 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Robustness of LLM-Synthetic Text Detectors for Academic Writing: A Comprehensive Analysis
Jan 16, 2024The emergence of large language models (LLMs), such as Generative Pre-trained Transformer 4 (GPT-4) used by ChatGPT, has profoundly impacted the academic and broader community. While these models offer numerous advantages in terms of revolutionizing work and study methods, they have also garnered significant attention due to their potential negative consequences. One example is generating academic reports or papers with little to no human contribution. Consequently, researchers have focused on developing detectors to address the misuse of LLMs. However, most existing methods prioritize achieving higher accuracy on restricted datasets, neglecting the crucial aspect of generalizability. This limitation hinders their practical application in real-life scenarios where reliability is paramount. In this paper, we present a comprehensive analysis of the impact of prompts on the text generated by LLMs and highlight the potential lack of robustness in one of the current state-of-the-art GPT detectors. To mitigate these issues concerning the misuse of LLMs in academic writing, we propose a reference-based Siamese detector named Synthetic-Siamese which takes a pair of texts, one as the inquiry and the other as the reference. Our method effectively addresses the lack of robustness of previous detectors (OpenAI detector and DetectGPT) and significantly improves the baseline performances in realistic academic writing scenarios by approximately 67% to 95%.
Human-Machine Cooperative Multimodal Learning Method for Cross-subject Olfactory Preference Recognition
Nov 24, 2023Odor sensory evaluation has a broad application in food, clothing, cosmetics, and other fields. Traditional artificial sensory evaluation has poor repeatability, and the machine olfaction represented by the electronic nose (E-nose) is difficult to reflect human feelings. Olfactory electroencephalogram (EEG) contains odor and individual features associated with human olfactory preference, which has unique advantages in odor sensory evaluation. However, the difficulty of cross-subject olfactory EEG recognition greatly limits its application. It is worth noting that E-nose and olfactory EEG are more advantageous in representing odor information and individual emotions, respectively. In this paper, an E-nose and olfactory EEG multimodal learning method is proposed for cross-subject olfactory preference recognition. Firstly, the olfactory EEG and E-nose multimodal data acquisition and preprocessing paradigms are established. Secondly, a complementary multimodal data mining strategy is proposed to effectively mine the common features of multimodal data representing odor information and the individual features in olfactory EEG representing individual emotional information. Finally, the cross-subject olfactory preference recognition is achieved in 24 subjects by fusing the extracted common and individual features, and the recognition effect is superior to the state-of-the-art recognition methods. Furthermore, the advantages of the proposed method in cross-subject olfactory preference recognition indicate its potential for practical odor evaluation applications.
Modeling Orders of User Behaviors via Differentiable Sorting: A Multi-task Framework to Predicting User Post-click Conversion
Jul 18, 2023User post-click conversion prediction is of high interest to researchers and developers. Recent studies employ multi-task learning to tackle the selection bias and data sparsity problem, two severe challenges in post-click behavior prediction, by incorporating click data. However, prior works mainly focused on pointwise learning and the orders of labels (i.e., click and post-click) are not well explored, which naturally poses a listwise learning problem. Inspired by recent advances on differentiable sorting, in this paper, we propose a novel multi-task framework that leverages orders of user behaviors to predict user post-click conversion in an end-to-end approach. Specifically, we define an aggregation operator to combine predicted outputs of different tasks to a unified score, then we use the computed scores to model the label relations via differentiable sorting. Extensive experiments on public and industrial datasets show the superiority of our proposed model against competitive baselines.
