 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoAWG: Adverse Weather Generation with Adaptive Multi-Controls for Automotive Videos
Apr 21, 2026Perception robustness under adverse weather remains a critical challenge for autonomous driving, with the core bottleneck being the scarcity of real-world video data in adverse weather. Existing weather generation approaches struggle to balance visual quality and annotation reusability. We present AutoAWG, a controllable Adverse Weather video Generation framework for Autonomous driving. Our method employs a semantics-guided adaptive fusion of multiple controls to balance strong weather stylization with high-fidelity preservation of safety-critical targets; leverages a vanishing point-anchored temporal synthesis strategy to construct training sequences from static images, thereby reducing reliance on synthetic data; and adopts masked training to enhance long-horizon generation stability. On the nuScenes validation set, AutoAWG significantly outperforms prior state-of-the-art methods: without first-frame conditioning, FID and FVD are relatively reduced by 50.0% and 16.1%; with first-frame conditioning, they are further reduced by 8.7% and 7.2%, respectively. Extensive qualitative and quantitative results demonstrate advantages in style fidelity, temporal consistency, and semantic--structural integrity, underscoring the practical value of AutoAWG for improving downstream perception in autonomous driving. Our code is available at: https://github.com/higherhu/AutoAWG
Toward Reliable Sim-to-Real Predictability for MoE-based Robust Quadrupedal Locomotion
Jan 31, 2026Reinforcement learning has shown strong promise for quadrupedal agile locomotion, even with proprioception-only sensing. In practice, however, sim-to-real gap and reward overfitting in complex terrains can produce policies that fail to transfer, while physical validation remains risky and inefficient. To address these challenges, we introduce a unified framework encompassing a Mixture-of-Experts (MoE) locomotion policy for robust multi-terrain representation with RoboGauge, a predictive assessment suite that quantifies sim-to-real transferability. The MoE policy employs a gated set of specialist experts to decompose latent terrain and command modeling, achieving superior deployment robustness and generalization via proprioception alone. RoboGauge further provides multi-dimensional proprioception-based metrics via sim-to-sim tests over terrains, difficulty levels, and domain randomizations, enabling reliable MoE policy selection without extensive physical trials. Experiments on a Unitree Go2 demonstrate robust locomotion on unseen challenging terrains, including snow, sand, stairs, slopes, and 30 cm obstacles. In dedicated high-speed tests, the robot reaches 4 m/s and exhibits an emergent narrow-width gait associated with improved stability at high velocity.
Quantitative Analysis of Molecular Transport in the Extracellular Space Using Physics-Informed Neural Network
Jan 24, 2024



The brain extracellular space (ECS), an irregular, extremely tortuous nanoscale space located between cells or between cells and blood vessels, is crucial for nerve cell survival. It plays a pivotal role in high-level brain functions such as memory, emotion, and sensation. However, the specific form of molecular transport within the ECS remain elusive. To address this challenge, this paper proposes a novel approach to quantitatively analyze the molecular transport within the ECS by solving an inverse problem derived from the advection-diffusion equation (ADE) using a physics-informed neural network (PINN). PINN provides a streamlined solution to the ADE without the need for intricate mathematical formulations or grid settings. Additionally, the optimization of PINN facilitates the automatic computation of the diffusion coefficient governing long-term molecule transport and the velocity of molecules driven by advection. Consequently, the proposed method allows for the quantitative analysis and identification of the specific pattern of molecular transport within the ECS through the calculation of the Peclet number. Experimental validation on two datasets of magnetic resonance images (MRIs) captured at different time points showcases the effectiveness of the proposed method. Notably, our simulations reveal identical molecular transport patterns between datasets representing rats with tracer injected into the same brain region. These findings highlight the potential of PINN as a promising tool for comprehensively exploring molecular transport within the ECS.
