 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph of Attacks with Pruning: Optimizing Stealthy Jailbreak Prompt Generation for Enhanced LLM Content Moderation
Jan 28, 2025We present a modular pipeline that automates the generation of stealthy jailbreak prompts derived from high-level content policies, enhancing LLM content moderation. First, we address query inefficiency and jailbreak strength by developing Graph of Attacks with Pruning (GAP), a method that utilizes strategies from prior jailbreaks, resulting in 92% attack success rate on GPT-3.5 using only 54% of the queries of the prior algorithm. Second, we address the cold-start issue by automatically generating seed prompts from the high-level policy using LLMs. Finally, we demonstrate the utility of these generated jailbreak prompts of improving content moderation by fine-tuning PromptGuard, a model trained to detect jailbreaks, increasing its accuracy on the Toxic-Chat dataset from 5.1% to 93.89%.
Decision Transformers for RIS-Assisted Systems with Diffusion Model-Based Channel Acquisition
Jan 14, 2025



Reconfigurable intelligent surfaces (RISs) have been recognized as a revolutionary technology for future wireless networks. However, RIS-assisted communications have to continuously tune phase-shifts relying on accurate channel state information (CSI) that is generally difficult to obtain due to the large number of RIS channels. The joint design of CSI acquisition and subsection RIS phase-shifts remains a significant challenge in dynamic environments. In this paper, we propose a diffusion-enhanced decision Transformer (DEDT) framework consisting of a diffusion model (DM) designed for efficient CSI acquisition and a decision Transformer (DT) utilized for phase-shift optimizations. Specifically, we first propose a novel DM mechanism, i.e., conditional imputation based on denoising diffusion probabilistic model, for rapidly acquiring real-time full CSI by exploiting the spatial correlations inherent in wireless channels. Then, we optimize beamforming schemes based on the DT architecture, which pre-trains on historical environments to establish a robust policy model. Next, we incorporate a fine-tuning mechanism to ensure rapid beamforming adaptation to new environments, eliminating the retraining process that is imperative in conventional reinforcement learning (RL) methods. Simulation results demonstrate that DEDT can enhance efficiency and adaptability of RIS-aided communications with fluctuating channel conditions compared to state-of-the-art RL methods.
Unlocking adaptive digital pathology through dynamic feature learning
Dec 29, 2024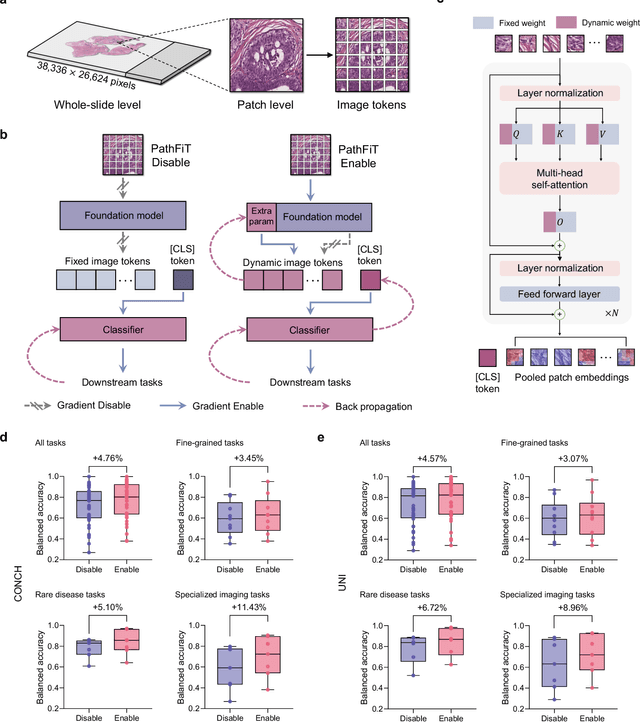
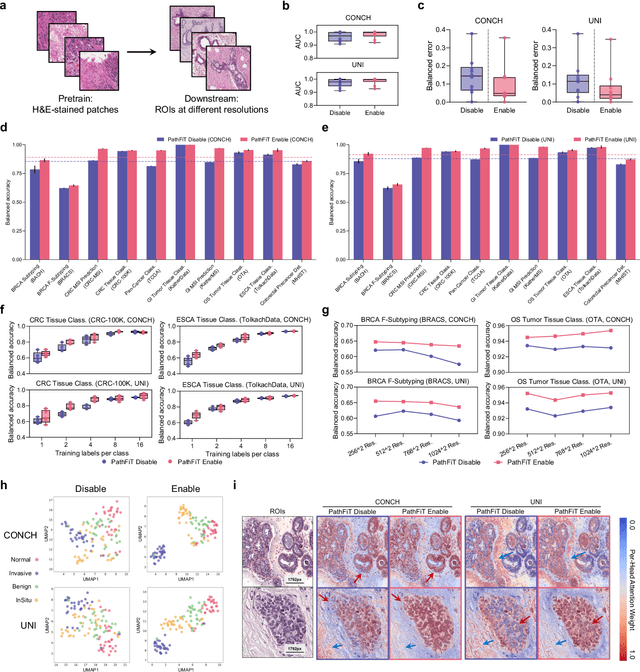

