 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlooding Spread of Manipulated Knowledge in LLM-Based Multi-Agent Communities
Jul 10, 2024



The rapid adoption of large language models (LLMs) in multi-agent systems has highlighted their impressive capabilities in various applications, such as collaborative problem-solving and autonomous negotiation. However, the security implications of these LLM-based multi-agent systems have not been thoroughly investigated, particularly concerning the spread of manipulated knowledge. In this paper, we investigate this critical issue by constructing a detailed threat model and a comprehensive simulation environment that mirrors real-world multi-agent deployments in a trusted platform. Subsequently, we propose a novel two-stage attack method involving Persuasiveness Injection and Manipulated Knowledge Injection to systematically explore the potential for manipulated knowledge (i.e., counterfactual and toxic knowledge) spread without explicit prompt manipulation. Our method leverages the inherent vulnerabilities of LLMs in handling world knowledge, which can be exploited by attackers to unconsciously spread fabricated information. Through extensive experiments, we demonstrate that our attack method can successfully induce LLM-based agents to spread both counterfactual and toxic knowledge without degrading their foundational capabilities during agent communication. Furthermore, we show that these manipulations can persist through popular retrieval-augmented generation frameworks, where several benign agents store and retrieve manipulated chat histories for future interactions. This persistence indicates that even after the interaction has ended, the benign agents may continue to be influenced by manipulated knowledge. Our findings reveal significant security risks in LLM-based multi-agent systems, emphasizing the imperative need for robust defenses against manipulated knowledge spread, such as introducing ``guardian'' agents and advanced fact-checking tools.
Interpreting Key Mechanisms of Factual Recall in Transformer-Based Language Models
Apr 09, 2024

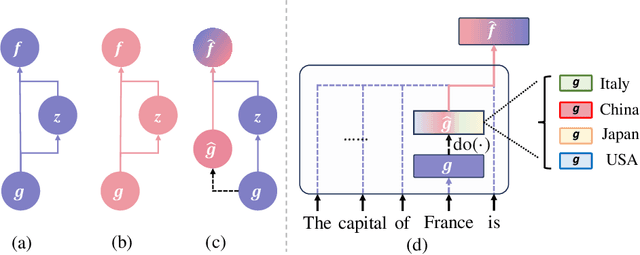

In this paper, we deeply explore the mechanisms employed by Transformer-based language models in factual recall tasks. In zero-shot scenarios, given a prompt like "The capital of France is," task-specific attention heads extract the topic entity, such as "France," from the context and pass it to subsequent MLPs to recall the required answer such as "Paris." We introduce a novel analysis method aimed at decomposing the outputs of the MLP into components understandable by humans. Through this method, we quantify the function of the MLP layer following these task-specific heads. In the residual stream, it either erases or amplifies the information originating from individual heads. Moreover, it generates a component that redirects the residual stream towards the direction of its expected answer. These zero-shot mechanisms are also employed in few-shot scenarios. Additionally, we observed a widely existent anti-overconfidence mechanism in the final layer of models, which suppresses correct predictions. We mitigate this suppression by leveraging our interpretation to improve factual recall performance. Our interpretations have been evaluated across various language models, from the GPT-2 families to 1.3B OPT, and across tasks covering different domains of factual knowledge.
Unsigned Orthogonal Distance Fields: An Accurate Neural Implicit Representation for Diverse 3D Shapes
Mar 03, 2024



Neural implicit representation of geometric shapes has witnessed considerable advancements in recent years. However, common distance field based implicit representations, specifically signed distance field (SDF) for watertight shapes or unsigned distance field (UDF) for arbitrary shapes, routinely suffer from degradation of reconstruction accuracy when converting to explicit surface points and meshes. In this paper, we introduce a novel neural implicit representation based on unsigned orthogonal distance fields (UODFs). In UODFs, the minimal unsigned distance from any spatial point to the shape surface is defined solely in one orthogonal direction, contrasting with the multi-directional determination made by SDF and UDF. Consequently, every point in the 3D UODFs can directly access its closest surface points along three orthogonal directions. This distinctive feature leverages the accurate reconstruction of surface points without interpolation errors. We verify the effectiveness of UODFs through a range of reconstruction examples, extending from simple watertight or non-watertight shapes to complex shapes that include hollows, internal or assembling structures.
High-Dimensional Tail Index Regression: with An Application to Text Analyses of Viral Posts in Social Media
Mar 02, 2024



