 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInconsistent Tokenizations Cause Language Models to be Perplexed by Japanese Grammar
May 26, 2025Typical methods for evaluating the performance of language models evaluate their ability to answer questions accurately. These evaluation metrics are acceptable for determining the extent to which language models can understand and reason about text in a general sense, but fail to capture nuanced capabilities, such as the ability of language models to recognize and obey rare grammar points, particularly in languages other than English. We measure the perplexity of language models when confronted with the "first person psych predicate restriction" grammar point in Japanese. Weblab is the only tested open source model in the 7-10B parameter range which consistently assigns higher perplexity to ungrammatical psych predicate sentences than grammatical ones. We give evidence that Weblab's uniformly bad tokenization is a possible root cause for its good performance, and show that Llama 3's perplexity on grammatical psych predicate sentences can be reduced by orders of magnitude (28x difference) by restricting test sentences to those with uniformly well-behaved tokenizations. We show in further experiments on machine translation tasks that language models will use alternative grammar patterns in order to produce grammatical sentences when tokenization issues prevent the most natural sentence from being output.
Beyond Induction Heads: In-Context Meta Learning Induces Multi-Phase Circuit Emergence
May 22, 2025Transformer-based language models exhibit In-Context Learning (ICL), where predictions are made adaptively based on context. While prior work links induction heads to ICL through a sudden jump in accuracy, this can only account for ICL when the answer is included within the context. However, an important property of practical ICL in large language models is the ability to meta-learn how to solve tasks from context, rather than just copying answers from context; how such an ability is obtained during training is largely unexplored. In this paper, we experimentally clarify how such meta-learning ability is acquired by analyzing the dynamics of the model's circuit during training. Specifically, we extend the copy task from previous research into an In-Context Meta Learning setting, where models must infer a task from examples to answer queries. Interestingly, in this setting, we find that there are multiple phases in the process of acquiring such abilities, and that a unique circuit emerges in each phase, contrasting with the single-phases change in induction heads. The emergence of such circuits can be related to several phenomena known in large language models, and our analysis lead to a deeper understanding of the source of the transformer's ICL ability.
A Comprehensive Survey on Physical Risk Control in the Era of Foundation Model-enabled Robotics
May 19, 2025Recent Foundation Model-enabled robotics (FMRs) display greatly improved general-purpose skills, enabling more adaptable automation than conventional robotics. Their ability to handle diverse tasks thus creates new opportunities to replace human labor. However, unlike general foundation models, FMRs interact with the physical world, where their actions directly affect the safety of humans and surrounding objects, requiring careful deployment and control. Based on this proposition, our survey comprehensively summarizes robot control approaches to mitigate physical risks by covering all the lifespan of FMRs ranging from pre-deployment to post-accident stage. Specifically, we broadly divide the timeline into the following three phases: (1) pre-deployment phase, (2) pre-incident phase, and (3) post-incident phase. Throughout this survey, we find that there is much room to study (i) pre-incident risk mitigation strategies, (ii) research that assumes physical interaction with humans, and (iii) essential issues of foundation models themselves. We hope that this survey will be a milestone in providing a high-resolution analysis of the physical risks of FMRs and their control, contributing to the realization of a good human-robot relationship.
ColorizeDiffusion v2: Enhancing Reference-based Sketch Colorization Through Separating Utilities
Apr 09, 2025