UnifiedSSR: A Unified Framework of Sequential Search and Recommendation
Oct 21, 2023



In this work, we propose a Unified framework of Sequential Search and Recommendation (UnifiedSSR) for joint learning of user behavior history in both search and recommendation scenarios. Specifically, we consider user-interacted products in the recommendation scenario, user-interacted products and user-issued queries in the search scenario as three distinct types of user behaviors. We propose a dual-branch network to encode the pair of interacted product history and issued query history in the search scenario in parallel. This allows for cross-scenario modeling by deactivating the query branch for the recommendation scenario. Through the parameter sharing between dual branches, as well as between product branches in two scenarios, we incorporate cross-view and cross-scenario associations of user behaviors, providing a comprehensive understanding of user behavior patterns. To further enhance user behavior modeling by capturing the underlying dynamic intent, an Intent-oriented Session Modeling module is designed for inferring intent-oriented semantic sessions from the contextual information in behavior sequences. In particular, we consider self-supervised learning signals from two perspectives for intent-oriented semantic session locating, which encourage session discrimination within each behavior sequence and session alignment between dual behavior sequences. Extensive experiments on three public datasets demonstrate that UnifiedSSR consistently outperforms state-of-the-art methods for both search and recommendation.
DarkVision: A Benchmark for Low-light Image/Video Perception
Jan 16, 2023



Imaging and perception in photon-limited scenarios is necessary for various applications, e.g., night surveillance or photography, high-speed photography, and autonomous driving. In these cases, cameras suffer from low signal-to-noise ratio, which degrades the image quality severely and poses challenges for downstream high-level vision tasks like object detection and recognition. Data-driven methods have achieved enormous success in both image restoration and high-level vision tasks. However, the lack of high-quality benchmark dataset with task-specific accurate annotations for photon-limited images/videos delays the research progress heavily. In this paper, we contribute the first multi-illuminance, multi-camera, and low-light dataset, named DarkVision, serving for both image enhancement and object detection. We provide bright and dark pairs with pixel-wise registration, in which the bright counterpart provides reliable reference for restoration and annotation. The dataset consists of bright-dark pairs of 900 static scenes with objects from 15 categories, and 32 dynamic scenes with 4-category objects. For each scene, images/videos were captured at 5 illuminance levels using three cameras of different