 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning When to Optimize: Verified Optimization Skills from Expert GPU-Kernel Lineages
May 27, 2026LLM-based agents are increasingly used to generate GPU kernels, but they often know what optimizations to try without knowing when those optimizations are sound. We introduce KLineage, which learns this missing "when" knowledge from expert kernels: instead of relying on forward rollouts, KLineage walks expert implementations backward through validation-gated simplifications and reverses each accepted step into a reusable optimization skill. Each skill records not only the optimization intent, but also where it applies in code, what conditions made it valid, what effect it had, and what failures its assumptions avoid. A downstream LLM materializes these skills on new code surfaces under the same compile/correctness/profile gate. On five expert workloads across two NVIDIA architectures, these lineage-derived skills serve as an effective optimization curriculum, exceeding recent memory-based LLM-kernel baselines in both final kernel quality and optimization efficiency under the same fixed budget. We additionally use a separate 22-instance held-out check as a sanity test against source-case memorization.
Tessera: Unlocking Heterogeneous GPUs through Kernel-Granularity Disaggregation
Apr 11, 2026Disaggregation maps parts of an AI workload to different types of GPUs, offering a path to utilize modern heterogeneous GPU clusters. However, existing solutions operate at a coarse granularity and are tightly coupled to specific model architectures, leaving much room for performance improvement. This paper presents Tessera, the first kernel disaggregation system to improve performance and cost efficiency on heterogeneous GPUs for large model inference. Our key insight is that kernels within a single application exhibit diverse resource demands, making them the most suitable granularity for aligning computation with hardware capabilities. Tessera integrates offline analysis with online adaptation by extracting precise inter-kernel dependencies from PTX to ensure correctness, overlapping communication with computation through a pipelined execution model, and employing workload-aware scheduling with lightweight runtime adaptation. Extensive evaluations across five heterogeneous GPUs and four model architectures, scaling up to 16 GPUs, show that Tessera improves serving throughput and cost efficiency by up to 2.3x and 1.6x, respectively, compared to existing disaggregation methods, while generalizing to model architectures where prior approaches do not apply. Surprisingly, a heterogeneous GPU pair under Tessera can even exceed the throughput of two homogeneous high-end GPUs at a lower cost.
The New Compiler Stack: A Survey on the Synergy of LLMs and Compilers
Jan 05, 2026This survey has provided a systematic overview of the emerging field of LLM-enabled compilation by addressing several key research questions. We first answered how LLMs are being integrated by proposing a comprehensive, multi-dimensional taxonomy that categorizes works based on their Design Philosophy (Selector, Translator, Generator), LLM Methodology, their operational Level of Code Abstraction, and the specific Task Type they address. In answering what advancements these approaches offer, we identified three primary benefits: the democratization of compiler development, the discovery of novel optimization strategies, and the broadening of the compiler's traditional scope. Finally, in addressing the field's challenges and opportunities, we highlighted the critical hurdles of ensuring correctness and achieving scalability, while identifying the development of hybrid systems as the most promising path forward. By providing these answers, this survey serves as a foundational roadmap for researchers and practitioners, charting the course for a new generation of LLM-powered, intelligent, adaptive and synergistic compilation tools.
QiMeng: Fully Automated Hardware and Software Design for Processor Chip
Jun 05, 2025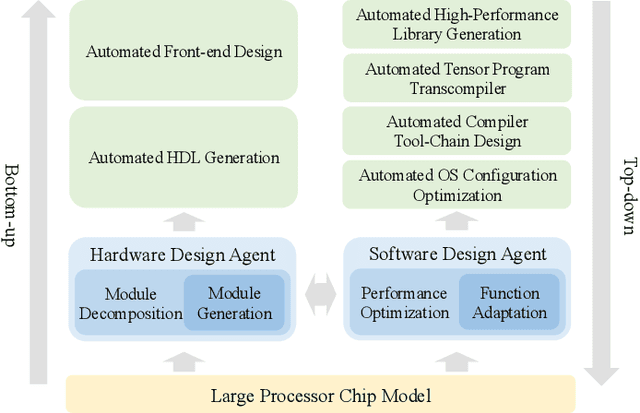
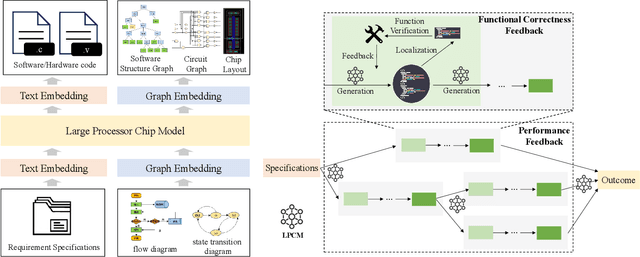
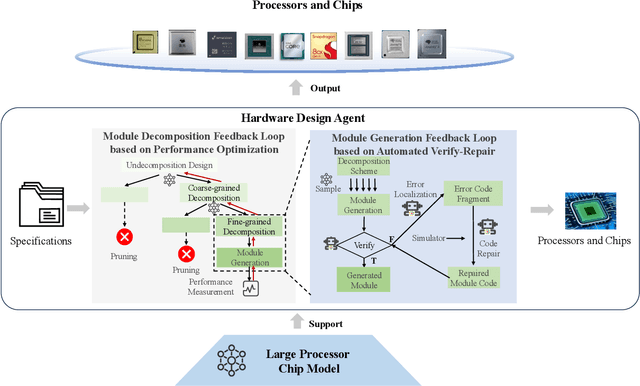
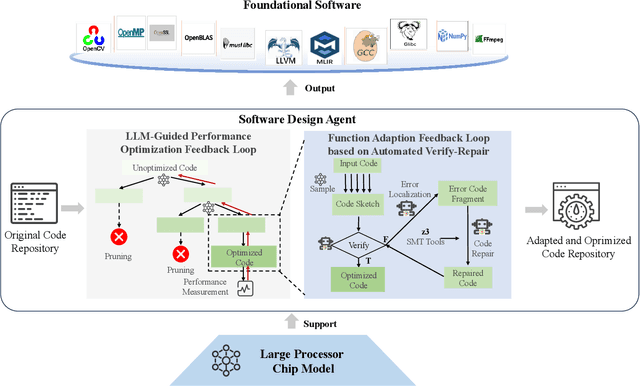
