 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Tree-Structured Decoder Training for Code Generation via Mutual Learning
May 31, 2021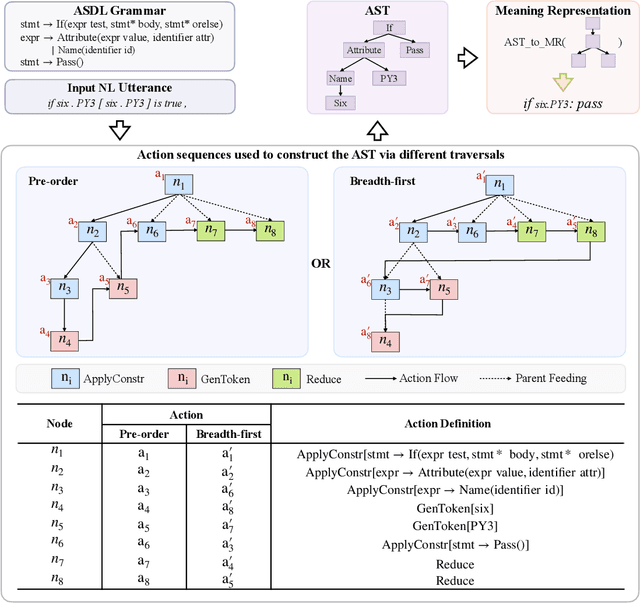
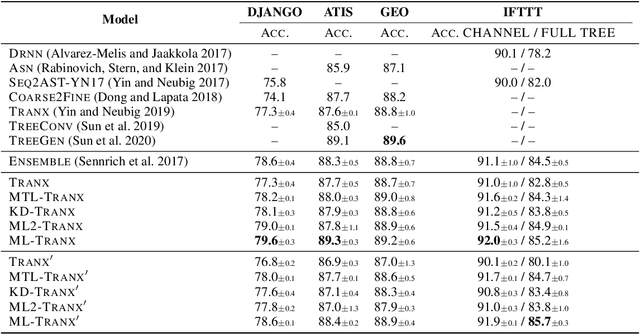
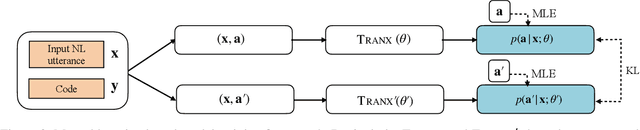
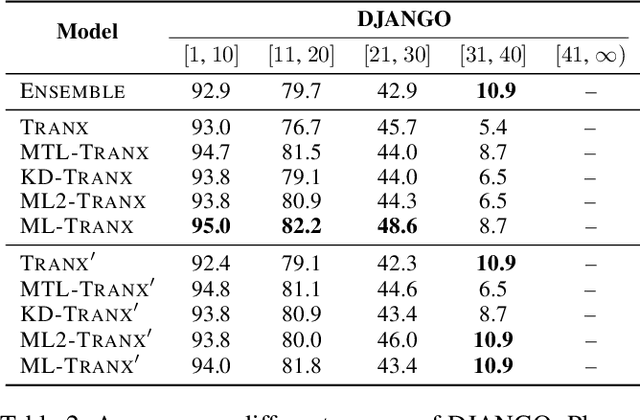
Code generation aims to automatically generate a piece of code given an input natural language utterance. Currently, among dominant models, it is treated as a sequence-to-tree task, where a decoder outputs a sequence of actions corresponding to the pre-order traversal of an Abstract Syntax Tree. However, such a decoder only exploits the preorder traversal based preceding actions, which are insufficient to ensure correct action predictions. In this paper, we first throughly analyze the context modeling difference between neural code generation models with different traversals based decodings (preorder traversal vs breadth-first traversal), and then propose to introduce a mutual learning framework to jointly train these models. Under this framework, we continuously enhance both two models via mutual distillation, which involves synchronous executions of two one-to-one knowledge transfers at each training step. More specifically, we alternately choose one model as the student and the other as its teacher, and require the student to fit the training data and the action prediction distributions of its teacher. By doing so, both models can fully absorb the knowledge from each other and thus could be improved simultaneously. Experimental results and in-depth analysis on several benchmark datasets demonstrate the effectiveness of our approach. We release our code at https://github.com/DeepLearnXMU/CGML.
