 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimplicity Prevails: The Emergence of Generalizable AIGI Detection in Visual Foundation Models
Feb 02, 2026While specialized detectors for AI-Generated Images (AIGI) achieve near-perfect accuracy on curated benchmarks, they suffer from a dramatic performance collapse in realistic, in-the-wild scenarios. In this work, we demonstrate that simplicity prevails over complex architectural designs. A simple linear classifier trained on the frozen features of modern Vision Foundation Models , including Perception Encoder, MetaCLIP 2, and DINOv3, establishes a new state-of-the-art. Through a comprehensive evaluation spanning traditional benchmarks, unseen generators, and challenging in-the-wild distributions, we show that this baseline not only matches specialized detectors on standard benchmarks but also decisively outperforms them on in-the-wild datasets, boosting accuracy by striking margins of over 30\%. We posit that this superior capability is an emergent property driven by the massive scale of pre-training data containing synthetic content. We trace the source of this capability to two distinct manifestations of data exposure: Vision-Language Models internalize an explicit semantic concept of forgery, while Self-Supervised Learning models implicitly acquire discriminative forensic features from the pretraining data. However, we also reveal persistent limitations: these models suffer from performance degradation under recapture and transmission, remain blind to VAE reconstruction and localized editing. We conclude by advocating for a paradigm shift in AI forensics, moving from overfitting on static benchmarks to harnessing the evolving world knowledge of foundation models for real-world reliability.
MPF-Net: Exposing High-Fidelity AI-Generated Video Forgeries via Hierarchical Manifold Deviation and Micro-Temporal Fluctuations
Jan 29, 2026With the rapid advancement of video generation models such as Veo and Wan, the visual quality of synthetic content has reached a level where macro-level semantic errors and temporal inconsistencies are no longer prominent. However, this does not imply that the distinction between real and cutting-edge high-fidelity fake is untraceable. We argue that AI-generated videos are essentially products of a manifold-fitting process rather than a physical recording. Consequently, the pixel composition logic of consecutive adjacent frames residual in AI videos exhibits a structured and homogenous characteristic. We term this phenomenon `Manifold Projection Fluctuations' (MPF). Driven by this insight, we propose a hierarchical dual-path framework that operates as a sequential filtering process. The first, the Static Manifold Deviation Branch, leverages the refined perceptual boundaries of Large-Scale Vision Foundation Models (VFMs) to capture residual spatial anomalies or physical violations that deviate from the natural real-world manifold (off-manifold). For the remaining high-fidelity videos that successfully reside on-manifold and evade spatial detection, we introduce the Micro-Temporal Fluctuation Branch as a secondary, fine-grained filter. By analyzing the structured MPF that persists even in visually perfect sequences, our framework ensures that forgeries are exposed regardless of whether they manifest as global real-world manifold deviations or subtle computational fingerprints.
Where It Moves, It Matters: Referring Surgical Instrument Segmentation via Motion
Jan 18, 2026Enabling intuitive, language-driven interaction with surgical scenes is a critical step toward intelligent operating rooms and autonomous surgical robotic assistance. However, the task of referring segmentation, localizing surgical instruments based on natural language descriptions, remains underexplored in surgical videos, with existing approaches struggling to generalize due to reliance on static visual cues and predefined instrument names. In this work, we introduce SurgRef, a novel motion-guided framework that grounds free-form language expressions in instrument motion, capturing how tools move and interact across time, rather than what they look like. This allows models to understand and segment instruments even under occlusion, ambiguity, or unfamiliar terminology. To train and evaluate SurgRef, we present Ref-IMotion, a diverse, multi-institutional video dataset with dense spatiotemporal masks and rich motion-centric expressions. SurgRef achieves state-of-the-art accuracy and generalization across surgical procedures, setting a new benchmark for robust, language-driven surgical video segmentation.
SurgGoal: Rethinking Surgical Planning Evaluation via Goal-Satisfiability
Jan 15, 2026Surgical planning integrates visual perception, long-horizon reasoning, and procedural knowledge, yet it remains unclear whether current evaluation protocols reliably assess vision-language models (VLMs) in safety-critical settings. Motivated by a goal-oriented view of surgical planning, we define planning correctness via phase-goal satisfiability, where plan validity is determined by expert-defined surgical rules. Based on this definition, we introduce a multicentric meta-evaluation benchmark with valid procedural variations and invalid plans containing order and content errors. Using this benchmark, we show that sequence similarity metrics systematically misjudge planning quality, penalizing valid plans while failing to identify invalid ones. We therefore adopt a rule-based goal-satisfiability metric as a high-precision meta-evaluation reference to assess Video-LLMs under progressively constrained settings, revealing failures due to perception errors and under-constrained reasoning. Structural knowledge consistently improves performance, whereas semantic guidance alone is unreliable and benefits larger models only when combined with structural constraints.