grades, and average photons can be reliably estimated from the calibration data for quantitative studies. The static-scene images and dynamic videos respectively contain around 7,344 and 320,667 instances in total. With DarkVision, we established baselines for image/video enhancement and object detection by representative algorithms. To demonstrate an exemplary application of DarkVision, we propose two simple yet effective approaches for improving performance in video enhancement and object detection respectively. We believe DarkVision would advance the state-of-the-arts in both imaging and related computer vision tasks in low-light environment.
Hierarchical Transformer with Spatio-Temporal Context Aggregation for Next Point-of-Interest Recommendation
Sep 04, 2022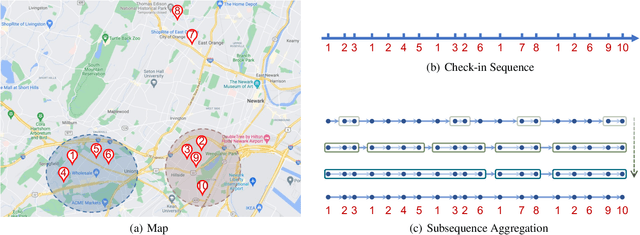

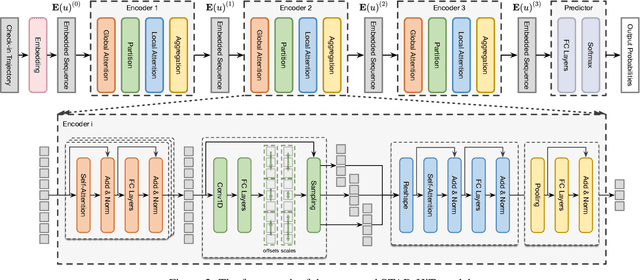
Next point-of-interest (POI) recommendation is a critical task in location-based social networks, yet remains challenging due to a high degree of variation and personalization exhibited in user movements. In this work, we explore the latent hierarchical structure composed of multi-granularity short-term structural patterns in user check-in sequences. We propose a Spatio-Temporal context AggRegated Hierarchical Transformer (STAR-HiT) for next POI recommendation, which employs stacked hierarchical encoders to recursively encode the spatio-temporal context and explicitly locate subsequences of different granularities. More specifically, in each encoder, the global attention layer captures the spatio-temporal context of the sequence, while the local attention layer performed within each subsequence enhances subsequence modeling using the local context. The sequence partition layer infers positions and lengths of subsequences from the global context adaptively, such that semantics in subsequences can be well preserved. Finally, the subsequence aggregation layer fuses representations within each subsequence to form the corresponding subsequence representation, thereby generating a new sequence of higher-level granularity. The stacking of encoders captures the latent hierarchical structure of the check-in sequence, which is used to predict the next visiting POI. Extensive experiments on three public datasets demonstrate that the proposed model achieves superior performance whilst providing explanations for recommendations. Codes are available at https://github.com/JennyXieJiayi/STAR-HiT.
Deep Causal Reasoning for Recommendations
Jan 06, 2022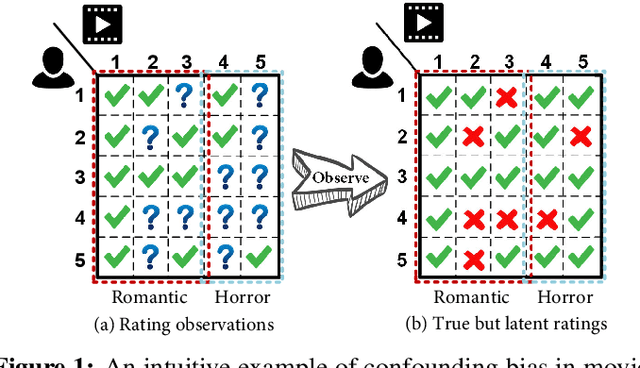
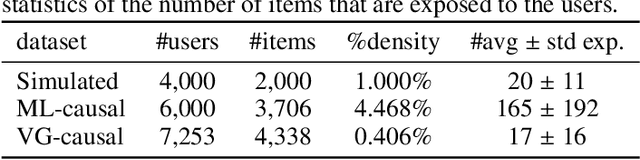
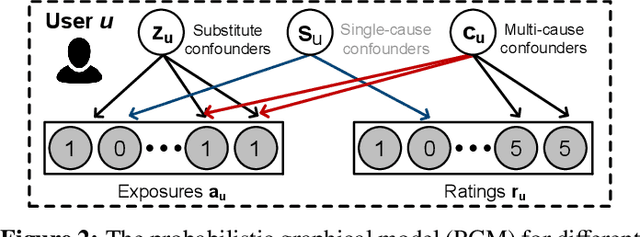
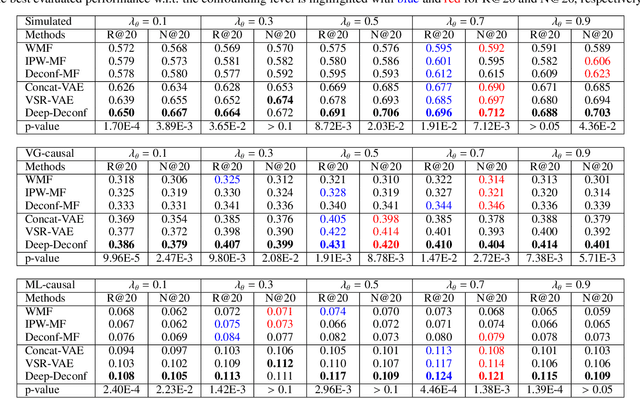