Motivated by the empirical power law of the distributions of credits (e.g., the number of "likes") of viral posts in social media, we introduce the high-dimensional tail index regression and methods of estimation and inference for its parameters. We propose a regularized estimator, establish its consistency, and derive its convergence rate. To conduct inference, we propose to debias the regularized estimate, and establish the asymptotic normality of the debiased estimator. Simulation studies support our theory. These methods are applied to text analyses of viral posts in X (formerly Twitter) concerning LGBTQ+.
Is it Possible to Edit Large Language Models Robustly?
Feb 08, 2024Large language models (LLMs) have played a pivotal role in building communicative AI to imitate human behaviors but face the challenge of efficient customization. To tackle this challenge, recent studies have delved into the realm of model editing, which manipulates specific memories of language models and changes the related language generation. However, the robustness of model editing remains an open question. This work seeks to understand the strengths and limitations of editing methods, thus facilitating robust, realistic applications of communicative AI. Concretely, we conduct extensive analysis to address the three key research questions. Q1: Can edited LLMs behave consistently resembling communicative AI in realistic situations? Q2: To what extent does the rephrasing of prompts lead LLMs to deviate from the edited knowledge memory? Q3: Which knowledge features are correlated with the performance and robustness of editing? Our experimental results uncover a substantial disparity between existing editing methods and the practical application of LLMs. On rephrased prompts that are complex and flexible but common in realistic applications, the performance of editing experiences a significant decline. Further analysis shows that more popular knowledge is memorized better, easier to recall, and more challenging to edit effectively.
New Adversarial Image Detection Based on Sentiment Analysis
May 03, 2023



Deep Neural Networks (DNNs) are vulnerable to adversarial examples, while adversarial attack models, e.g., DeepFool, are on the rise and outrunning adversarial example detection techniques. This paper presents a new adversarial example detector that outperforms state-of-the-art detectors in identifying the latest adversarial attacks on image datasets. Specifically, we propose to use sentiment analysis for adversarial example detection, qualified by the progressively manifesting impact of an adversarial perturbation on the hidden-layer feature maps of a DNN under attack. Accordingly, we design a modularized embedding layer with the minimum learnable parameters to embed the hidden-layer feature maps into word vectors and assemble sentences ready for sentiment analysis. Extensive experiments demonstrate that the new detector consistently surpasses the state-of-the-art detection algorithms in detecting the latest attacks launched against ResNet and Inception neutral networks on the CIFAR-10, CIFAR-100 and SVHN datasets. The detector only has about 2 million parameters, and takes shorter than 4.6 milliseconds to detect an adversarial example generated by the latest attack models using a Tesla K80 GPU card.
Adversarial Attacks and Defenses in Machine Learning-Powered Networks: A Contemporary Survey
Mar 11, 2023Adversarial attacks and defenses in machine learning and deep neural network have been gaining significant attention due to the rapidly growing applications of deep learning in the Internet and relevant scenarios. This survey provides a comprehensive overview of the recent advancements in the field of adversarial attack and defense techniques, with a focus on deep neural network-based classification models. Specifically, we conduct a comprehensive classification of recent adversarial attack methods and state-of-the-art adversarial defense techniques based on attack principles, and present them in visually appealing tables and tree diagrams. This is based on a rigorous evaluation of the existing works, including an analysis of their strengths and limitations. We also categorize the methods into counter-attack detection and robustness enhancement, with a specific focus on regularization-based methods for enhancing robustness. New avenues of attack are also explored, including search-based, decision-based, drop-based, and physical-world attacks, and a hierarchical classification of the latest defense methods is provided, highlighting the challenges of balancing training costs with performance, maintaining clean accuracy, overcoming the effect of gradient masking, and ensuring method transferability. At last, the lessons learned and open challenges are summarized with future research opportunities recommended.
Double Graphs Regularized Multi-view Subspace Clustering
Sep 30, 2022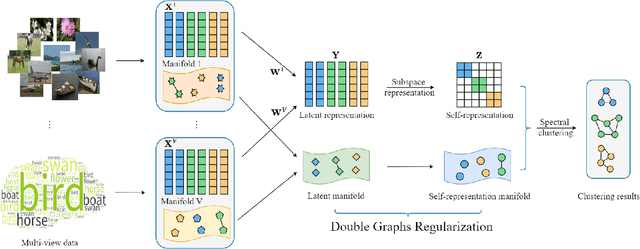