Amory: Building Coherent Narrative-Driven Agent Memory through Agentic Reasoning
Jan 09, 2026Long-term conversational agents face a fundamental scalability challenge as interactions extend over time: repeatedly processing entire conversation histories becomes computationally prohibitive. Current approaches attempt to solve this through memory frameworks that predominantly fragment conversations into isolated embeddings or graph representations and retrieve relevant ones in a RAG style. While computationally efficient, these methods often treat memory formation minimally and fail to capture the subtlety and coherence of human memory. We introduce Amory, a working memory framework that actively constructs structured memory representations through enhancing agentic reasoning during offline time. Amory organizes conversational fragments into episodic narratives, consolidates memories with momentum, and semanticizes peripheral facts into semantic memory. At retrieval time, the system employs coherence-driven reasoning over narrative structures. Evaluated on the LOCOMO benchmark for long-term reasoning, Amory achieves considerable improvements over previous state-of-the-art, with performance comparable to full context reasoning while reducing response time by 50%. Analysis shows that momentum-aware consolidation significantly enhances response quality, while coherence-driven retrieval provides superior memory coverage compared to embedding-based approaches.
AirSpatialBot: A Spatially-Aware Aerial Agent for Fine-Grained Vehicle Attribute Recognization and Retrieval
Jan 04, 2026Despite notable advancements in remote sensing vision-language models (VLMs), existing models often struggle with spatial understanding, limiting their effectiveness in real-world applications. To push the boundaries of VLMs in remote sensing, we specifically address vehicle imagery captured by drones and introduce a spatially-aware dataset AirSpatial, which comprises over 206K instructions and introduces two novel tasks: Spatial Grounding and Spatial Question Answering. It is also the first remote sensing grounding dataset to provide 3DBB. To effectively leverage existing image understanding of VLMs to spatial domains, we adopt a two-stage training strategy comprising Image Understanding Pre-training and Spatial Understanding Fine-tuning. Utilizing this trained spatially-aware VLM, we develop an aerial agent, AirSpatialBot, which is capable of fine-grained vehicle attribute recognition and retrieval. By dynamically integrating task planning, image understanding, spatial understanding, and task execution capabilities, AirSpatialBot adapts to diverse query requirements. Experimental results validate the effectiveness of our approach, revealing the spatial limitations of existing VLMs while providing valuable insights. The model, code, and datasets will be released at https://github.com/VisionXLab/AirSpatialBot
DVGBench: Implicit-to-Explicit Visual Grounding Benchmark in UAV Imagery with Large Vision-Language Models
Jan 02, 2026Remote sensing (RS) large vision-language models (LVLMs) have shown strong promise across visual grounding (VG) tasks. However, existing RS VG datasets predominantly rely on explicit referring expressions-such as relative position, relative size, and color cues-thereby constraining performance on implicit VG tasks that require scenario-specific domain knowledge. This article introduces DVGBench, a high-quality implicit VG benchmark for drones, covering six major application scenarios: traffic, disaster, security, sport, social activity, and productive activity. Each object provides both explicit and implicit queries. Based on the dataset, we design DroneVG-R1, an LVLM that integrates the novel Implicit-to-Explicit Chain-of-Thought (I2E-CoT) within a reinforcement learning paradigm. This enables the model to take advantage of scene-specific expertise, converting implicit references into explicit ones and thus reducing grounding difficulty. Finally, an evaluation of mainstream models on both explicit and implicit VG tasks reveals substantial limitations in their reasoning capabilities. These findings provide actionable insights for advancing the reasoning capacity of LVLMs for drone-based agents. The code and datasets will be released at https://github.com/zytx121/DVGBench
Foundation Visual Encoders Are Secretly Few-Shot Anomaly Detectors
Oct 02, 2025Few-shot anomaly detection streamlines and simplifies industrial safety inspection. However, limited samples make accurate differentiation between normal and abnormal features challenging, and even more so under category-agnostic conditions. Large-scale pre-training of foundation visual encoders has advanced many fields, as the enormous quantity of data helps to learn the general distribution of normal images. We observe that the anomaly amount in an image directly correlates with the difference in the learnt embeddings and utilize this to design a few-shot anomaly detector termed FoundAD. This is done by learning a nonlinear projection operator onto the natural image manifold. The simple operator acts as an effective tool for anomaly detection to characterize and identify out-of-distribution regions in an image. Extensive experiments show that our approach supports multi-class detection and achieves competitive performance while using substantially fewer parameters than prior methods. Backed up by evaluations with multiple foundation encoders, including fresh DINOv3, we believe this idea broadens the perspective on foundation features and advances the field of few-shot anomaly detection.