Embedding Semantic Hierarchy in Discrete Optimal Transport for Risk Minimization
Apr 30, 2021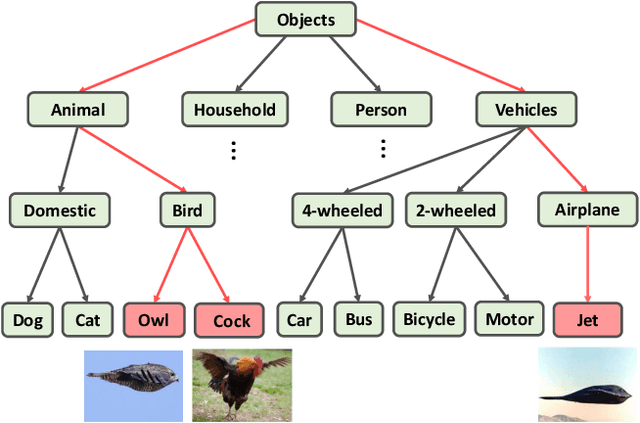
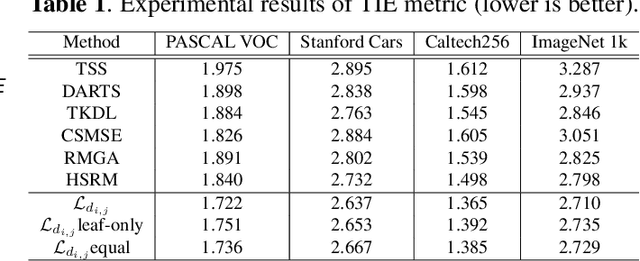
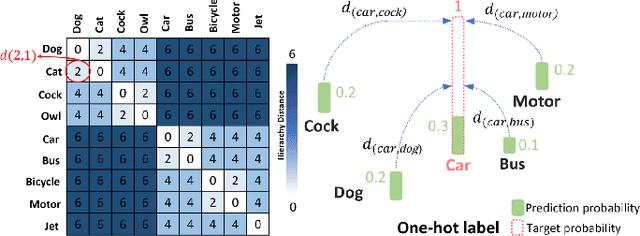
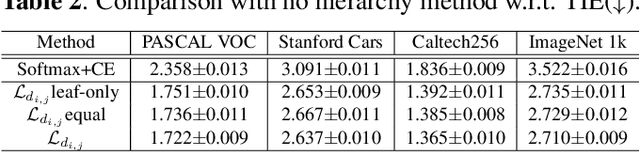
The widely-used cross-entropy (CE) loss-based deep networks achieved significant progress w.r.t. the classification accuracy. However, the CE loss can essentially ignore the risk of misclassification which is usually measured by the distance between the prediction and label in a semantic hierarchical tree. In this paper, we propose to incorporate the risk-aware inter-class correlation in a discrete optimal transport (DOT) training framework by configuring its ground distance matrix. The ground distance matrix can be pre-defined following a priori of hierarchical semantic risk. Specifically, we define the tree induced error (TIE) on a hierarchical semantic tree and extend it to its increasing function from the optimization perspective. The semantic similarity in each level of a tree is integrated with the information gain. We achieve promising results on several large scale image classification tasks with a semantic tree structure in a plug and play manner.
