 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAU-R1: Visual Language Model for Traffic Anomaly Understanding
Mar 19, 2026Traffic Anomaly Understanding (TAU) is important for traffic safety in Intelligent Transportation Systems. Recent vision-language models (VLMs) have shown strong capabilities in video understanding. However, progress on TAU remains limited due to the lack of benchmarks and task-specific methodologies. To address this limitation, we introduce Roundabout-TAU, a dataset constructed from real-world roundabout videos collected in collaboration with the City of Carmel, Indiana. The dataset contains 342 clips and is annotated with more than 2,000 question-answer pairs covering multiple aspects of traffic anomaly understanding. Building on this benchmark, we propose TAU-R1, a two-layer vision-language framework for TAU. The first layer is a lightweight anomaly classifier that performs coarse anomaly categorisation, while the second layer is a larger anomaly reasoner that generates detailed event summaries. To improve task-specific reasoning, we introduce a two-stage training strategy consisting of decomposed-QA-enhanced supervised fine-tuning followed by TAU-GRPO, a GRPO-based post-training method with TAU-specific reward functions. Experimental results show that TAU-R1 achieves strong performance on both anomaly classification and reasoning tasks while maintaining deployment efficiency. The dataset and code are available at: https://github.com/siri-rouser/TAU-R1
KAN or MLP? Point Cloud Shows the Way Forward
Apr 18, 2025Multi-Layer Perceptrons (MLPs) have become one of the fundamental architectural component in point cloud analysis due to its effective feature learning mechanism. However, when processing complex geometric structures in point clouds, MLPs' fixed activation functions struggle to efficiently capture local geometric features, while suffering from poor parameter efficiency and high model redundancy. In this paper, we propose PointKAN, which applies Kolmogorov-Arnold Networks (KANs) to point cloud analysis tasks to investigate their efficacy in hierarchical feature representation. First, we introduce a Geometric Affine Module (GAM) to transform local features, improving the model's robustness to geometric variations. Next, in the Local Feature Processing (LFP), a parallel structure extracts both group-level features and global context, providing a rich representation of both fine details and overall structure. Finally, these features are combined and processed in the Global Feature Processing (GFP). By repeating these operations, the receptive field gradually expands, enabling the model to capture complete geometric information of the point cloud. To overcome the high parameter counts and computational inefficiency of standard KANs, we develop Efficient-KANs in the PointKAN-elite variant, which significantly reduces parameters while maintaining accuracy. Experimental results demonstrate that PointKAN outperforms PointMLP on benchmark datasets such as ModelNet40, ScanObjectNN, and ShapeNetPart, with particularly strong performance in Few-shot Learning task. Additionally, PointKAN achieves substantial reductions in parameter counts and computational complexity (FLOPs). This work highlights the potential of KANs-based architectures in 3D vision and opens new avenues for research in point cloud understanding.
Robust TOA-based Localization with Inaccurate Anchors for MANET
Dec 29, 2023Accurate node localization is vital for mobile ad hoc networks (MANETs). Current methods like Time of Arrival (TOA) can estimate node positions using imprecise baseplates and achieve the Cram\'er-Rao lower bound (CRLB) accuracy. In multi-hop MANETs, some nodes lack direct links to base anchors, depending on neighbor nodes as dynamic anchors for chain localization. However, the dynamic nature of MANETs challenges TOA's robustness due to the availability and accuracy of base anchors, coupled with ranging errors. To address the issue of cascading positioning error divergence, we first derive the CRLB for any primary node in MANETs as a metric to tackle localization error in cascading scenarios. Second, we propose an advanced two-step TOA method based on CRLB which is able to approximate target node's CRLB with only local neighbor information. Finally, simulation results confirm the robustness of our algorithm, achieving CRLB-level accuracy for small ranging errors and maintaining precision for larger errors compared to existing TOA methods.