Consolidator: Mergeable Adapter with Grouped Connections for Visual Adaptation
Apr 30, 2023



Recently, transformers have shown strong ability as visual feature extractors, surpassing traditional convolution-based models in various scenarios. However, the success of vision transformers largely owes to their capacity to accommodate numerous parameters. As a result, new challenges for adapting large models to downstream tasks arise. On the one hand, classic fine-tuning tunes all parameters in a huge model for every task and thus easily falls into overfitting, leading to inferior performance. On the other hand, on resource-limited devices, fine-tuning stores a full copy of parameters and thus is usually impracticable for the shortage of storage space. However, few works have focused on how to efficiently and effectively transfer knowledge in a vision transformer. Existing methods did not dive into the properties of visual features, leading to inferior performance. Moreover, some of them bring heavy inference cost though benefiting storage. To tackle these problems, we propose consolidator to modify the pre-trained model with the addition of a small set of tunable parameters to temporarily store the task-specific knowledge while freezing the backbone model. Motivated by the success of group-wise convolution, we adopt grouped connections across the features extracted by fully connected layers to construct tunable parts in a consolidator. To further enhance the model's capacity to transfer knowledge under a constrained storage budget and keep inference efficient, we consolidate the parameters in two stages: 1. between adaptation and storage, and 2. between loading and inference. On a series of downstream visual tasks, our consolidator can reach up to 7.56 better accuracy than full fine-tuning with merely 0.35% parameters, and outperform state-of-the-art parameter-efficient tuning methods by a clear margin. Code is available at https://github.com/beyondhtx/Consolidator.
Hi Sheldon! Creating Deep Personalized Characters from TV Shows
Apr 09, 2023



Imagine an interesting multimodal interactive scenario that you can see, hear, and chat with an AI-generated digital character, who is capable of behaving like Sheldon from The Big Bang Theory, as a DEEP copy from appearance to personality. Towards this fantastic multimodal chatting scenario, we propose a novel task, named Deep Personalized Character Creation (DPCC): creating multimodal chat personalized characters from multimodal data such as TV shows. Specifically, given a single- or multi-modality input (text, audio, video), the goal of DPCC is to generate a multi-modality (text, audio, video) response, which should be well-matched the personality of a specific character such as Sheldon, and of high quality as well. To support this novel task, we further collect a character centric multimodal dialogue dataset, named Deep Personalized Character Dataset (DPCD), from TV shows. DPCD contains character-specific multimodal dialogue data of ~10k utterances and ~6 hours of audio/video per character, which is around 10 times larger compared to existing related datasets.On DPCD, we present a baseline method for the DPCC task and create 5 Deep personalized digital Characters (DeepCharacters) from Big Bang TV Shows. We conduct both subjective and objective experiments to evaluate the multimodal response from DeepCharacters in terms of characterization and quality. The results demonstrates that, on our collected DPCD dataset, the proposed baseline can create personalized digital characters for generating multimodal response.Our collected DPCD dataset, the code of data collection and our baseline will be published soon.
Box-Level Active Detection
Mar 23, 2023Active learning selects informative samples for annotation within budget, which has proven efficient recently on object detection. However, the widely used active detection benchmarks conduct image-level evaluation, which is unrealistic in human workload estimation and biased towards crowded images. Furthermore, existing methods still perform image-level annotation, but equally scoring all targets within the same image incurs waste of budget and redundant labels. Having revealed above problems and limitations, we introduce a box-level active detection framework that controls a box-based budget per cycle, prioritizes informative targets and avoids redundancy for fair comparison and efficient application. Under the proposed box-level setting, we devise a novel pipeline, namely Complementary Pseudo Active Strategy (ComPAS). It exploits both human annotations and the model intelligence in a complementary fashion: an efficient input-end committee queries labels for informative objects only; meantime well-learned targets are identified by the model and compensated with pseudo-labels. ComPAS consistently outperforms 10 competitors under 4 settings in a unified codebase. With supervision from labeled data only, it achieves 100% supervised performance of VOC0712 with merely 19% box annotations. On the COCO dataset, it yields up to 4.3% mAP improvement over the second-best method. ComPAS also supports training with the unlabeled pool, where it surpasses 90% COCO supervised performance with 85% label reduction. Our source code is publicly available at https://github.com/lyumengyao/blad.
