 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure-aware Knowledge-guided Heterogeneous Mamba for Zygomaticomaxillary Suture Assessment
Jun 15, 2026The Zygomaticomaxillary Suture is a key circummaxillary structure that connects the zygomatic bone and the maxilla, which serves as a primary site of resistance during maxillary advancement, and its maturation status directly influences the timing and efficacy of orthopedic interventions. However, accurate staging of ZMS maturation remains challenging due to subtle high-frequency transitions in suture lines and the global semantic ambiguity between adjacent stages. To address this, we present the first public ZMS dataset, comprising 3,790 ZMS images covering the entire age range from 4 to 24 years. Based on this dataset, we propose SKMamba, a Structure-aware and Knowledge-guided Mamba-based multi-modal framework for automated ZMS maturation assessment. SKMamba adopts a decoupled dual-path architecture that mimics the hierarchical diagnostic process used by experienced orthodontists. We first introduce an Implicit Edge Extractor (IEE), which leverages structural pre-training to reduce trabecular noise and accentuate sutural boundaries. Complementarily, a Cross-Modal Semantic Alignment (CSA) module is designed to incorporate anatomical descriptions from a large language model (LLM). This module helps align local morphological cues with global semantic descriptions while ensuring that objective morphological evidence remains the primary basis for decisions. Extensive experiments on our ZMS dataset demonstrate that SKMamba achieves state-of-the-art performance compared to existing methods. Code is available at https://github.com/galaxygxq1116/SKMamba.
Ling and Ring 2.6 Technical Report: Efficient and Instant Agentic Intelligence at Trillion-Parameter Scale
Jun 13, 2026Efficient and scalable agentic intelligence requires models that can deliver both low-latency responses and strong reasoning capabilities while remaining practical to train, serve, and deploy. In this report, we present Ling-2.6 and Ring-2.6, a family of models designed to address this challenge at scale. Ling-2.6 is optimized for instant response generation and high capability per output token, whereas Ring-2.6 is tailored for deeper reasoning and more advanced agentic workflows. Instead of training from scratch, we upgrade the Ling-2.0 base model through architectural migration pre-training and large-scale post-training. This upgrade is guided by a unified co-design of model architecture, optimization objectives, serving systems, and agent training environments, enabling improvements in both model capability and deployment efficiency. At the architectural level, we introduce a hybrid linear attention design that integrates Lightning Attention with MLA, improving the efficiency of long-context training and decoding. To further enhance token efficiency, we optimize capability per output token through Evolutionary Chain-of-Thought, Linguistic Unit Policy Optimization, bidirectional preference alignment, and shortest-correct-response distillation. For agentic capabilities, we propose KPop, a reinforcement learning framework designed to support stable training of Ring-2.6-1T on large-scale environment-grounded data. KPop improves training efficiency through asynchronous scheduling across coding, search, tool use, and workflow execution, enabling scalable learning from complex agent-environment interactions. Together, Ling-2.6 and Ring-2.6 provide a practical pathway toward efficient, scalable, and open agentic systems. We open-source all checkpoints in the 2.6 family to support further research and development in practical agentic intelligence.
Caries DETR: Tooth Structure-aware Prior and Lesion-aware Dynamic Loss Refinement for DETR Based Caries Detection
Apr 26, 2026As dental caries appear as subtle, low-contrast lesions in intraoral imaging, existing deep learning models face significant challenges in the early detection of caries. While recent Transformer-based detectors have shown promising results in natural images, they often fail to capture the domain-specific anatomical priors crucial for dental caries detection. In this paper, we propose Caries-DETR, a specialized Transformer framework for caries detection in intraoral images. A Tooth Structure-aware Query Initialization (TSQI) is designed, leveraging large-scale intraoral photograph pre-training and a structure perception branch (SPB) to integrate high-frequency structural priors, guiding the model to focus on anatomically significant lesion areas. Furthermore, we design a Lesion-aware Dynamic Loss Refinement (LDLR) to implement quality-driven hard mining through adaptive loss reweighting based on lesion size, anatomical relevance, and prediction quality, optimizing detection for subtle lesions. Extensive experiments on two public datasets (i.e., AlphaDent and DentalAI) demonstrate that Caries-DETR achieves a state-of-the-art performance compared to existing methods and exhibits good generalization and robustness. Code and data at https://github.com/XuefenLiu-SZU/Caries-DETR}{https://github.com/XuefenLiu-SZU/Caries-DETR.