Traditional recommender systems aim to estimate a user's rating to an item based on observed ratings from the population. As with all observational studies, hidden confounders, which are factors that affect both item exposures and user ratings, lead to a systematic bias in the estimation. Consequently, a new trend in recommender system research is to negate the influence of confounders from a causal perspective. Observing that confounders in recommendations are usually shared among items and are therefore multi-cause confounders, we model the recommendation as a multi-cause multi-outcome (MCMO) inference problem. Specifically, to remedy confounding bias, we estimate user-specific latent variables that render the item exposures independent Bernoulli trials. The generative distribution is parameterized by a DNN with factorized logistic likelihood and the intractable posteriors are estimated by variational inference. Controlling these factors as substitute confounders, under mild assumptions, can eliminate the bias incurred by multi-cause confounders. Furthermore, we show that MCMO modeling may lead to high variance due to scarce observations associated with the high-dimensional causal space. Fortunately, we theoretically demonstrate that introducing user features as pre-treatment variables can substantially improve sample efficiency and alleviate overfitting. Empirical studies on simulated and real-world datasets show that the proposed deep causal recommender shows more robustness to unobserved confounders than state-of-the-art causal recommenders. Codes and datasets are released at https://github.com/yaochenzhu/deep-deconf.
Cross-modal Variational Auto-encoder for Content-based Micro-video Background Music Recommendation
Jul 15, 2021
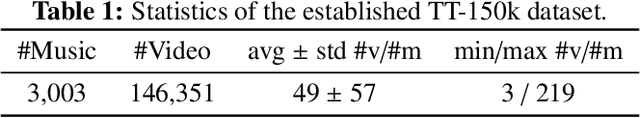

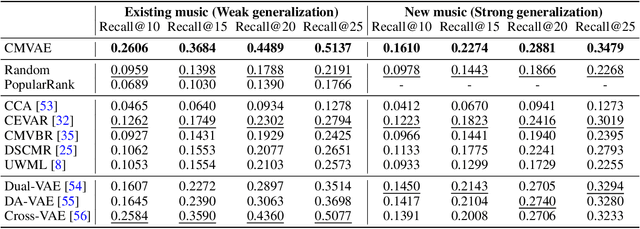
In this paper, we propose a cross-modal variational auto-encoder (CMVAE) for content-based micro-video background music recommendation. CMVAE is a hierarchical Bayesian generative model that matches relevant background music to a micro-video by projecting these two multimodal inputs into a shared low-dimensional latent space, where the alignment of two corresponding embeddings of a matched video-music pair is achieved by cross-generation. Moreover, the multimodal information is fused by the product-of-experts (PoE) principle, where the semantic information in visual and textual modalities of the micro-video are weighted according to their variance estimations such that the modality with a lower noise level is given more weights. Therefore, the micro-video latent variables contain less irrelevant information that results in a more robust model generalization. Furthermore, we establish a large-scale content-based micro-video background music recommendation dataset, TT-150k, composed of approximately 3,000 different background music clips associated to 150,000 micro-videos from different users. Extensive experiments on the established TT-150k dataset demonstrate the effectiveness of the proposed method. A qualitative assessment of CMVAE by visualizing some recommendation results is also included.