X-ReID: Cross-Instance Transformer for Identity-Level Person Re-Identification
Feb 04, 2023Currently, most existing person re-identification methods use Instance-Level features, which are extracted only from a single image. However, these Instance-Level features can easily ignore the discriminative information due to the appearance of each identity varies greatly in different images. Thus, it is necessary to exploit Identity-Level features, which can be shared across different images of each identity. In this paper, we propose to promote Instance-Level features to Identity-Level features by employing cross-attention to incorporate information from one image to another of the same identity, thus more unified and discriminative pedestrian information can be obtained. We propose a novel training framework named X-ReID. Specifically, a Cross Intra-Identity Instances module (IntraX) fuses different intra-identity instances to transfer Identity-Level knowledge and make Instance-Level features more compact. A Cross Inter-Identity Instances module (InterX) involves hard positive and hard negative instances to improve the attention response to the same identity instead of different identity, which minimizes intra-identity variation and maximizes inter-identity variation. Extensive experiments on benchmark datasets show the superiority of our method over existing works. Particularly, on the challenging MSMT17, our proposed method gains 1.1% mAP improvements when compared to the second place.
DarkVision: A Benchmark for Low-light Image/Video Perception
Jan 16, 2023



Imaging and perception in photon-limited scenarios is necessary for various applications, e.g., night surveillance or photography, high-speed photography, and autonomous driving. In these cases, cameras suffer from low signal-to-noise ratio, which degrades the image quality severely and poses challenges for downstream high-level vision tasks like object detection and recognition. Data-driven methods have achieved enormous success in both image restoration and high-level vision tasks. However, the lack of high-quality benchmark dataset with task-specific accurate annotations for photon-limited images/videos delays the research progress heavily. In this paper, we contribute the first multi-illuminance, multi-camera, and low-light dataset, named DarkVision, serving for both image enhancement and object detection. We provide bright and dark pairs with pixel-wise registration, in which the bright counterpart provides reliable reference for restoration and annotation. The dataset consists of bright-dark pairs of 900 static scenes with objects from 15 categories, and 32 dynamic scenes with 4-category objects. For each scene, images/videos were captured at 5 illuminance levels using three cameras of different grades, and average photons can be reliably estimated from the calibration data for quantitative studies. The static-scene images and dynamic videos respectively contain around 7,344 and 320,667 instances in total. With DarkVision, we established baselines for image/video enhancement and object detection by representative algorithms. To demonstrate an exemplary application of DarkVision, we propose two simple yet effective approaches for improving performance in video enhancement and object detection respectively. We believe DarkVision would advance the state-of-the-arts in both imaging and related computer vision tasks in low-light environment.
Ground Plane Matters: Picking Up Ground Plane Prior in Monocular 3D Object Detection
Nov 03, 2022The ground plane prior is a very informative geometry clue in monocular 3D object detection (M3OD). However, it has been neglected by most mainstream methods. In this paper, we identify two key factors that limit the applicability of ground plane prior: the projection point localization issue and the ground plane tilt issue. To pick up the ground plane prior for M3OD, we propose a Ground Plane Enhanced Network (GPENet) which resolves both issues at one go. For the projection point localization issue, instead of using the bottom vertices or bottom center of the 3D bounding box (BBox), we leverage the object's ground contact points, which are explicit pixels in the image and easy for the neural network to detect. For the ground plane tilt problem, our GPENet estimates the horizon line in the image and derives a novel mathematical expression to accurately estimate the ground plane equation. An unsupervised vertical edge mining algorithm is also proposed to address the occlusion of the horizon line. Furthermore, we design a novel 3D bounding box deduction method based on a dynamic back projection algorithm, which could take advantage of the accurate contact points and the ground plane equation. Additionally, using only M3OD labels, contact point and horizon line pseudo labels can be easily generated with NO extra data collection and label annotation cost. Extensive experiments on the popular KITTI benchmark show that our GPENet can outperform other methods and achieve state-of-the-art performance, well demonstrating the effectiveness and the superiority of the proposed approach. Moreover, our GPENet works better than other methods in cross-dataset evaluation on the nuScenes dataset. Our code and models will be published.