Implementing Digital Twin in Field-Deployed Optical Networks: Uncertain Factors, Operational Guidance, and Field-Trial Demonstration
Dec 06, 2023Digital twin has revolutionized optical communication networks by enabling their full life-cycle management, including design, troubleshooting, optimization, upgrade, and prediction. While extensive literature exists on frameworks, standards, and applications of digital twin, there is a pressing need in implementing digital twin in field-deployed optical networks operating in real-world environments, as opposed to controlled laboratory settings. This paper addresses this challenge by examining the uncertain factors behind the inaccuracy of digital twin in field-deployed optical networks from three main challenges and proposing operational guidance for implementing accurate digital twin in field-deployed optical networks. Through the proposed guidance, we demonstrate the effective implementation of digital twin in a field-trial C+L-band optical transmission link, showcasing its capabilities in performance recovery in a fiber cut scenario.
Human-Machine Cooperative Multimodal Learning Method for Cross-subject Olfactory Preference Recognition
Nov 24, 2023Odor sensory evaluation has a broad application in food, clothing, cosmetics, and other fields. Traditional artificial sensory evaluation has poor repeatability, and the machine olfaction represented by the electronic nose (E-nose) is difficult to reflect human feelings. Olfactory electroencephalogram (EEG) contains odor and individual features associated with human olfactory preference, which has unique advantages in odor sensory evaluation. However, the difficulty of cross-subject olfactory EEG recognition greatly limits its application. It is worth noting that E-nose and olfactory EEG are more advantageous in representing odor information and individual emotions, respectively. In this paper, an E-nose and olfactory EEG multimodal learning method is proposed for cross-subject olfactory preference recognition. Firstly, the olfactory EEG and E-nose multimodal data acquisition and preprocessing paradigms are established. Secondly, a complementary multimodal data mining strategy is proposed to effectively mine the common features of multimodal data representing odor information and the individual features in olfactory EEG representing individual emotional information. Finally, the cross-subject olfactory preference recognition is achieved in 24 subjects by fusing the extracted common and individual features, and the recognition effect is superior to the state-of-the-art recognition methods. Furthermore, the advantages of the proposed method in cross-subject olfactory preference recognition indicate its potential for practical odor evaluation applications.
Decoding Taste Information in Human Brain: A Temporal and Spatial Reconstruction Data Augmentation Method Coupled with Taste EEG
Jul 01, 2023For humans, taste is essential for perceiving food's nutrient content or harmful components. The current sensory evaluation of taste mainly relies on artificial sensory evaluation and electronic tongue, but the former has strong subjectivity and poor repeatability, and the latter is not flexible enough. This work proposed a strategy for acquiring and recognizing taste electroencephalogram (EEG), aiming to decode people's objective perception of taste through taste EEG. Firstly, according to the proposed experimental paradigm, the taste EEG of subjects under different taste stimulation was collected. Secondly, to avoid insufficient training of the model due to the small number of taste EEG samples, a Temporal and Spatial Reconstruction Data Augmentation (TSRDA) method was proposed, which effectively augmented the taste EEG by reconstructing the taste EEG's important features in temporal and spatial dimensions. Thirdly, a multi-view channel attention module was introduced into a designed convolutional neural network to extract the important features of the augmented taste EEG. The proposed method has accuracy of 99.56%, F1-score of 99.48%, and kappa of 99.38%, proving the method's ability to distinguish the taste EEG evoked by different taste stimuli successfully. In summary, combining TSRDA with taste EEG technology provides an objective and effective method for sensory evaluation of food taste.
Detect Depression from Social Networks with Sentiment Knowledge Sharing
Jun 13, 2023



Social network plays an important role in propagating people's viewpoints, emotions, thoughts, and fears. Notably, following lockdown periods during the COVID-19 pandemic, the issue of depression has garnered increasing attention, with a significant portion of individuals resorting to social networks as an outlet for expressing emotions. Using deep learning techniques to discern potential signs of depression from social network messages facilitates the early identification of mental health conditions. Current efforts in detecting depression through social networks typically rely solely on analyzing the textual content, overlooking other potential information. In this work, we conduct a thorough investigation that unveils a strong correlation between depression and negative emotional states. The integration of such associations as external knowledge can provide valuable insights for detecting depression. Accordingly, we propose a multi-task training framework, DeSK, which utilizes shared sentiment knowledge to enhance the efficacy of depression detection. Experiments conducted on both Chinese and English datasets demonstrate the cross-lingual effectiveness of DeSK.
