 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocalV: Exploiting Information Locality for IP-level Verilog Generation
Jan 31, 2026The generation of Register-Transfer Level (RTL) code is a crucial yet labor-intensive step in digital hardware design, traditionally requiring engineers to manually translate complex specifications into thousands of lines of synthesizable Hardware Description Language (HDL) code. While Large Language Models (LLMs) have shown promise in automating this process, existing approaches-including fine-tuned domain-specific models and advanced agent-based systems-struggle to scale to industrial IP-level design tasks. We identify three key challenges: (1) handling long, highly detailed documents, where critical interface constraints become buried in unrelated submodule descriptions; (2) generating long RTL code, where both syntactic and semantic correctness degrade sharply with increasing output length; and (3) navigating the complex debugging cycles required for functional verification through simulation and waveform analysis. To overcome these challenges, we propose LocalV, a multi-agent framework that leverages information locality in modular hardware design. LocalV decomposes the long-document to long-code generation problem into a set of short-document, short-code tasks, enabling scalable generation and debugging. Specifically, LocalV integrates hierarchical document partitioning, task planning, localized code generation, interface-consistent merging, and AST-guided locality-aware debugging. Experiments on RealBench, an IP-level Verilog generation benchmark, demonstrate that LocalV substantially outperforms state-of-the-art (SOTA) LLMs and agents, achieving a pass rate of 45.0% compared to 21.6%.
Run, Ruminate, and Regulate: A Dual-process Thinking System for Vision-and-Language Navigation
Nov 18, 2025Vision-and-Language Navigation (VLN) requires an agent to dynamically explore complex 3D environments following human instructions. Recent research underscores the potential of harnessing large language models (LLMs) for VLN, given their commonsense knowledge and general reasoning capabilities. Despite their strengths, a substantial gap in task completion performance persists between LLM-based approaches and domain experts, as LLMs inherently struggle to comprehend real-world spatial correlations precisely. Additionally, introducing LLMs is accompanied with substantial computational cost and inference latency. To address these issues, we propose a novel dual-process thinking framework dubbed R3, integrating LLMs' generalization capabilities with VLN-specific expertise in a zero-shot manner. The framework comprises three core modules: Runner, Ruminator, and Regulator. The Runner is a lightweight transformer-based expert model that ensures efficient and accurate navigation under regular circumstances. The Ruminator employs a powerful multimodal LLM as the backbone and adopts chain-of-thought (CoT) prompting to elicit structured reasoning. The Regulator monitors the navigation progress and controls the appropriate thinking mode according to three criteria, integrating Runner and Ruminator harmoniously. Experimental results illustrate that R3 significantly outperforms other state-of-the-art methods, exceeding 3.28% and 3.30% in SPL and RGSPL respectively on the REVERIE benchmark. This pronounced enhancement highlights the effectiveness of our method in handling challenging VLN tasks.
QiMeng-SALV: Signal-Aware Learning for Verilog Code Generation
Oct 22, 2025The remarkable progress of Large Language Models (LLMs) presents promising opportunities for Verilog code generation which is significantly important for automated circuit design. The lacking of meaningful functional rewards hinders the preference optimization based on Reinforcement Learning (RL) for producing functionally correct Verilog code. In this paper, we propose Signal-Aware Learning for Verilog code generation (QiMeng-SALV) by leveraging code segments of functionally correct output signal to optimize RL training. Considering Verilog code specifies the structural interconnection of hardware gates and wires so that different output signals are independent, the key insight of QiMeng-SALV is to extract verified signal-aware implementations in partially incorrect modules, so as to enhance the extraction of meaningful functional rewards. Roughly, we verify the functional correctness of signals in generated module by comparing with that of reference module in the training data. Then abstract syntax tree (AST) is employed to identify signal-aware code segments which can provide meaningful functional rewards from erroneous modules. Finally, we introduce signal-aware DPO which is optimized on the correct signal-level code segments, thereby preventing noise and interference from incorrect signals. The proposed QiMeng-SALV underscores the paradigm shift from conventional module-level to fine-grained signal-level optimization in Verilog code generation, addressing the issue of insufficient functional rewards. Experiments demonstrate that our method achieves state-of-the-art performance on VerilogEval and RTLLM, with a 7B parameter model matching the performance of the DeepSeek v3 671B model and significantly outperforming the leading open-source model CodeV trained on the same dataset. Our code is available at https://github.com/zy1xxx/SALV.