Reference-based sketch colorization methods have garnered significant attention due to their potential applications in the animation production industry. However, most existing methods are trained with image triplets of sketch, reference, and ground truth that are semantically and spatially well-aligned, while real-world references and sketches often exhibit substantial misalignment. This mismatch in data distribution between training and inference leads to overfitting, consequently resulting in spatial artifacts and significant degradation in overall colorization quality, limiting potential applications of current methods for general purposes. To address this limitation, we conduct an in-depth analysis of the \textbf{carrier}, defined as the latent representation facilitating information transfer from reference to sketch. Based on this analysis, we propose a novel workflow that dynamically adapts the carrier to optimize distinct aspects of colorization. Specifically, for spatially misaligned artifacts, we introduce a split cross-attention mechanism with spatial masks, enabling region-specific reference injection within the diffusion process. To mitigate semantic neglect of sketches, we employ dedicated background and style encoders to transfer detailed reference information in the latent feature space, achieving enhanced spatial control and richer detail synthesis. Furthermore, we propose character-mask merging and background bleaching as preprocessing steps to improve foreground-background integration and background generation. Extensive qualitative and quantitative evaluations, including a user study, demonstrate the superior performance of our proposed method compared to existing approaches. An ablation study further validates the efficacy of each proposed component.
MKG-Rank: Enhancing Large Language Models with Knowledge Graph for Multilingual Medical Question Answering
Mar 21, 2025Large Language Models (LLMs) have shown remarkable progress in medical question answering (QA), yet their effectiveness remains predominantly limited to English due to imbalanced multilingual training data and scarce medical resources for low-resource languages. To address this critical language gap in medical QA, we propose Multilingual Knowledge Graph-based Retrieval Ranking (MKG-Rank), a knowledge graph-enhanced framework that enables English-centric LLMs to perform multilingual medical QA. Through a word-level translation mechanism, our framework efficiently integrates comprehensive English-centric medical knowledge graphs into LLM reasoning at a low cost, mitigating cross-lingual semantic distortion and achieving precise medical QA across language barriers. To enhance efficiency, we introduce caching and multi-angle ranking strategies to optimize the retrieval process, significantly reducing response times and prioritizing relevant medical knowledge. Extensive evaluations on multilingual medical QA benchmarks across Chinese, Japanese, Korean, and Swahili demonstrate that MKG-Rank consistently outperforms zero-shot LLMs, achieving maximum 35.03% increase in accuracy, while maintaining an average retrieval time of only 0.0009 seconds.
MMLU-ProX: A Multilingual Benchmark for Advanced Large Language Model Evaluation
Mar 13, 2025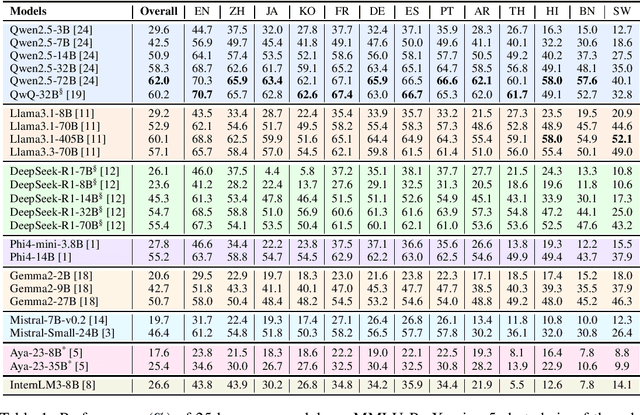
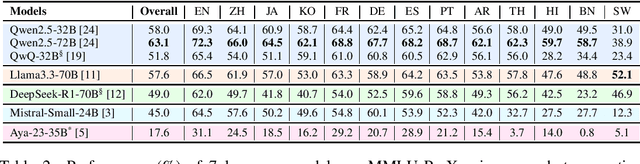
Traditional benchmarks struggle to evaluate increasingly sophisticated language models in multilingual and culturally diverse contexts. To address this gap, we introduce MMLU-ProX, a comprehensive multilingual benchmark covering 13 typologically diverse languages with approximately 11,829 questions per language. Building on the challenging reasoning-focused design of MMLU-Pro, our framework employs a semi-automatic translation process: translations generated by state-of-the-art large language models (LLMs) are rigorously evaluated by expert annotators to ensure conceptual accuracy, terminological consistency, and cultural relevance. We comprehensively evaluate 25 state-of-the-art LLMs using 5-shot chain-of-thought (CoT) and zero-shot prompting strategies, analyzing their performance across linguistic and cultural boundaries. Our experiments reveal consistent performance degradation from high-resource languages to lower-resource ones, with the best models achieving over 70% accuracy on English but dropping to around 40% for languages like Swahili, highlighting persistent gaps in multilingual capabilities despite recent advances. MMLU-ProX is an ongoing project; we are expanding our benchmark by incorporating additional languages and evaluating more language models to provide a more comprehensive assessment of multilingual capabilities.
Image Referenced Sketch Colorization Based on Animation Creation Workflow
Feb 27, 2025