Text-Conditioned Multi-Expert Regression Framework for Fully Automated Multi-Abutment Design
Apr 10, 2026Dental implant abutments serve as the geometric and biomechanical interface between the implant fixture and the prosthetic crown, yet their design relies heavily on manual effort and is time-consuming. Although deep neural networks have been proposed to assist dentists in designing abutments, most existing approaches remain largely manual or semi-automated, requiring substantial clinician intervention and lacking scalability in multi-abutment scenarios. To address these limitations, we propose TEMAD, a fully automated, text-conditioned multi-expert architecture for multi-abutment design. This framework integrates implant site localization and implant system, compatible abutment parameter regression into a unified pipeline. Specifically, we introduce an Implant Site Identification Network (ISIN) to automatically localize implant sites and provide this information to the subsequent multi-abutment regression network. We further design a Tooth-Conditioned Feature-wise Linear Modulation (TC-FiLM) module, which adaptively calibrates mesh representations using tooth embeddings to enable position-specific feature modulation. Additionally, a System-Prompted Mixture-of-Experts (SPMoE) mechanism leverages implant system prompts to guide expert selection, ensuring system-aware regression. Extensive experiments on a large-scale abutment design dataset show that TEMAD achieves state-of-the-art performance compared to existing methods, particularly in multi-abutment settings, validating its effectiveness for fully automated dental implant planning.
DinoDental: Benchmarking DINOv3 as a Unified Vision Encoder for Dental Image Analysis
Mar 30, 2026The scarcity and high cost of expert annotations in dental imaging present a significant challenge for the development of AI in dentistry. DINOv3, a state-of-the-art, self-supervised vision foundation model pre-trained on 1.7 billion images, offers a promising pathway to mitigate this issue. However, its reliability when transferred to the dental domain, with its unique imaging characteristics and clinical subtleties, remains unclear. To address this, we introduce DinoDental, a unified benchmark designed to systematically evaluate whether DINOv3 can serve as a reliable, off-the-shelf encoder for comprehensive dental image analysis without requiring domain-specific pre-training. Constructed from multiple public datasets, DinoDental covers a wide range of tasks, including classification, detection, and instance segmentation on both panoramic radiographs and intraoral photographs. We further analyze the model's transfer performance by scaling its size and input resolution, and by comparing different adaptation strategies, including frozen features, full fine-tuning, and the parameter-efficient Low-Rank Adaptation (LoRA) method. Our experiments show that DINOv3 can serve as a strong unified encoder for dental image analysis across both panoramic radiographs and intraoral photographs, remaining competitive across tasks while showing particularly clear advantages for intraoral image understanding and boundary-sensitive dense prediction. Collectively, DinoDental provides a systematic framework for comprehensively evaluating DINOv3 in dental analysis, establishing a foundational benchmark to guide efficient and effective model selection and adaptation for the dental AI community.