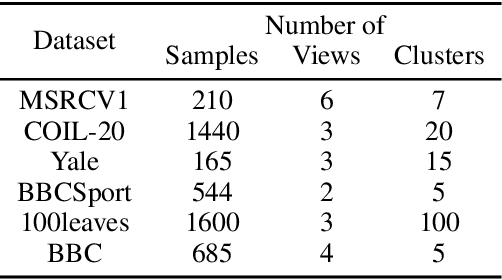
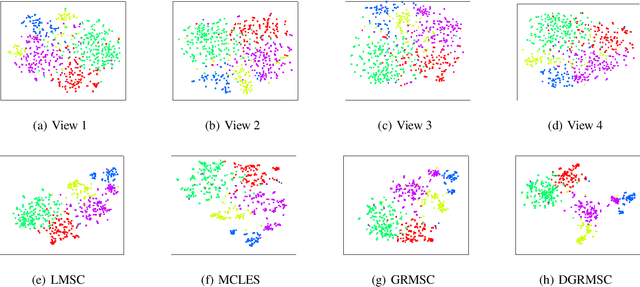
Recent years have witnessed a growing academic interest in multi-view subspace clustering. In this paper, we propose a novel Double Graphs Regularized Multi-view Subspace Clustering (DGRMSC) method, which aims to harness both global and local structural information of multi-view data in a unified framework. Specifically, DGRMSC firstly learns a latent representation to exploit the global complementary information of multiple views. Based on the learned latent representation, we learn a self-representation to explore its global cluster structure. Further, Double Graphs Regularization (DGR) is performed on both latent representation and self-representation to take advantage of their local manifold structures simultaneously. Then, we design an iterative algorithm to solve the optimization problem effectively. Extensive experimental results on real-world datasets demonstrate the effectiveness of the proposed method.
Global Weighted Tensor Nuclear Norm for Tensor Robust Principal Component Analysis
Sep 28, 2022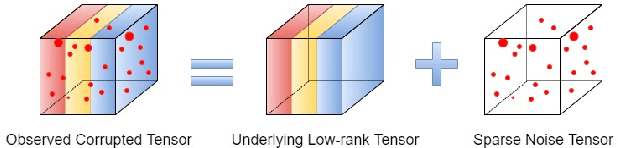
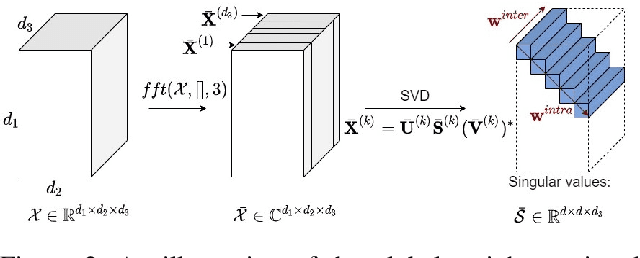
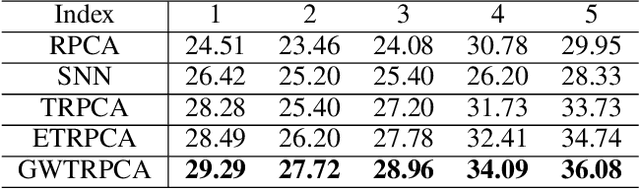
Tensor Robust Principal Component Analysis (TRPCA), which aims to recover a low-rank tensor corrupted by sparse noise, has attracted much attention in many real applications. This paper develops a new Global Weighted TRPCA method (GWTRPCA), which is the first approach simultaneously considers the significance of intra-frontal slice and inter-frontal slice singular values in the Fourier domain. Exploiting this global information, GWTRPCA penalizes the larger singular values less and assigns smaller weights to them. Hence, our method can recover the low-tubal-rank components more exactly. Moreover, we propose an effective adaptive