Techniques Toward Optimizing Viewability in RTB Ad Campaigns Using Reinforcement Learning
May 21, 2021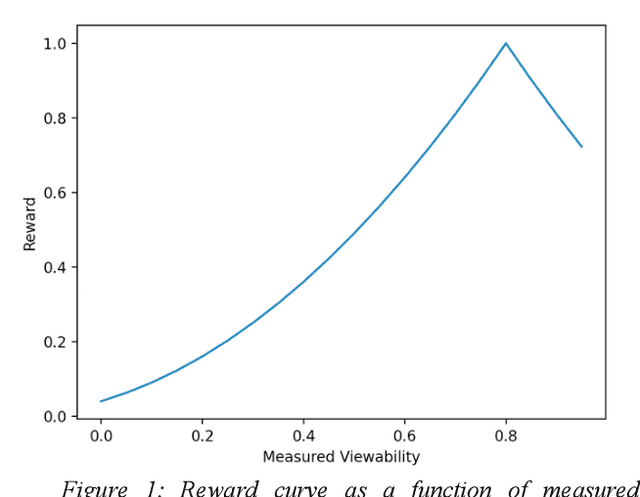
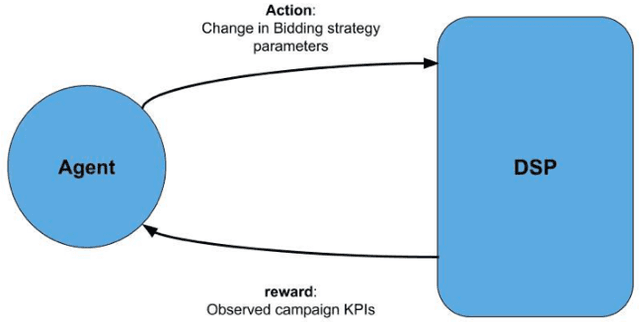
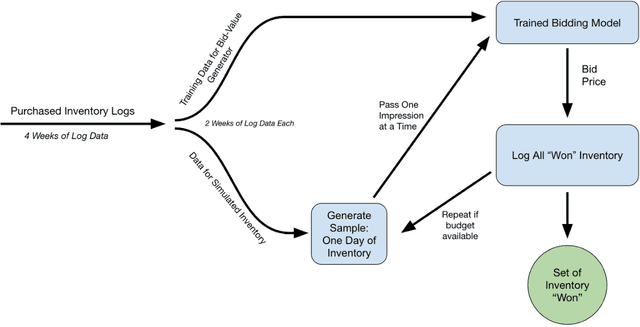
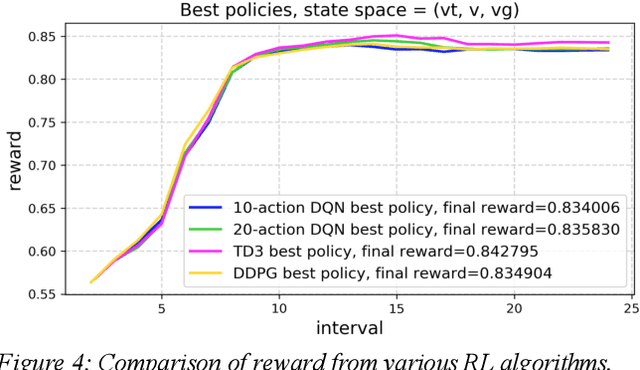
Reinforcement learning (RL) is an effective technique for training decision-making agents through interactions with their environment. The advent of deep learning has been associated with highly notable successes with sequential decision making problems - such as defeating some of the highest-ranked human players at Go. In digital advertising, real-time bidding (RTB) is a common method of allocating advertising inventory through real-time auctions. Bidding strategies need to incorporate logic for dynamically adjusting parameters in order to deliver pre-assigned campaign goals. Here we discuss techniques toward using RL to train bidding agents. As a campaign metric we particularly focused on viewability: the percentage of inventory which goes on to be viewed by an end user. This paper is presented as a survey of techniques and experiments which we developed through the course of this research. We discuss expanding our training data to include edge cases by training on simulated interactions. We discuss the experimental results comparing the performance of several promising RL algorithms, and an approach to hyperparameter optimization of an actor/critic training pipeline through Bayesian optimization. Finally, we present live-traffic tests of some of our RL agents against a rule-based feedback-control approach, demonstrating the potential for this method as well as areas for further improvement. This paper therefore presents an arrangement of our findings in this quickly developing field, and ways that it can be applied to an RTB use case.