RegFreeNet: A Registration-Free Network for CBCT-based 3D Dental Implant Planning
Jan 21, 2026As the commercial surgical guide design software usually does not support the export of implant position for pre-implantation data, existing methods have to scan the post-implantation data and map the implant to pre-implantation space to get the label of implant position for training. Such a process is time-consuming and heavily relies on the accuracy of registration algorithm. Moreover, not all hospitals have paired CBCT data, limitting the construction of multi-center dataset. Inspired by the way dentists determine the implant position based on the neighboring tooth texture, we found that even if the implant area is masked, it will not affect the determination of the implant position. Therefore, we propose to mask the implants in the post-implantation data so that any CBCT containing the implants can be used as training data. This paradigm enables us to discard the registration process and makes it possible to construct a large-scale multi-center implant dataset. On this basis, we proposes ImplantFairy, a comprehensive, publicly accessible dental implant dataset with voxel-level 3D annotations of 1622 CBCT data. Furthermore, according to the area variation characteristics of the tooth's spatial structure and the slope information of the implant, we designed a slope-aware implant position prediction network. Specifically, a neighboring distance perception (NDP) module is designed to adaptively extract tooth area variation features, and an implant slope prediction branch assists the network in learning more robust features through additional implant supervision information. Extensive experiments conducted on ImplantFairy and two public dataset demonstrate that the proposed RegFreeNet achieves the state-of-the-art performance.
SSA3D: Text-Conditioned Assisted Self-Supervised Framework for Automatic Dental Abutment Design
Dec 12, 2025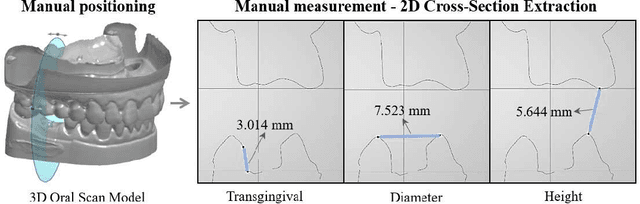
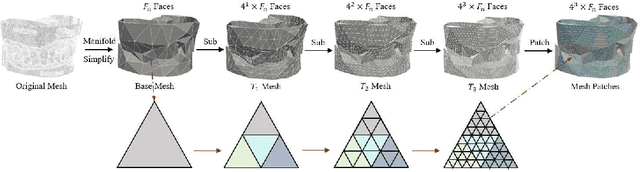
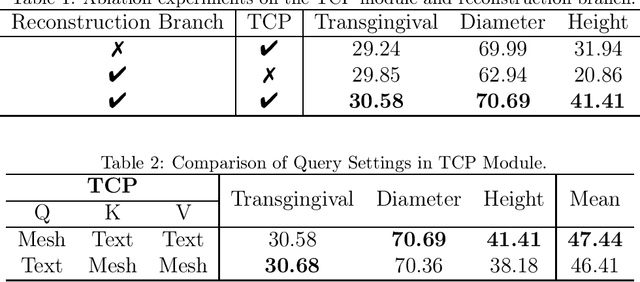
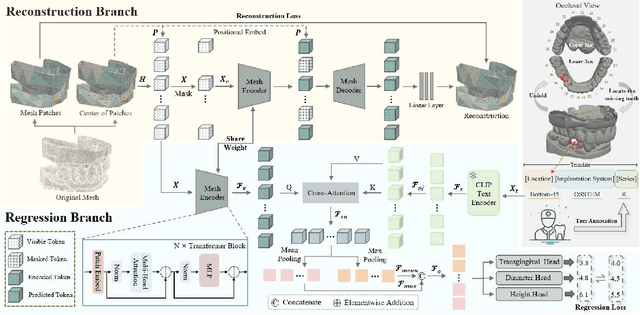
Abutment design is a critical step in dental implant restoration. However, manual design involves tedious measurement and fitting, and research on automating this process with AI is limited, due to the unavailability of large annotated datasets. Although self-supervised learning (SSL) can alleviate data scarcity, its need for pre-training and fine-tuning results in high computational costs and long training times. In this paper, we propose a Self-supervised assisted automatic abutment design framework (SS$A^3$D), which employs a dual-branch architecture with a reconstruction branch and a regression branch. The reconstruction branch learns to restore masked intraoral scan data and transfers the learned structural information to the regression branch. The regression branch then predicts the abutment parameters under supervised learning, which eliminates the separate pre-training and fine-tuning process. We also design a Text-Conditioned Prompt (TCP) module to incorporate clinical information (such as implant location, system, and series) into SS$A^3$D. This guides the network to focus on relevant regions and constrains the parameter predictions. Extensive experiments on a collected dataset show that SS$A^3$D saves half of the training time and achieves higher accuracy than traditional SSL methods. It also achieves state-of-the-art performance compared to other methods, significantly improving the accuracy and efficiency of automated abutment design.