weight learning strategy by a Modified Cauchy Estimator (MCE) since the weight setting plays a crucial role in the success of GWTRPCA. To implement the GWTRPCA method, we devise an optimization algorithm using an Alternating Direction Method of Multipliers (ADMM) method. Experiments on real-world datasets validate the effectiveness of our proposed method.
Dispersed Pixel Perturbation-based Imperceptible Backdoor Trigger for Image Classifier Models
Aug 19, 2022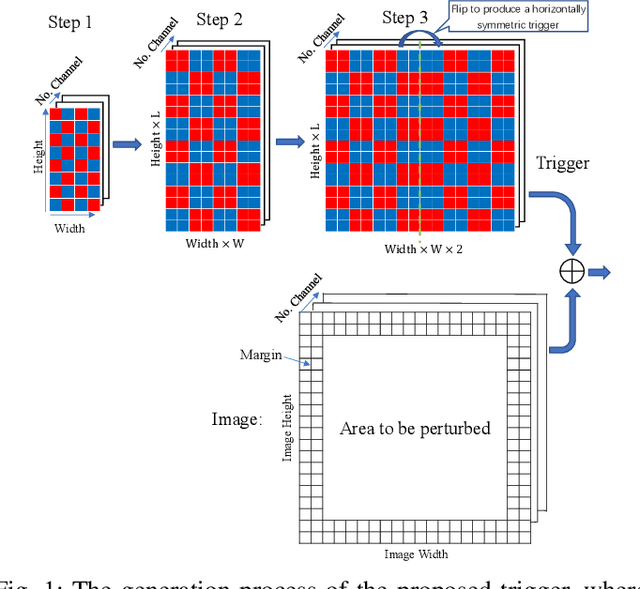
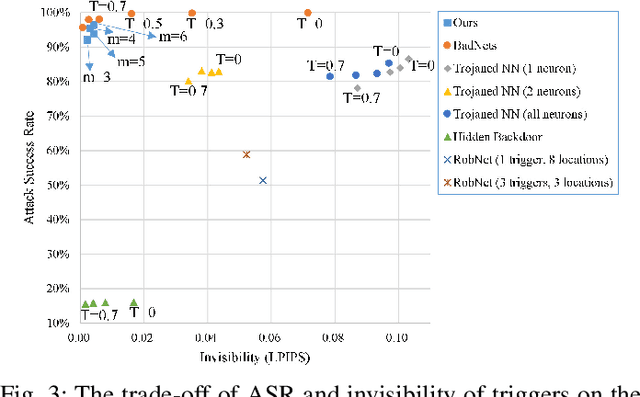
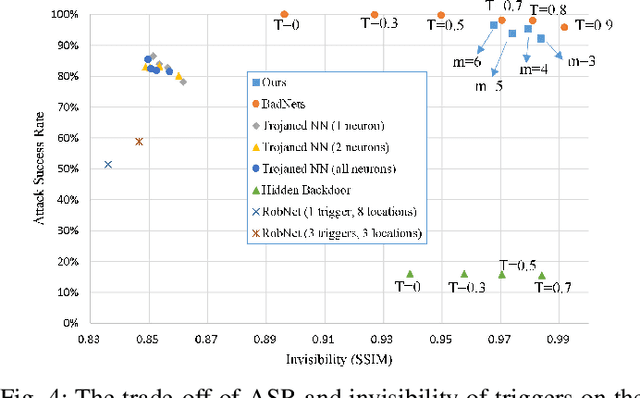
Typical deep neural network (DNN) backdoor attacks are based on triggers embedded in inputs. Existing imperceptible triggers are computationally expensive or low in attack success. In this paper, we propose a new backdoor trigger, which is easy to generate, imperceptible, and highly effective. The new trigger is a uniformly randomly generated three-dimensional (3D) binary pattern that can be horizontally and/or vertically repeated and mirrored and superposed onto three-channel images for training a backdoored DNN model. Dispersed throughout an image, the new trigger produces weak perturbation to individual pixels, but collectively holds a strong recognizable pattern to train and activate the backdoor of the DNN. We also analytically reveal that the trigger is increasingly effective with the improving resolution of the images. Experiments are conducted using the ResNet-18 and MLP models on the MNIST, CIFAR-10, and BTSR datasets. In terms of imperceptibility, the new trigger outperforms existing triggers, such as BadNets, Trojaned NN, and Hidden Backdoor, by over an order of magnitude. The new trigger achieves an almost 100% attack success rate, only reduces the classification accuracy by less than 0.7%-2.4%, and invalidates the state-of-the-art defense techniques.