QiMeng-Attention: SOTA Attention Operator is generated by SOTA Attention Algorithm
Jun 14, 2025The attention operator remains a critical performance bottleneck in large language models (LLMs), particularly for long-context scenarios. While FlashAttention is the most widely used and effective GPU-aware acceleration algorithm, it must require time-consuming and hardware-specific manual implementation, limiting adaptability across GPU architectures. Existing LLMs have shown a lot of promise in code generation tasks, but struggle to generate high-performance attention code. The key challenge is it cannot comprehend the complex data flow and computation process of the attention operator and utilize low-level primitive to exploit GPU performance. To address the above challenge, we propose an LLM-friendly Thinking Language (LLM-TL) to help LLMs decouple the generation of high-level optimization logic and low-level implementation on GPU, and enhance LLMs' understanding of attention operator. Along with a 2-stage reasoning workflow, TL-Code generation and translation, the LLMs can automatically generate FlashAttention implementation on diverse GPUs, establishing a self-optimizing paradigm for generating high-performance attention operators in attention-centric algorithms. Verified on A100, RTX8000, and T4 GPUs, the performance of our methods significantly outshines that of vanilla LLMs, achieving a speed-up of up to 35.16x. Besides, our method not only surpasses human-optimized libraries (cuDNN and official library) in most scenarios but also extends support to unsupported hardware and data types, reducing development time from months to minutes compared with human experts.
Mutual-Supervised Learning for Sequential-to-Parallel Code Translation
Jun 11, 2025



The rise of GPU-based high-performance computing (HPC) has driven the widespread adoption of parallel programming models such as CUDA. Yet, the inherent complexity of parallel programming creates a demand for the automated sequential-to-parallel approaches. However, data scarcity poses a significant challenge for machine learning-based sequential-to-parallel code translation. Although recent back-translation methods show promise, they still fail to ensure functional equivalence in the translated code. In this paper, we propose a novel Mutual-Supervised Learning (MSL) framework for sequential-to-parallel code translation to address the functional equivalence issue. MSL consists of two models, a Translator and a Tester. Through an iterative loop consisting of Co-verify and Co-evolve steps, the Translator and the Tester mutually generate data for each other and improve collectively. The Tester generates unit tests to verify and filter functionally equivalent translated code, thereby evolving the Translator, while the Translator generates translated code as augmented input to evolve the Tester. Experimental results demonstrate that MuSL significantly enhances the performance of the base model: when applied to Qwen2.5-Coder, it not only improves Pass@1 by up to 28.91% and boosts Tester performance by 68.90%, but also outperforms the previous state-of-the-art method CodeRosetta by 1.56 and 6.92 in BLEU and CodeBLEU scores, while achieving performance comparable to DeepSeek-R1 and GPT-4.1. Our code is available at https://github.com/kcxain/musl.
QiMeng: Fully Automated Hardware and Software Design for Processor Chip
Jun 05, 2025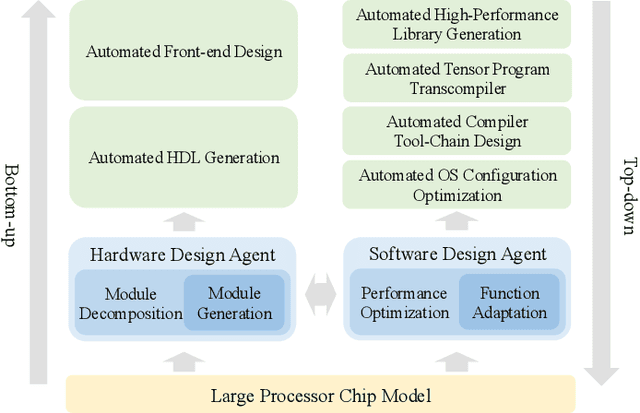
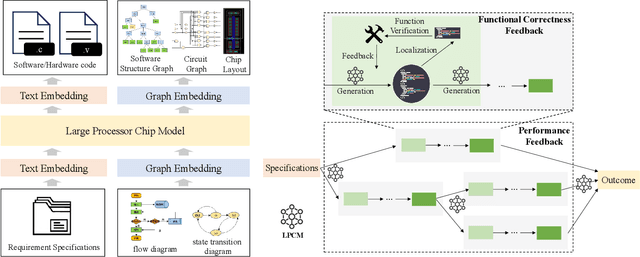
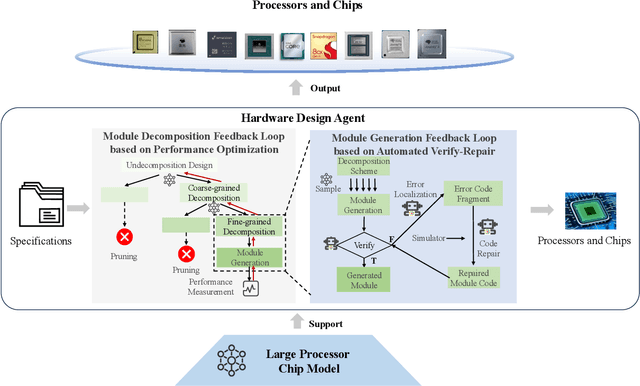
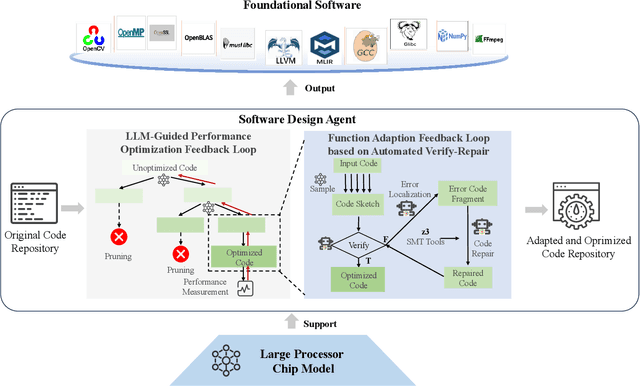
