 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoVLM: Measurement-Grounded Multimodal Learning for Echocardiography
Dec 13, 2025Echocardiography is the most widely used imaging modality in cardiology, yet its interpretation remains labor-intensive and inherently multimodal, requiring view recognition, quantitative measurements, qualitative assessments, and guideline-based reasoning. While recent vision-language models (VLMs) have achieved broad success in natural images and certain medical domains, their potential in echocardiography has been limited by the lack of large-scale, clinically grounded image-text datasets and the absence of measurement-based reasoning central to echo interpretation. We introduce EchoGround-MIMIC, the first measurement-grounded multimodal echocardiography dataset, comprising 19,065 image-text pairs from 1,572 patients with standardized views, structured measurements, measurement-grounded captions, and guideline-derived disease labels. Building on this resource, we propose EchoVLM, a vision-language model that incorporates two novel pretraining objectives: (i) a view-informed contrastive loss that encodes the view-dependent structure of echocardiographic imaging, and (ii) a negation-aware contrastive loss that distinguishes clinically critical negative from positive findings. Across five types of clinical applications with 36 tasks spanning multimodal disease classification, image-text retrieval, view classification, chamber segmentation, and landmark detection, EchoVLM achieves state-of-the-art performance (86.5% AUC in zero-shot disease classification and 95.1% accuracy in view classification). We demonstrate that clinically grounded multimodal pretraining yields transferable visual representations and establish EchoVLM as a foundation model for end-to-end echocardiography interpretation. We will release EchoGround-MIMIC and the data curation code, enabling reproducibility and further research in multimodal echocardiography interpretation.
MedForget: Hierarchy-Aware Multimodal Unlearning Testbed for Medical AI
Dec 10, 2025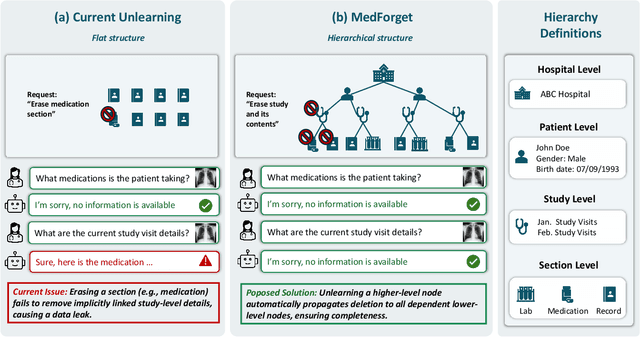

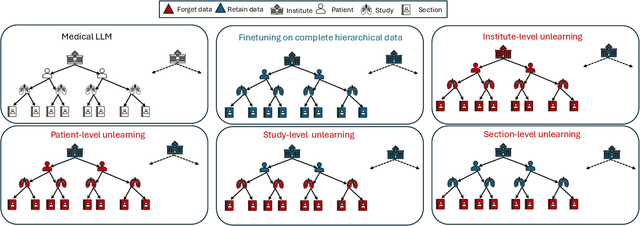

Pretrained Multimodal Large Language Models (MLLMs) are increasingly deployed in medical AI systems for clinical reasoning, diagnosis support, and report generation. However, their training on sensitive patient data raises critical privacy and compliance challenges under regulations such as HIPAA and GDPR, which enforce the "right to be forgotten". Unlearning, the process of tuning models to selectively remove the influence of specific training data points, offers a potential solution, yet its effectiveness in complex medical settings remains underexplored. To systematically study this, we introduce MedForget, a Hierarchy-Aware Multimodal Unlearning Testbed with explicit retain and forget splits and evaluation sets containing rephrased variants. MedForget models hospital data as a nested hierarchy (Institution -> Patient -> Study -> Section), enabling fine-grained assessment across eight organizational levels. The benchmark contains 3840 multimodal (image, question, answer) instances, each hierarchy level having a dedicated unlearning target, reflecting distinct unlearning challenges. Experiments with four SOTA unlearning methods on three tasks (generation, classification, cloze) show that existing methods struggle to achieve complete, hierarchy-aware forgetting without reducing diagnostic performance. To test whether unlearning truly deletes hierarchical pathways, we introduce a reconstruction attack that progressively adds hierarchical level context to prompts. Models unlearned at a coarse granularity show strong resistance, while fine-grained unlearning leaves models vulnerable to such reconstruction. MedForget provides a practical, HIPAA-aligned testbed for building compliant medical AI systems.