Enhanced Aspect-Based Sentiment Analysis Models with Progressive Self-supervised Attention Learning
Mar 05, 2021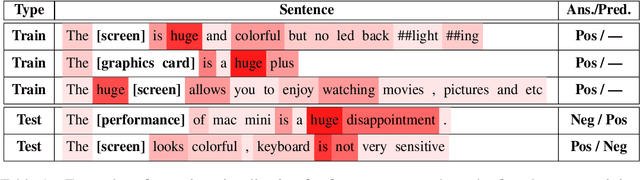
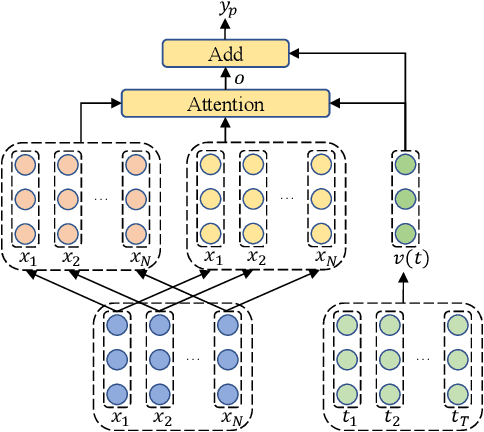
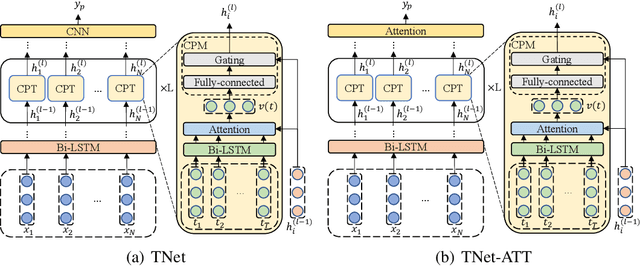

In aspect-based sentiment analysis (ABSA), many neural models are equipped with an attention mechanism to quantify the contribution of each context word to sentiment prediction. However, such a mechanism suffers from one drawback: only a few frequent words with sentiment polarities are tended to be taken into consideration for final sentiment decision while abundant infrequent sentiment words are ignored by models. To deal with this issue, we propose a progressive self-supervised attention learning approach for attentional ABSA models. In this approach, we iteratively perform sentiment prediction on all training instances, and continually learn useful attention supervision information in the meantime. During training, at each iteration, context words with the highest impact on sentiment prediction, identified based on their attention weights or gradients, are extracted as words with active/misleading influence on the correct/incorrect prediction for each instance. Words extracted in this way are masked for subsequent iterations. To exploit these extracted words for refining ABSA models, we augment the conventional training objective with a regularization term that encourages ABSA models to not only take full advantage of the extracted active context words but also decrease the weights of those misleading words. We integrate the proposed approach into three state-of-the-art neural ABSA models. Experiment results and in-depth analyses show that our approach yields better attention results and significantly enhances the performance of all three models. We release the source code and trained models at https://github.com/DeepLearnXMU/PSSAttention.
* 31 pages. arXiv admin note: text overlap with arXiv:1906.01213
Structural Information Preserving for Graph-to-Text Generation
Feb 12, 2021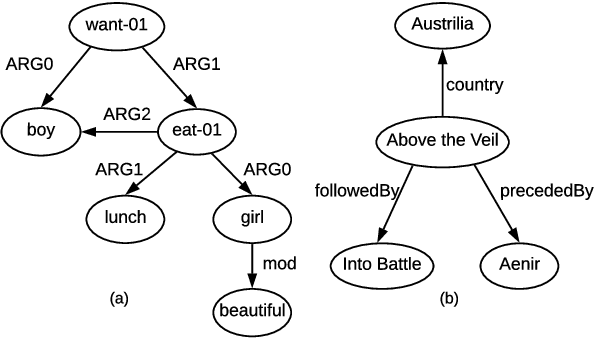
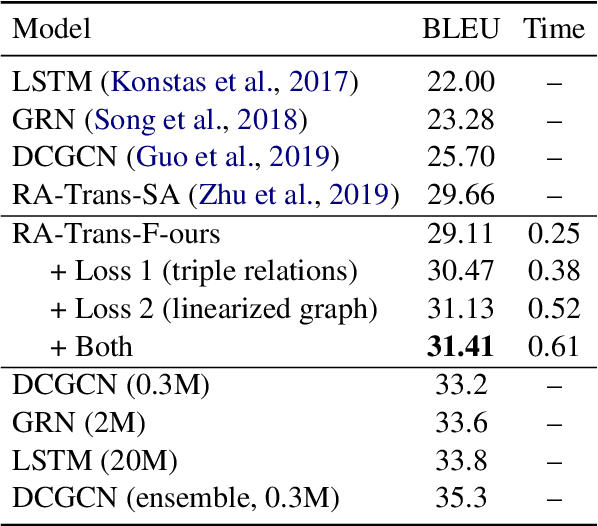
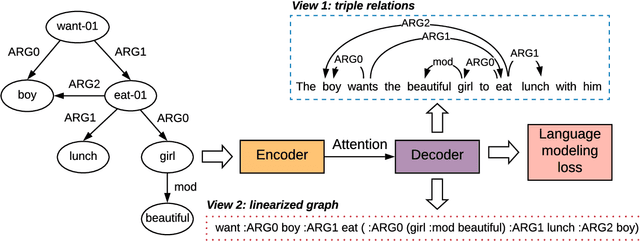