GESH-Net: Graph-Enhanced Spherical Harmonic Convolutional Networks for Cortical Surface Registration
Oct 18, 2024Currently, cortical surface registration techniques based on classical methods have been well developed. However, a key issue with classical methods is that for each pair of images to be registered, it is necessary to search for the optimal transformation in the deformation space according to a specific optimization algorithm until the similarity measure function converges, which cannot meet the requirements of real-time and high-precision in medical image registration. Researching cortical surface registration based on deep learning models has become a new direction. But so far, there are still only a few studies on cortical surface image registration based on deep learning. Moreover, although deep learning methods theoretically have stronger representation capabilities, surpassing the most advanced classical methods in registration accuracy and distortion control remains a challenge. Therefore, to address this challenge, this paper constructs a deep learning model to study the technology of cortical surface image registration. The specific work is as follows: (1) An unsupervised cortical surface registration network based on a multi-scale cascaded structure is designed, and a convolution method based on spherical harmonic transformation is introduced to register cortical surface data. This solves the problem of scale-inflexibility of spherical feature transformation and optimizes the multi-scale registration process. (2)By integrating the attention mechanism, a graph-enhenced module is introduced into the registration network, using the graph attention module to help the network learn global features of cortical surface data, enhancing the learning ability of the network. The results show that the graph attention module effectively enhances the network's ability to extract global features, and its registration results have significant advantages over other methods.
Flexible 3D Lane Detection by Hierarchical Shape MatchingFlexible 3D Lane Detection by Hierarchical Shape Matching
Aug 13, 2024



As one of the basic while vital technologies for HD map construction, 3D lane detection is still an open problem due to varying visual conditions, complex typologies, and strict demands for precision. In this paper, an end-to-end flexible and hierarchical lane detector is proposed to precisely predict 3D lane lines from point clouds. Specifically, we design a hierarchical network predicting flexible representations of lane shapes at different levels, simultaneously collecting global instance semantics and avoiding local errors. In the global scope, we propose to regress parametric curves w.r.t adaptive axes that help to make more robust predictions towards complex scenes, while in the local vision the structure of lane segment is detected in each of the dynamic anchor cells sampled along the global predicted curves. Moreover, corresponding global and local shape matching losses and anchor cell generation strategies are designed. Experiments on two datasets show that we overwhelm current top methods under high precision standards, and full ablation studies also verify each part of our method. Our codes will be released at https://github.com/Doo-do/FHLD.
A Survey on Multimodal Large Language Models for Autonomous Driving
Nov 21, 2023



With the emergence of Large Language Models (LLMs) and Vision Foundation Models (VFMs), multimodal AI systems benefiting from large models have the potential to equally perceive the real world, make decisions, and control tools as humans. In recent months, LLMs have shown widespread attention in autonomous driving and map systems. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors to apply in LLM driving systems. In this paper, we present a systematic investigation in this field. We first introduce the background of Multimodal Large Language Models (MLLMs), the multimodal models development using LLMs, and the history of autonomous driving. Then, we overview existing MLLM tools for driving, transportation, and map systems together with existing datasets and benchmarks. Moreover, we summarized the works in The 1st WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD), which is the first workshop of its kind regarding LLMs in autonomous driving. To further promote the development of this field, we also discuss several important problems regarding using MLLMs in autonomous driving systems that need to be solved by both academia and industry.