Color Segmentation on FPGA Using Minimum Distance Classifier for Automatic Road Sign Detection
Dec 12, 2022Classification is an important step in machine vision systems; it reveals the true identity of an object using features extracted in pre-processing steps. Practical usage requires the operation to be fast, energy efficient and easy to implement. In this paper, we present a design of the Minimum Distance Classifier based on an FPGA platform. It is optimized by the pipelined structure to strike a balance between device utilization and computational speed. In addition, the dimension of the feature space is modeled as a generic parameter, making it possible for the design to re-generate hardware to cope with feature space with arbitrary dimensions. Its primary application is demonstrated in color segmentation on FPGA in the form of efficient classification using color as a feature. This result is further extended by introducing a multi-class component labeling module to label the segmented color components and measure their geometric properties. The combination of these two modules can effectively detect road signs as the region of interests.
* Updated version
ClusterGNN: Cluster-based Coarse-to-Fine Graph Neural Network for Efficient Feature Matching
Apr 25, 2022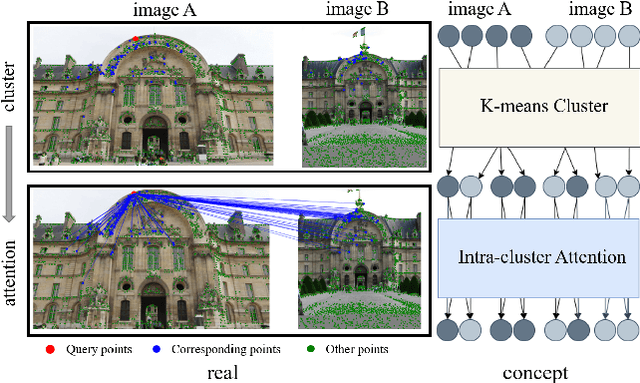
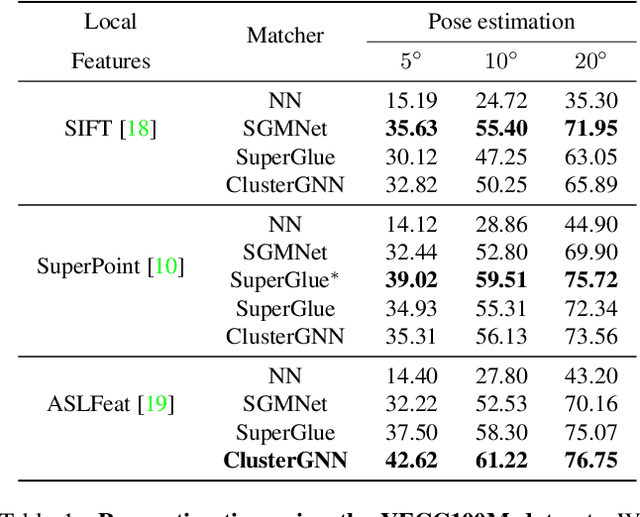
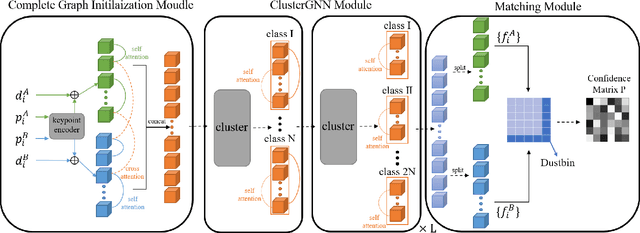
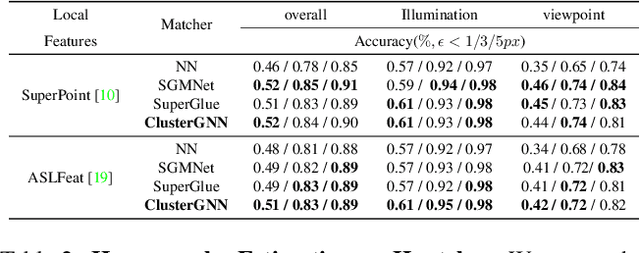
Graph Neural Networks (GNNs) with attention have been successfully applied for learning visual feature matching. However, current methods learn with complete graphs, resulting in a quadratic complexity in the number of features. Motivated by a prior observation that self- and cross- attention matrices converge to a sparse representation, we propose ClusterGNN, an attentional GNN architecture which operates on clusters for learning the feature matching task. Using a progressive clustering module we adaptively divide keypoints into different subgraphs to reduce redundant connectivity, and employ a coarse-to-fine paradigm for mitigating miss-classification within images. Our approach yields a 59.7% reduction in runtime and 58.4% reduction in memory consumption for dense detection, compared to current state-of-the-art GNN-based matching, while achieving a competitive performance on various computer vision tasks.