Automatic Landmark Detection and Registration of Brain Cortical Surfaces via Quasi-Conformal Geometry and Convolutional Neural Networks
Aug 15, 2022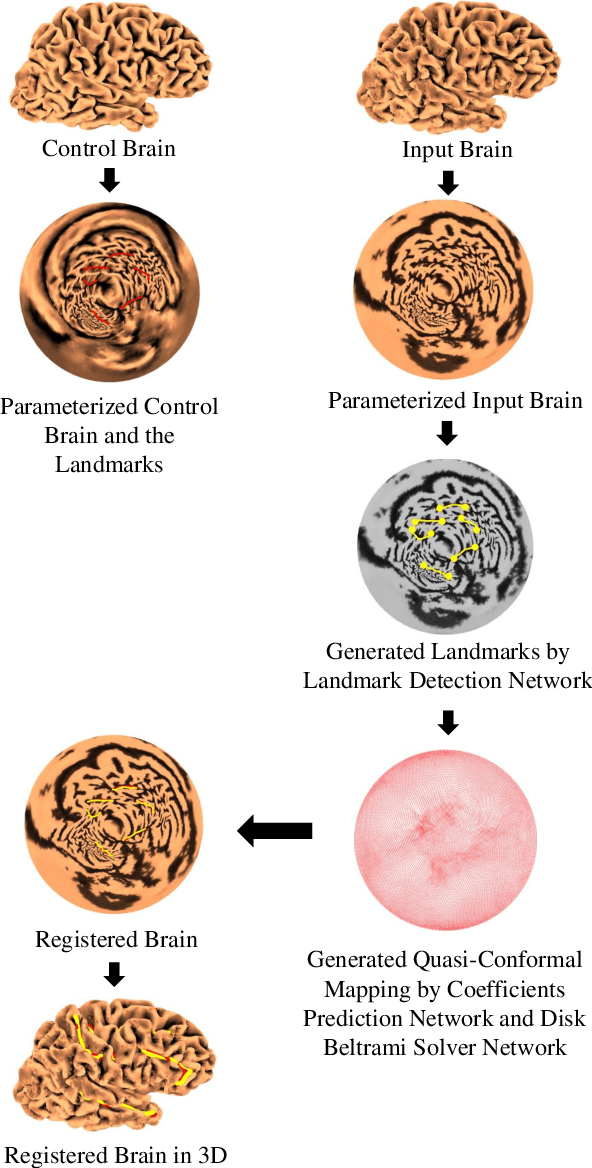

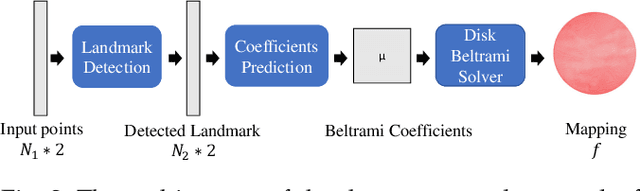

In medical imaging, surface registration is extensively used for performing systematic comparisons between anatomical structures, with a prime example being the highly convoluted brain cortical surfaces. To obtain a meaningful registration, a common approach is to identify prominent features on the surfaces and establish a low-distortion mapping between them with the feature correspondence encoded as landmark constraints. Prior registration works have primarily focused on using manually labeled landmarks and solving highly nonlinear optimization problems, which are time-consuming and hence hinder practical applications. In this work, we propose a novel framework for the automatic landmark detection and registration of brain cortical surfaces using quasi-conformal geometry and convolutional neural networks. We first develop a landmark detection network (LD-Net) that allows for the automatic extraction of landmark curves given two prescribed starting and ending points based on the surface geometry. We then utilize the detected landmarks and quasi-conformal theory for achieving the surface registration. Specifically, we develop a coefficient prediction network (CP-Net) for predicting the Beltrami coefficients associated with the desired landmark-based registration and a mapping network called the disk Beltrami solver network (DBS-Net) for generating quasi-conformal mappings from the predicted Beltrami coefficients, with the bijectivity guaranteed by quasi-conformal theory. Experimental results are presented to demonstrate the effectiveness of our proposed framework. Altogether, our work paves a new way for surface-based morphometry and medical shape analysis.