Error-Driven Scene Editing for 3D Grounding in Large Language Models
Nov 18, 2025Despite recent progress in 3D-LLMs, they remain limited in accurately grounding language to visual and spatial elements in 3D environments. This limitation stems in part from training data that focuses on language reasoning rather than spatial understanding due to scarce 3D resources, leaving inherent grounding biases unresolved. To address this, we propose 3D scene editing as a key mechanism to generate precise visual counterfactuals that mitigate these biases through fine-grained spatial manipulation, without requiring costly scene reconstruction or large-scale 3D data collection. Furthermore, to make these edits targeted and directly address the specific weaknesses of the model, we introduce DEER-3D, an error-driven framework following a structured "Decompose, Diagnostic Evaluation, Edit, and Re-train" workflow, rather than broadly or randomly augmenting data as in conventional approaches. Specifically, upon identifying a grounding failure of the 3D-LLM, our framework first diagnoses the exact predicate-level error (e.g., attribute or spatial relation). It then executes minimal, predicate-aligned 3D scene edits, such as recoloring or repositioning, to produce targeted counterfactual supervision for iterative model fine-tuning, significantly enhancing grounding accuracy. We evaluate our editing pipeline across multiple benchmarks for 3D grounding and scene understanding tasks, consistently demonstrating improvements across all evaluated datasets through iterative refinement. DEER-3D underscores the effectiveness of targeted, error-driven scene editing in bridging linguistic reasoning capabilities with spatial grounding in 3D LLMs.
Imagine in Space: Exploring the Frontier of Spatial Intelligence and Reasoning Efficiency in Vision Language Models
Nov 16, 2025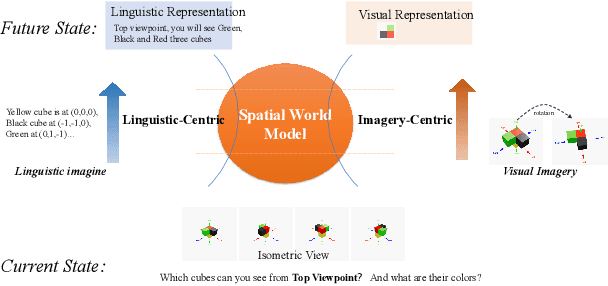
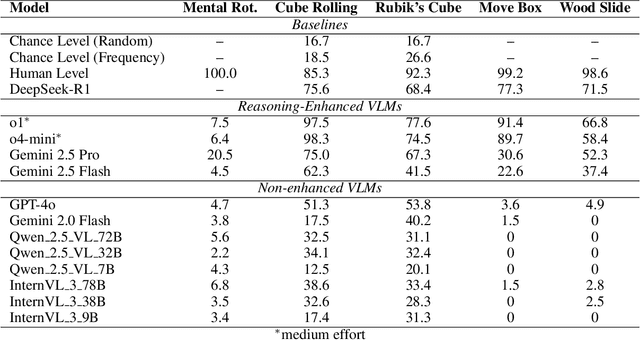
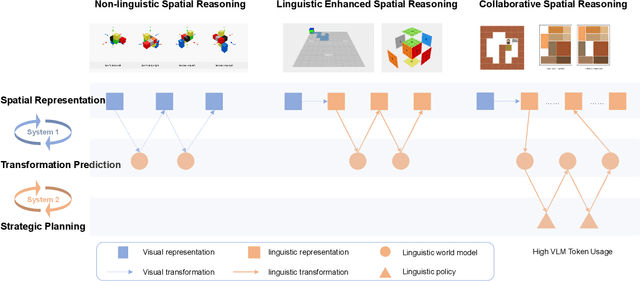

Large language models (LLMs) and vision language models (VLMs), such as DeepSeek R1,OpenAI o3, and Gemini 2.5 Pro, have demonstrated remarkable reasoning capabilities across logical inference, problem solving, and decision making. However, spatial reasoning:a fundamental component of human cognition that includes mental rotation, navigation, and spatial relationship comprehension remains a significant challenge for current advanced VLMs. We hypothesize that imagination, the internal simulation of spatial states, is the dominant reasoning mechanism within a spatial world model. To test this hypothesis and systematically probe current VLM spatial reasoning mechanisms, we introduce SpatiaLite, a fully synthetic benchmark that jointly measures spatial reasoning accuracy and reasoning efficiency. Comprehensive experiments reveal three key findings. First, advanced VLMs predominantly rely on linguistic representations for reasoning and imagination, resulting in significant deficiencies on visual centric tasks that demand perceptual spatial relations and 3D geometry transformations such as mental rotation or projection prediction. Second, advanced VLMs exhibit severe inefficiency in their current spatial reasoning mechanisms, with token usage growing rapidly as transformation complexity increases. Third, we propose an Imagery Driven Framework (IDF) for data synthesis and training, which can implicitly construct an internal world model that is critical for spatial reasoning in VLMs. Building on SpatiaLite, this work delineates the spatial reasoning limits and patterns of advanced VLMs, identifies key shortcomings, and informs future advances