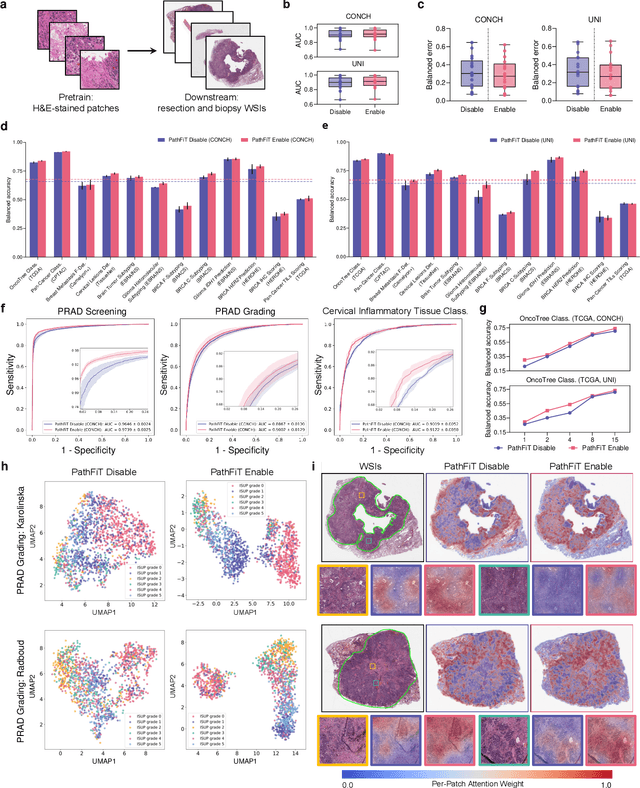
Foundation models have revolutionized the paradigm of digital pathology, as they leverage general-purpose features to emulate real-world pathological practices, enabling the quantitative analysis of critical histological patterns and the dissection of cancer-specific signals. However, these static general features constrain the flexibility and pathological relevance in the ever-evolving needs of clinical applications, hindering the broad use of the current models. Here we introduce PathFiT, a dynamic feature learning method that can be effortlessly plugged into various pathology foundation models to unlock their adaptability. Meanwhile, PathFiT performs seamless implementation across diverse pathology applications regardless of downstream specificity. To validate PathFiT, we construct a digital pathology benchmark with over 20 terabytes of Internet and real-world data comprising 28 H\&E-stained tasks and 7 specialized imaging tasks including Masson's Trichrome staining and immunofluorescence images. By applying PathFiT to the representative pathology foundation models, we demonstrate state-of-the-art performance on 34 out of 35 tasks, with significant improvements on 23 tasks and outperforming by 10.20% on specialized imaging tasks. The superior performance and versatility of PathFiT open up new avenues in computational pathology.
Radiology Report Generation via Multi-objective Preference Optimization
Dec 12, 2024