Processor chip design technology serves as a key frontier driving breakthroughs in computer science and related fields. With the rapid advancement of information technology, conventional design paradigms face three major challenges: the physical constraints of fabrication technologies, the escalating demands for design resources, and the increasing diversity of ecosystems. Automated processor chip design has emerged as a transformative solution to address these challenges. While recent breakthroughs in Artificial Intelligence (AI), particularly Large Language Models (LLMs) techniques, have opened new possibilities for fully automated processor chip design, substantial challenges remain in establishing domain-specific LLMs for processor chip design. In this paper, we propose QiMeng, a novel system for fully automated hardware and software design of processor chips. QiMeng comprises three hierarchical layers. In the bottom-layer, we construct a domain-specific Large Processor Chip Model (LPCM) that introduces novel designs in architecture, training, and inference, to address key challenges such as knowledge representation gap, data scarcity, correctness assurance, and enormous solution space. In the middle-layer, leveraging the LPCM's knowledge representation and inference capabilities, we develop the Hardware Design Agent and the Software Design Agent to automate the design of hardware and software for processor chips. Currently, several components of QiMeng have been completed and successfully applied in various top-layer applications, demonstrating significant advantages and providing a feasible solution for efficient, fully automated hardware/software design of processor chips. Future research will focus on integrating all components and performing iterative top-down and bottom-up design processes to establish a comprehensive QiMeng system.
CodeV-R1: Reasoning-Enhanced Verilog Generation
May 30, 2025Large language models (LLMs) trained via reinforcement learning with verifiable reward (RLVR) have achieved breakthroughs on tasks with explicit, automatable verification, such as software programming and mathematical problems. Extending RLVR to electronic design automation (EDA), especially automatically generating hardware description languages (HDLs) like Verilog from natural-language (NL) specifications, however, poses three key challenges: the lack of automated and accurate verification environments, the scarcity of high-quality NL-code pairs, and the prohibitive computation cost of RLVR. To this end, we introduce CodeV-R1, an RLVR framework for training Verilog generation LLMs. First, we develop a rule-based testbench generator that performs robust equivalence checking against golden references. Second, we propose a round-trip data synthesis method that pairs open-source Verilog snippets with LLM-generated NL descriptions, verifies code-NL-code consistency via the generated testbench, and filters out inequivalent examples to yield a high-quality dataset. Third, we employ a two-stage "distill-then-RL" training pipeline: distillation for the cold start of reasoning abilities, followed by adaptive DAPO, our novel RLVR algorithm that can reduce training cost by adaptively adjusting sampling rate. The resulting model, CodeV-R1-7B, achieves 68.6% and 72.9% pass@1 on VerilogEval v2 and RTLLM v1.1, respectively, surpassing prior state-of-the-art by 12~20%, while matching or even exceeding the performance of 671B DeepSeek-R1. We will release our model, training pipeline, and dataset to facilitate research in EDA and LLM communities.