Burst Image Quality Assessment: A New Benchmark and Unified Framework for Multiple Downstream Tasks
Nov 11, 2025



In recent years, the development of burst imaging technology has improved the capture and processing capabilities of visual data, enabling a wide range of applications. However, the redundancy in burst images leads to the increased storage and transmission demands, as well as reduced efficiency of downstream tasks. To address this, we propose a new task of Burst Image Quality Assessment (BuIQA), to evaluate the task-driven quality of each frame within a burst sequence, providing reasonable cues for burst image selection. Specifically, we establish the first benchmark dataset for BuIQA, consisting of $7,346$ burst sequences with $45,827$ images and $191,572$ annotated quality scores for multiple downstream scenarios. Inspired by the data analysis, a unified BuIQA framework is proposed to achieve an efficient adaption for BuIQA under diverse downstream scenarios. Specifically, a task-driven prompt generation network is developed with heterogeneous knowledge distillation, to learn the priors of the downstream task. Then, the task-aware quality assessment network is introduced to assess the burst image quality based on the task prompt. Extensive experiments across 10 downstream scenarios demonstrate the impressive BuIQA performance of the proposed approach, outperforming the state-of-the-art. Furthermore, it can achieve $0.33$ dB PSNR improvement in the downstream tasks of denoising and super-resolution, by applying our approach to select the high-quality burst frames.
Rethinking Robust Adversarial Concept Erasure in Diffusion Models
Oct 31, 2025Concept erasure aims to selectively unlearning undesirable content in diffusion models (DMs) to reduce the risk of sensitive content generation. As a novel paradigm in concept erasure, most existing methods employ adversarial training to identify and suppress target concepts, thus reducing the likelihood of sensitive outputs. However, these methods often neglect the specificity of adversarial training in DMs, resulting in only partial mitigation. In this work, we investigate and quantify this specificity from the perspective of concept space, i.e., can adversarial samples truly fit the target concept space? We observe that existing methods neglect the role of conceptual semantics when generating adversarial samples, resulting in ineffective fitting of concept spaces. This oversight leads to the following issues: 1) when there are few adversarial samples, they fail to comprehensively cover the object concept; 2) conversely, they will disrupt other target concept spaces. Motivated by the analysis of these findings, we introduce S-GRACE (Semantics-Guided Robust Adversarial Concept Erasure), which grace leveraging semantic guidance within the concept space to generate adversarial samples and perform erasure training. Experiments conducted with seven state-of-the-art methods and three adversarial prompt generation strategies across various DM unlearning scenarios demonstrate that S-GRACE significantly improves erasure performance 26%, better preserves non-target concepts, and reduces training time by 90%. Our code is available at https://github.com/Qhong-522/S-GRACE.
PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model
Oct 16, 2025In this report, we propose PaddleOCR-VL, a SOTA and resource-efficient model tailored for document parsing. Its core component is PaddleOCR-VL-0.9B, a compact yet powerful vision-language model (VLM) that integrates a NaViT-style dynamic resolution visual encoder with the ERNIE-4.5-0.3B language model to enable accurate element recognition. This innovative model efficiently supports 109 languages and excels in recognizing complex elements (e.g., text, tables, formulas, and charts), while maintaining minimal resource consumption. Through comprehensive evaluations on widely used public benchmarks and in-house benchmarks, PaddleOCR-VL achieves SOTA performance in both page-level document parsing and element-level recognition. It significantly outperforms existing solutions, exhibits strong competitiveness against top-tier VLMs, and delivers fast inference speeds. These strengths make it highly suitable for practical deployment in real-world scenarios.
LOGicalThought: Logic-Based Ontological Grounding of LLMs for High-Assurance Reasoning
Oct 02, 2025High-assurance reasoning, particularly in critical domains such as law and medicine, requires conclusions that are accurate, verifiable, and explicitly grounded in evidence. This reasoning relies on premises codified from rules, statutes, and contracts, inherently involving defeasible or non-monotonic logic due to numerous exceptions, where the introduction of a single fact can invalidate general rules, posing significant challenges. While large language models (LLMs) excel at processing natural language, their capabilities in standard inference tasks do not translate to the rigorous reasoning required over high-assurance text guidelines. Core reasoning challenges within such texts often manifest specific logical structures involving negation, implication, and, most critically, defeasible rules and exceptions. In this paper, we propose a novel neurosymbolically-grounded architecture called LOGicalThought (LogT) that uses an advanced logical language and reasoner in conjunction with an LLM to construct a dual symbolic graph context and logic-based context. These two context representations transform the problem from inference over long-form guidelines into a compact grounded evaluation. Evaluated on four multi-domain benchmarks against four baselines, LogT improves overall performance by 11.84% across all LLMs. Performance improves significantly across all three modes of reasoning: by up to +10.2% on negation, +13.2% on implication, and +5.5% on defeasible reasoning compared to the strongest baseline.
DeepScientist: Advancing Frontier-Pushing Scientific Findings Progressively
Sep 30, 2025



While previous AI Scientist systems can generate novel findings, they often lack the focus to produce scientifically valuable contributions that address pressing human-defined challenges. We introduce DeepScientist, a system designed to overcome this by conducting goal-oriented, fully autonomous scientific discovery over month-long timelines. It formalizes discovery as a Bayesian Optimization problem, operationalized through a hierarchical evaluation process consisting of "hypothesize, verify, and analyze". Leveraging a cumulative Findings Memory, this loop intelligently balances the exploration of novel hypotheses with exploitation, selectively promoting the most promising findings to higher-fidelity levels of validation. Consuming over 20,000 GPU hours, the system generated about 5,000 unique scientific ideas and experimentally validated approximately 1100 of them, ultimately surpassing human-designed state-of-the-art (SOTA) methods on three frontier AI tasks by 183.7\%, 1.9\%, and 7.9\%. This work provides the first large-scale evidence of an AI achieving discoveries that progressively surpass human SOTA on scientific tasks, producing valuable findings that genuinely push the frontier of scientific discovery. To facilitate further research into this process, we will open-source all experimental logs and system code at https://github.com/ResearAI/DeepScientist/.
Uncertainty-Gated Deformable Network for Breast Tumor Segmentation in MR Images
Sep 19, 2025



Accurate segmentation of breast tumors in magnetic resonance images (MRI) is essential for breast cancer diagnosis, yet existing methods face challenges in capturing irregular tumor shapes and effectively integrating local and global features. To address these limitations, we propose an uncertainty-gated deformable network to leverage the complementary information from CNN and Transformers. Specifically, we incorporates deformable feature modeling into both convolution and attention modules, enabling adaptive receptive fields for irregular tumor contours. We also design an Uncertainty-Gated Enhancing Module (U-GEM) to selectively exchange complementary features between CNN and Transformer based on pixel-wise uncertainty, enhancing both local and global representations. Additionally, a Boundary-sensitive Deep Supervision Loss is introduced to further improve tumor boundary delineation. Comprehensive experiments on two clinical breast MRI datasets demonstrate that our method achieves superior segmentation performance compared with state-of-the-art methods, highlighting its clinical potential for accurate breast tumor delineation.