Brought a Gun to a Knife Fight: Modern VFM Baselines Outgun Specialized Detectors on In-the-Wild AI Image Detection
Sep 16, 2025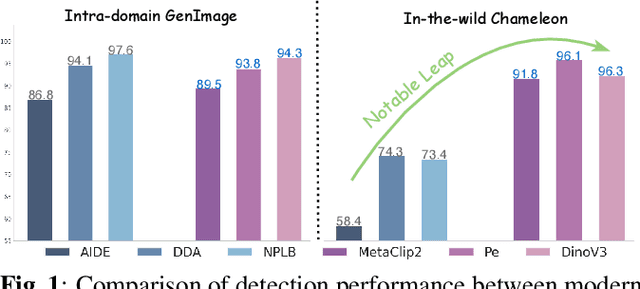
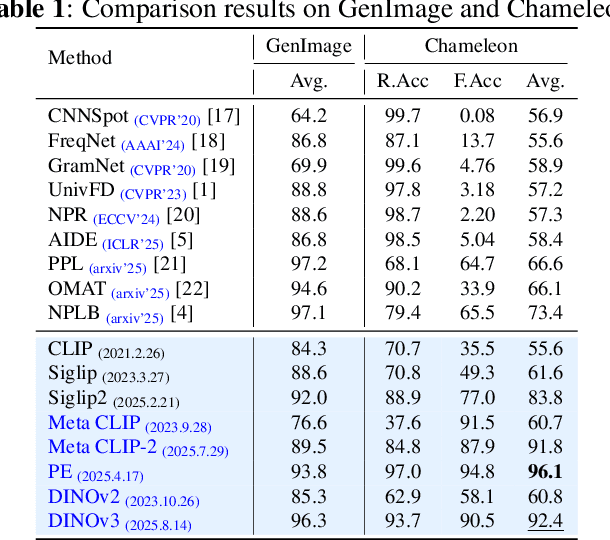
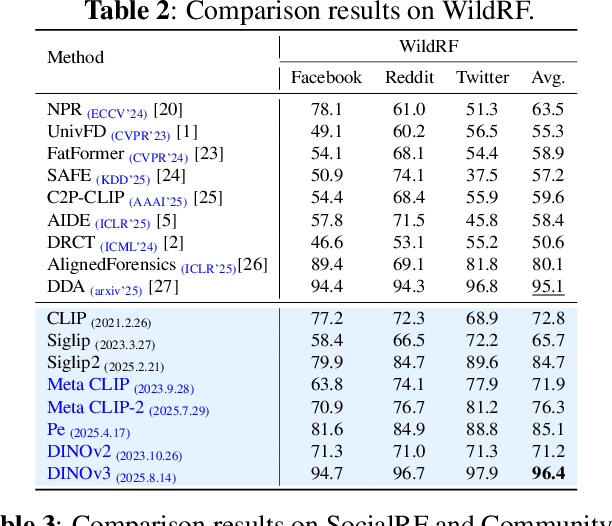
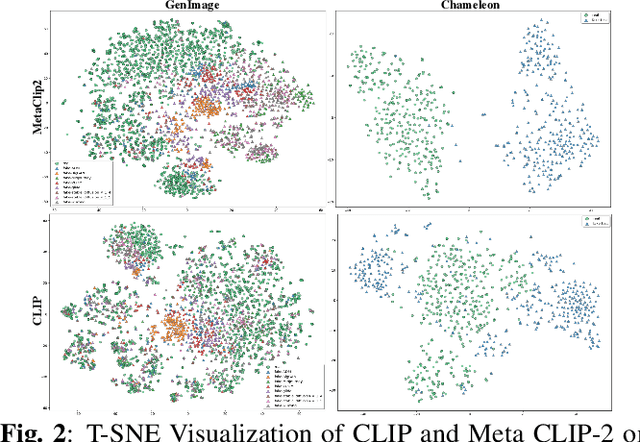
While specialized detectors for AI-generated images excel on curated benchmarks, they fail catastrophically in real-world scenarios, as evidenced by their critically high false-negative rates on `in-the-wild' benchmarks. Instead of crafting another specialized `knife' for this problem, we bring a `gun' to the fight: a simple linear classifier on a modern Vision Foundation Model (VFM). Trained on identical data, this baseline decisively `outguns' bespoke detectors, boosting in-the-wild accuracy by a striking margin of over 20\%. Our analysis pinpoints the source of the VFM's `firepower': First, by probing text-image similarities, we find that recent VLMs (e.g., Perception Encoder, Meta CLIP2) have learned to align synthetic images with forgery-related concepts (e.g., `AI-generated'), unlike previous versions. Second, we speculate that this is due to data exposure, as both this alignment and overall accuracy plummet on a novel dataset scraped after the VFM's pre-training cut-off date, ensuring it was unseen during pre-training. Our findings yield two critical conclusions: 1) For the real-world `gunfight' of AI-generated image detection, the raw `firepower' of an updated VFM is far more effective than the `craftsmanship' of a static detector. 2) True generalization evaluation requires test data to be independent of the model's entire training history, including pre-training.
Broadband Near-Infrared Compressive Spectral Imaging System with Reflective Structure
Aug 20, 2025



Near-infrared (NIR) hyperspectral imaging has become a critical tool in modern analytical science. However, conventional NIR hyperspectral imaging systems face challenges including high cost, bulky instrumentation, and inefficient data collection. In this work, we demonstrate a broadband NIR compressive spectral imaging system that is capable of capturing hyperspectral data covering a broad spectral bandwidth ranging from 700 to 1600 nm. By segmenting wavelengths and designing specialized optical components, our design overcomes hardware spectral limitations to capture broadband data, while the reflective optical structure makes the system compact. This approach provides a novel technical solution for NIR hyperspectral imaging.