LEGO-Compiler: Enhancing Neural Compilation Through Translation Composability
May 26, 2025Large language models (LLMs) have the potential to revolutionize how we design and implement compilers and code translation tools. However, existing LLMs struggle to handle long and complex programs. We introduce LEGO-Compiler, a novel neural compilation system that leverages LLMs to translate high-level languages into assembly code. Our approach centers on three key innovations: LEGO translation, which decomposes the input program into manageable blocks; breaking down the complex compilation process into smaller, simpler verifiable steps by organizing it as a verifiable LLM workflow by external tests; and a feedback mechanism for self-correction. Supported by formal proofs of translation composability, LEGO-Compiler demonstrates high accuracy on multiple datasets, including over 99% on ExeBench and 97.9% on industrial-grade AnsiBench. Additionally, LEGO-Compiler has also acheived near one order-of-magnitude improvement on compilable code size scalability. This work opens new avenues for applying LLMs to system-level tasks, complementing traditional compiler technologies.
QiMeng-TensorOp: Automatically Generating High-Performance Tensor Operators with Hardware Primitives
May 08, 2025Computation-intensive tensor operators constitute over 90\% of the computations in Large Language Models (LLMs) and Deep Neural Networks.Automatically and efficiently generating high-performance tensor operators with hardware primitives is crucial for diverse and ever-evolving hardware architectures like RISC-V, ARM, and GPUs, as manually optimized implementation takes at least months and lacks portability.LLMs excel at generating high-level language codes, but they struggle to fully comprehend hardware characteristics and produce high-performance tensor operators. We introduce a tensor-operator auto-generation framework with a one-line user prompt (QiMeng-TensorOp), which enables LLMs to automatically exploit hardware characteristics to generate tensor operators with hardware primitives, and tune parameters for optimal performance across diverse hardware. Experimental results on various hardware platforms, SOTA LLMs, and typical tensor operators demonstrate that QiMeng-TensorOp effectively unleashes the computing capability of various hardware platforms, and automatically generates tensor operators of superior performance. Compared with vanilla LLMs, QiMeng-TensorOp achieves up to $1291 \times$ performance improvement. Even compared with human experts, QiMeng-TensorOp could reach $251 \%$ of OpenBLAS on RISC-V CPUs, and $124 \%$ of cuBLAS on NVIDIA GPUs. Additionally, QiMeng-TensorOp also significantly reduces development costs by $200 \times$ compared with human experts.
QiMeng-Xpiler: Transcompiling Tensor Programs for Deep Learning Systems with a Neural-Symbolic Approach
May 04, 2025Heterogeneous deep learning systems (DLS) such as GPUs and ASICs have been widely deployed in industrial data centers, which requires to develop multiple low-level tensor programs for different platforms. An attractive solution to relieve the programming burden is to transcompile the legacy code of one platform to others. However, current transcompilation techniques struggle with either tremendous manual efforts or functional incorrectness, rendering "Write Once, Run Anywhere" of tensor programs an open question. We propose a novel transcompiler, i.e., QiMeng-Xpiler, for automatically translating tensor programs across DLS via both large language models (LLMs) and symbolic program synthesis, i.e., neural-symbolic synthesis. The key insight is leveraging the powerful code generation ability of LLM to make costly search-based symbolic synthesis computationally tractable. Concretely, we propose multiple LLM-assisted compilation passes via pre-defined meta-prompts for program transformation. During each program transformation, efficient symbolic program synthesis is employed to repair incorrect code snippets with a limited scale. To attain high performance, we propose a hierarchical auto-tuning approach to systematically explore both the parameters and sequences of transformation passes. Experiments on 4 DLS with distinct programming interfaces, i.e., Intel DL Boost with VNNI, NVIDIA GPU with CUDA, AMD MI with HIP, and Cambricon MLU with BANG, demonstrate that QiMeng-Xpiler correctly translates different tensor programs at the accuracy of 95% on average, and the performance of translated programs achieves up to 2.0x over vendor-provided manually-optimized libraries. As a result, the programming productivity of DLS is improved by up to 96.0x via transcompiling legacy tensor programs.