Sketch colorization plays an important role in animation and digital illustration production tasks. However, existing methods still meet problems in that text-guided methods fail to provide accurate color and style reference, hint-guided methods still involve manual operation, and image-referenced methods are prone to cause artifacts. To address these limitations, we propose a diffusion-based framework inspired by real-world animation production workflows. Our approach leverages the sketch as the spatial guidance and an RGB image as the color reference, and separately extracts foreground and background from the reference image with spatial masks. Particularly, we introduce a split cross-attention mechanism with LoRA (Low-Rank Adaptation) modules. They are trained separately with foreground and background regions to control the corresponding embeddings for keys and values in cross-attention. This design allows the diffusion model to integrate information from foreground and background independently, preventing interference and eliminating the spatial artifacts. During inference, we design switchable inference modes for diverse use scenarios by changing modules activated in the framework. Extensive qualitative and quantitative experiments, along with user studies, demonstrate our advantages over existing methods in generating high-qualigy artifact-free results with geometric mismatched references. Ablation studies further confirm the effectiveness of each component. Codes are available at https://github.com/ tellurion-kanata/colorizeDiffusion.
Beyond In-Distribution Success: Scaling Curves of CoT Granularity for Language Model Generalization
Feb 25, 2025



Generalization to novel compound tasks under distribution shift is important for deploying transformer-based language models (LMs). This work investigates Chain-of-Thought (CoT) reasoning as a means to enhance OOD generalization. Through controlled experiments across several compound tasks, we reveal three key insights: (1) While QA-trained models achieve near-perfect in-distribution accuracy, their OOD performance degrades catastrophically, even with 10000k+ training examples; (2) the granularity of CoT data strongly correlates with generalization performance; finer-grained CoT data leads to better generalization; (3) CoT exhibits remarkable sample efficiency, matching QA performance with much less (even 80%) data. Theoretically, we demonstrate that compound tasks inherently permit shortcuts in Q-A data that misalign with true reasoning principles, while CoT forces internalization of valid dependency structures, and thus can achieve better generalization. Further, we show that transformer positional embeddings can amplify generalization by emphasizing subtask condition recurrence in long CoT sequences. Our combined theoretical and empirical analysis provides compelling evidence for CoT reasoning as a crucial training paradigm for enabling LM generalization under real-world distributional shifts for compound tasks.
Large Language Models as Theory of Mind Aware Generative Agents with Counterfactual Reflection
Jan 26, 2025



Recent studies have increasingly demonstrated that large language models (LLMs) possess significant theory of mind (ToM) capabilities, showing the potential for simulating the tracking of mental states in generative agents. In this study, we propose a novel paradigm called ToM-agent, designed to empower LLMs-based generative agents to simulate ToM in open-domain conversational interactions. ToM-agent disentangles the confidence from mental states, facilitating the emulation of an agent's perception of its counterpart's mental states, such as beliefs, desires, and intentions (BDIs). Using past conversation history and verbal reflections, ToM-Agent can dynamically adjust counterparts' inferred BDIs, along with related confidence levels. We further put forth a counterfactual intervention method that reflects on the gap between the predicted responses of counterparts and their real utterances, thereby enhancing the efficiency of reflection. Leveraging empathetic and persuasion dialogue datasets, we assess the advantages of implementing the ToM-agent with downstream tasks, as well as its performance in both the first-order and the \textit{second-order} ToM. Our findings indicate that the ToM-agent can grasp the underlying reasons for their counterpart's behaviors beyond mere semantic-emotional supporting or decision-making based on common sense, providing new insights for studying large-scale LLMs-based simulation of human social behaviors.
Rethinking Evaluation of Sparse Autoencoders through the Representation of Polysemous Words
Jan 09, 2025



Sparse autoencoders (SAEs) have gained a lot of attention as a promising tool to improve the interpretability of large language models (LLMs) by mapping the complex superposition of polysemantic neurons into monosemantic features and composing a sparse dictionary of words. However, traditional performance metrics like Mean Squared Error and L0 sparsity ignore the evaluation of the semantic representational power of SAEs -- whether they can acquire interpretable monosemantic features while preserving the semantic relationship of words. For instance, it is not obvious whether a learned sparse feature could distinguish different meanings in one word. In this paper, we propose a suite of evaluations for SAEs to analyze the quality of monosemantic features by focusing on polysemous words. Our findings reveal that SAEs developed to improve the MSE-L0 Pareto frontier may confuse interpretability, which does not necessarily enhance the extraction of monosemantic features. The analysis of SAEs with polysemous words can also figure out the internal mechanism of LLMs; deeper layers and the Attention module contribute to distinguishing polysemy in a word. Our semantics focused evaluation offers new insights into the polysemy and the existing SAE objective and contributes to the development of more practical SAEs.