Processor chip design technology serves as a key frontier driving breakthroughs in computer science and related fields. With the rapid advancement of information technology, conventional design paradigms face three major challenges: the physical constraints of fabrication technologies, the escalating demands for design resources, and the increasing diversity of ecosystems. Automated processor chip design has emerged as a transformative solution to address these challenges. While recent breakthroughs in Artificial Intelligence (AI), particularly Large Language Models (LLMs) techniques, have opened new possibilities for fully automated processor chip design, substantial challenges remain in establishing domain-specific LLMs for processor chip design. In this paper, we propose QiMeng, a novel system for fully automated hardware and software design of processor chips. QiMeng comprises three hierarchical layers. In the bottom-layer, we construct a domain-specific Large Processor Chip Model (LPCM) that introduces novel designs in architecture, training, and inference, to address key challenges such as knowledge representation gap, data scarcity, correctness assurance, and enormous solution space. In the middle-layer, leveraging the LPCM's knowledge representation and inference capabilities, we develop the Hardware Design Agent and the Software Design Agent to automate the design of hardware and software for processor chips. Currently, several components of QiMeng have been completed and successfully applied in various top-layer applications, demonstrating significant advantages and providing a feasible solution for efficient, fully automated hardware/software design of processor chips. Future research will focus on integrating all components and performing iterative top-down and bottom-up design processes to establish a comprehensive QiMeng system.
LEGO-Compiler: Enhancing Neural Compilation Through Translation Composability
May 26, 2025



Large language models (LLMs) have the potential to revolutionize how we design and implement compilers and code translation tools. However, existing LLMs struggle to handle long and complex programs. We introduce LEGO-Compiler, a novel neural compilation system that leverages LLMs to translate high-level languages into assembly code. Our approach centers on three key innovations: LEGO translation, which decomposes the input program into manageable blocks; breaking down the complex compilation process into smaller, simpler verifiable steps by organizing it as a verifiable LLM workflow by external tests; and a feedback mechanism for self-correction. Supported by formal proofs of translation composability, LEGO-Compiler demonstrates high accuracy on multiple datasets, including over 99% on ExeBench and 97.9% on industrial-grade AnsiBench. Additionally, LEGO-Compiler has also acheived near one order-of-magnitude improvement on compilable code size scalability. This work opens new avenues for applying LLMs to system-level tasks, complementing traditional compiler technologies.
Output Constraints as Attack Surface: Exploiting Structured Generation to Bypass LLM Safety Mechanisms
Mar 31, 2025



Content Warning: This paper may contain unsafe or harmful content generated by LLMs that may be offensive to readers. Large Language Models (LLMs) are extensively used as tooling platforms through structured output APIs to ensure syntax compliance so that robust integration with existing softwares like agent systems, could be achieved. However, the feature enabling functionality of grammar-guided structured output presents significant security vulnerabilities. In this work, we reveal a critical control-plane attack surface orthogonal to traditional data-plane vulnerabilities. We introduce Constrained Decoding Attack (CDA), a novel jailbreak class that weaponizes structured output constraints to bypass safety mechanisms. Unlike prior attacks focused on input prompts, CDA operates by embedding malicious intent in schema-level grammar rules (control-plane) while maintaining benign surface prompts (data-plane). We instantiate this with a proof-of-concept Chain Enum Attack, achieves 96.2% attack success rates across proprietary and open-weight LLMs on five safety benchmarks with a single query, including GPT-4o and Gemini-2.0-flash. Our findings identify a critical security blind spot in current LLM architectures and urge a paradigm shift in LLM safety to address control-plane vulnerabilities, as current mechanisms focused solely on data-plane threats leave critical systems exposed.