Automatic Radiology Report Generation (RRG) is an important topic for alleviating the substantial workload of radiologists. Existing RRG approaches rely on supervised regression based on different architectures or additional knowledge injection,while the generated report may not align optimally with radiologists' preferences. Especially, since the preferences of radiologists are inherently heterogeneous and multidimensional, e.g., some may prioritize report fluency, while others emphasize clinical accuracy. To address this problem,we propose a new RRG method via Multi-objective Preference Optimization (MPO) to align the pre-trained RRG model with multiple human preferences, which can be formulated by multi-dimensional reward functions and optimized by multi-objective reinforcement learning (RL). Specifically, we use a preference vector to represent the weight of preferences and use it as a condition for the RRG model. Then, a linearly weighed reward is obtained via a dot product between the preference vector and multi-dimensional reward.Next,the RRG model is optimized to align with the preference vector by optimizing such a reward via RL. In the training stage,we randomly sample diverse preference vectors from the preference space and align the model by optimizing the weighted multi-objective rewards, which leads to an optimal policy on the entire preference space. When inference,our model can generate reports aligned with specific preferences without further fine-tuning. Extensive experiments on two public datasets show the proposed method can generate reports that cater to different preferences in a single model and achieve state-of-the-art performance.
Performance Analysis of XL-MIMO with Rotary and Movable Antennas for High-speed Railway
Dec 05, 2024



The rotary and movable antennas (ROMA) technology is efficient in enhancing wireless network capacity by adjusting both the antenna spacing and three-dimensional (3D) rotation of antenna surfaces, based on the spatial distribution of users and channel statistics. Applying ROMA to high-speed rail (HSR) wireless communications can significantly improve system performance in terms of array gain and spatial multiplexing. However, the rapidly changing channel conditions in HSR scenarios present challenges for ROMA configuration. In this correspondence, we propose a analytical framework for configuring ROMA-based extremely large-scale multiple-input-multiple-output (XL-MIMO) system in HSR scenarios based on spatial correlation. First, we develop a localization model based on a mobility-aware near-field beam training algorithm to determine the real-time position of the train relay antennas. Next, we derive the expression for channel orthogonality and antenna spacing based on the spatial correlation matrix, and obtain the optimal antenna spacing when the transceiver panels are aligned in parallel. Moreover, we propose an optimization algorithm for the rotation angle of the transceiver panels, leveraging the differential evolution method, to determine the optimal angle. Finally, numerical results are provided to validate the computational results and optimization algorithm.
Hierarchical Prompt Decision Transformer: Improving Few-Shot Policy Generalization with Global and Adaptive
Dec 01, 2024



Decision transformers recast reinforcement learning as a conditional sequence generation problem, offering a simple but effective alternative to traditional value or policy-based methods. A recent key development in this area is the integration of prompting in decision transformers to facilitate few-shot policy generalization. However, current methods mainly use static prompt segments to guide rollouts, limiting their ability to provide context-specific guidance. Addressing this, we introduce a hierarchical prompting approach enabled by retrieval augmentation. Our method learns two layers of soft tokens as guiding prompts: (1) global tokens encapsulating task-level information about trajectories, and (2) adaptive tokens that deliver focused, timestep-specific instructions. The adaptive tokens are dynamically retrieved from a curated set of demonstration segments, ensuring context-aware guidance. Experiments across seven benchmark tasks in the MuJoCo and MetaWorld environments demonstrate the proposed approach consistently outperforms all baseline methods, suggesting that hierarchical prompting for decision transformers is an effective strategy to enable few-shot policy generalization.
Task Progressive Curriculum Learning for Robust Visual Question Answering
Nov 26, 2024