Online and Scalable Model Selection with Multi-Armed Bandits
Jan 25, 2021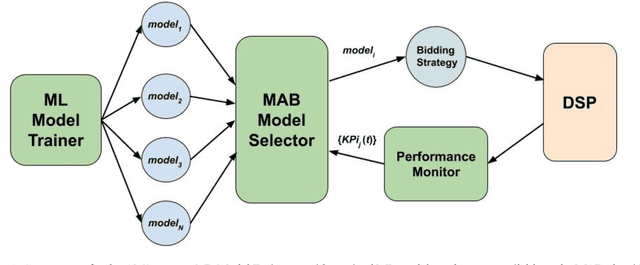
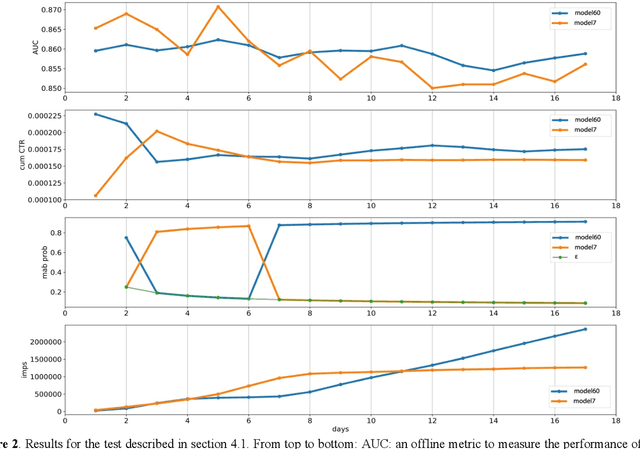
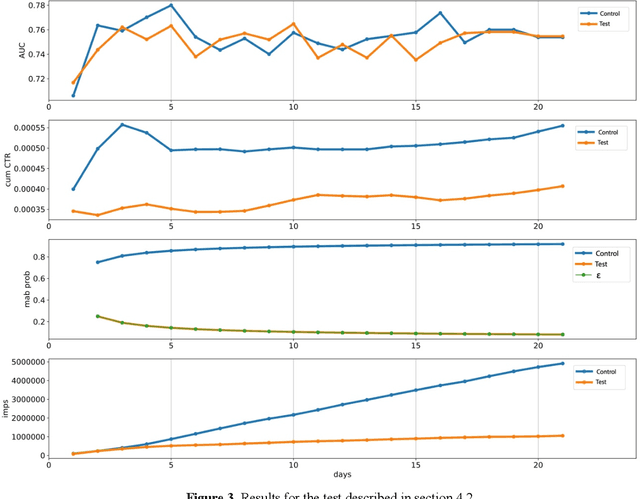
Many online applications running on live traffic are powered by machine learning models, for which training, validation, and hyper-parameter tuning are conducted on historical data. However, it is common for models demonstrating strong performance in offline analysis to yield poorer performance when deployed online. This problem is a consequence of the difficulty of training on historical data in non-stationary environments. Moreover, the machine learning metrics used for model selection may not sufficiently correlate with real-world business metrics used to determine the success of the applications being tested. These problems are particularly prominent in the Real-Time Bidding (RTB) domain, in which ML models power bidding strategies, and a change in models will likely affect performance of the advertising campaigns. In this work, we present Automatic Model Selector (AMS), a system for scalable online selection of RTB bidding strategies based on real-world performance metrics. AMS employs Multi-Armed Bandits (MAB) to near-simultaneously run and evaluate multiple models against live traffic, allocating the most traffic to the best-performing models while decreasing traffic to those with poorer online performance, thereby minimizing the impact of inferior models on overall campaign performance. The reliance on offline data is avoided, instead making model selections on a case-by-case basis according to actionable business goals. AMS allows new models to be safely introduced into live campaigns as soon as they are developed, minimizing the risk to overall performance. In live-traffic tests on multiple ad campaigns, the AMS system proved highly effective at improving ad campaign performance.