DoubleStar: Long-Range Attack Towards Depth Estimation based Obstacle Avoidance in Autonomous Systems
Oct 07, 2021
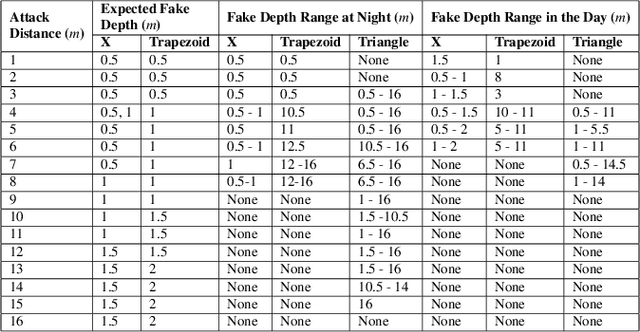
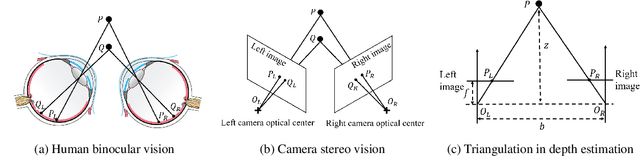
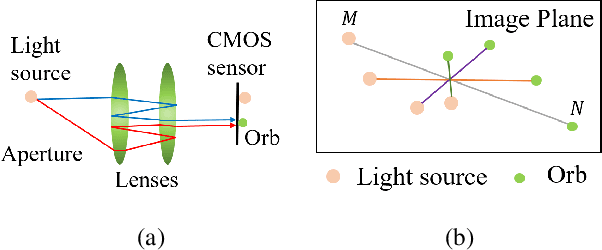
Depth estimation-based obstacle avoidance has been widely adopted by autonomous systems (drones and vehicles) for safety purpose. It normally relies on a stereo camera to automatically detect obstacles and make flying/driving decisions, e.g., stopping several meters ahead of the obstacle in the path or moving away from the detected obstacle. In this paper, we explore new security risks associated with the stereo vision-based depth estimation algorithms used for obstacle avoidance. By exploiting the weaknesses of the stereo matching in depth estimation algorithms and the lens flare effect in optical imaging, we propose DoubleStar, a long-range attack that injects fake obstacle depth by projecting pure light from two complementary light sources. DoubleStar includes two distinctive attack formats: beams attack and orbs attack, which leverage projected light beams and lens flare orbs respectively to cause false depth perception. We successfully attack two commercial stereo cameras designed for autonomous systems (ZED and Intel RealSense). The visualization of fake depth perceived by the stereo cameras illustrates the false stereo matching induced by DoubleStar. We further use Ardupilot to simulate the attack and demonstrate its impact on drones. To validate the attack on real systems, we perform a real-world attack towards a commercial drone equipped with state-of-the-art obstacle avoidance algorithms. Our attack can continuously bring a flying drone to a sudden stop or drift it away across a long distance under various lighting conditions, even bypassing sensor fusion mechanisms. Specifically, our experimental results show that DoubleStar creates fake depth up to 15 meters in distance at night and up to 8 meters during the daytime. To mitigate this newly discovered threat, we provide discussions on potential countermeasures to defend against DoubleStar.