Visual Question Answering (VQA) systems are known for their poor performance in out-of-distribution datasets. An issue that was addressed in previous works through ensemble learning, answer re-ranking, or artificially growing the training set. In this work, we show for the first time that robust Visual Question Answering is attainable by simply enhancing the training strategy. Our proposed approach, Task Progressive Curriculum Learning (TPCL), breaks the main VQA problem into smaller, easier tasks based on the question type. Then, it progressively trains the model on a (carefully crafted) sequence of tasks. We further support the method by a novel distributional-based difficulty measurer. Our approach is conceptually simple, model-agnostic, and easy to implement. We demonstrate TPCL effectiveness through a comprehensive evaluation on standard datasets. Without either data augmentation or explicit debiasing mechanism, it achieves state-of-the-art on VQA-CP v2, VQA-CP v1 and VQA v2 datasets. Extensive experiments demonstrate that TPCL outperforms the most competitive robust VQA approaches by more than 5% and 7% on VQA-CP v2 and VQA-CP v1; respectively. TPCL also can boost VQA baseline backbone performance by up to 28.5%.
Goal-oriented Semantic Communications for Metaverse Construction via Generative AI and Optimal Transport
Nov 25, 2024



The emergence of the metaverse has boosted productivity and creativity, driving real-time updates and personalized content, which will substantially increase data traffic. However, current bit-oriented communication networks struggle to manage this high volume of dynamic information, restricting metaverse applications interactivity. To address this research gap, we propose a goal-oriented semantic communication (GSC) framework for metaverse. Building on an existing metaverse wireless construction task, our proposed GSC framework includes an hourglass network-based (HgNet) encoder to extract semantic information of objects in the metaverse; and a semantic decoder that uses this extracted information to reconstruct the metaverse content after wireless transmission, enabling efficient communication and real-time object behaviour updates to the scenery for metaverse construction task. To overcome the wireless channel noise at the receiver, we design an optimal transport (OT)-enabled semantic denoiser, which enhances the accuracy of metaverse scenery through wireless communication. Experimental results show that compared to the conventional metaverse construction, our proposed GSC framework significantly reduces wireless metaverse construction latency by 92.6\%, while improving metaverse object status accuracy and viewing experience by 45.6\% and 44.7\%, respectively.
Bayesian Calibration of Win Rate Estimation with LLM Evaluators
Nov 07, 2024



Recent advances in large language models (LLMs) show the potential of using LLMs as evaluators for assessing the quality of text generations from LLMs. However, applying LLM evaluators naively to compare or judge between different systems can lead to unreliable results due to the intrinsic win rate estimation bias of LLM evaluators. In order to mitigate this problem, we propose two calibration methods, Bayesian Win Rate Sampling (BWRS) and Bayesian Dawid-Skene, both of which leverage Bayesian inference to more accurately infer the true win rate of generative language models. We empirically validate our methods on six datasets covering story generation, summarization, and instruction following tasks. We show that both our methods are effective in improving the accuracy of win rate estimation using LLMs as evaluators, offering a promising direction for reliable automatic text quality evaluation.
Decoupled Data Augmentation for Improving Image Classification
Oct 29, 2024



Recent advancements in image mixing and generative data augmentation have shown promise in enhancing image classification. However, these techniques face the challenge of balancing semantic fidelity with diversity. Specifically, image mixing involves interpolating two images to create a new one, but this pixel-level interpolation can compromise fidelity. Generative augmentation uses text-to-image generative models to synthesize or modify images, often limiting diversity to avoid generating out-of-distribution data that potentially affects accuracy. We propose that this fidelity-diversity dilemma partially stems from the whole-image paradigm of existing methods. Since an image comprises the class-dependent part (CDP) and the class-independent part (CIP), where each part has fundamentally different impacts on the image's fidelity, treating different parts uniformly can therefore be misleading. To address this fidelity-diversity dilemma, we introduce Decoupled Data Augmentation (De-DA), which resolves the dilemma by separating images into CDPs and CIPs and handling them adaptively. To maintain fidelity, we use generative models to modify real CDPs under controlled conditions, preserving semantic consistency. To enhance diversity, we replace the image's CIP with inter-class variants, creating diverse CDP-CIP combinations. Additionally, we implement an online randomized combination strategy during training to generate numerous distinct CDP-CIP combinations cost-effectively. Comprehensive empirical evaluations validate the effectiveness of our method.