labels. We further propose an intra-image-modal self-adaptive non-maximum suppression module (SA-NMS). This module dynamically rectifies pseudo detection labels generated by the teacher detection model with high-confidence predictions by the student.Inversely, for report generation, DIP takes the abnormalities' categories and locations predicted by the detector as input and guidance for the generator to improve the generated reports.
Intent-driven In-context Learning for Few-shot Dialogue State Tracking
Dec 04, 2024



Dialogue state tracking (DST) plays an essential role in task-oriented dialogue systems. However, user's input may contain implicit information, posing significant challenges for DST tasks. Additionally, DST data includes complex information, which not only contains a large amount of noise unrelated to the current turn, but also makes constructing DST datasets expensive. To address these challenges, we introduce Intent-driven In-context Learning for Few-shot DST (IDIC-DST). By extracting user's intent, we propose an Intent-driven Dialogue Information Augmentation module to augment the dialogue information, which can track dialogue states more effectively. Moreover, we mask noisy information from DST data and rewrite user's input in the Intent-driven Examples Retrieval module, where we retrieve similar examples. We then utilize a pre-trained large language model to update the dialogue state using the augmented dialogue information and examples. Experimental results demonstrate that IDIC-DST achieves state-of-the-art performance in few-shot settings on MultiWOZ 2.1 and MultiWOZ 2.4 datasets.
Natural Language Understanding and Inference with MLLM in Visual Question Answering: A Survey
Nov 26, 2024



Visual Question Answering (VQA) is a challenge task that combines natural language processing and computer vision techniques and gradually becomes a benchmark test task in multimodal large language models (MLLMs). The goal of our survey is to provide an overview of the development of VQA and a detailed description of the latest models with high timeliness. This survey gives an up-to-date synthesis of natural language understanding of images and text, as well as the knowledge reasoning module based on image-question information on the core VQA tasks. In addition, we elaborate on recent advances in extracting and fusing modal information with vision-language pretraining models and multimodal large language models in VQA. We also exhaustively review the progress of knowledge reasoning in VQA by detailing the extraction of internal knowledge and the introduction of external knowledge. Finally, we present the datasets of VQA and different evaluation metrics and discuss possible directions for future work.