The task of graph-to-text generation aims at producing sentences that preserve the meaning of input graphs. As a crucial defect, the current state-of-the-art models may mess up or even drop the core structural information of input graphs when generating outputs. We propose to tackle this problem by leveraging richer training signals that can guide our model for preserving input information. In particular, we introduce two types of autoencoding losses, each individually focusing on different aspects (a.k.a. views) of input graphs. The losses are then back-propagated to better calibrate our model via multi-task training. Experiments on two benchmarks for graph-to-text generation show the effectiveness of our approach over a state-of-the-art baseline. Our code is available at \url{http://github.com/Soistesimmer/AMR-multiview}.
Dynamic Context-guided Capsule Network for Multimodal Machine Translation
Sep 04, 2020
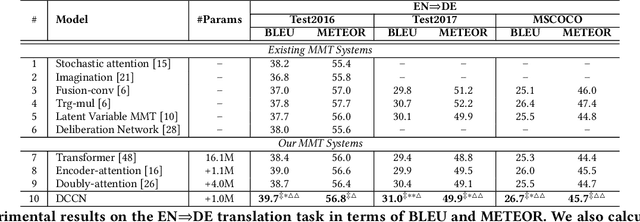
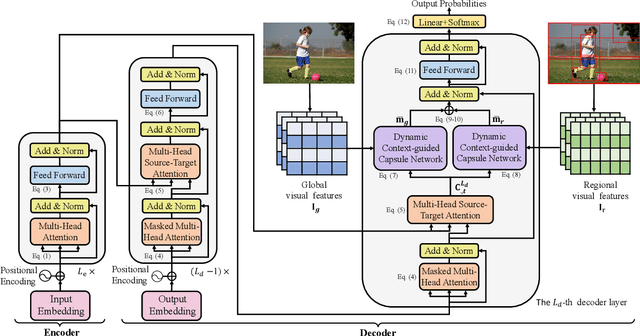
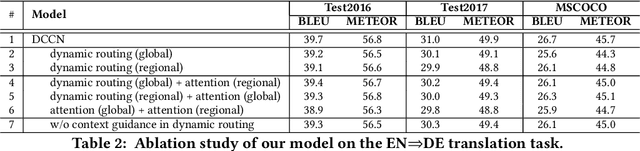
Multimodal machine translation (MMT), which mainly focuses on enhancing text-only translation with visual features, has attracted considerable attention from both computer vision and natural language processing communities. Most current MMT models resort to attention mechanism, global context modeling or multimodal joint representation learning to utilize visual features. However, the attention mechanism lacks sufficient semantic interactions between modalities while the other two provide fixed visual context, which is unsuitable for modeling the observed variability when generating translation. To address the above issues, in this paper, we propose a novel Dynamic Context-guided Capsule Network (DCCN) for MMT. Specifically, at each timestep of decoding, we first employ the conventional source-target attention to produce a timestep-specific source-side context vector. Next, DCCN takes this vector as input and uses it to guide the iterative extraction of related visual features via a context-guided dynamic routing mechanism. Particularly, we represent the input image with global and regional visual features, we introduce two parallel DCCNs to model multimodal context vectors with visual features at different granularities. Finally, we obtain two multimodal context vectors, which are fused and incorporated into the decoder for the prediction of the target word. Experimental results on the Multi30K dataset of English-to-German and English-to-French translation demonstrate the superiority of DCCN. Our code is available on https://github.com/DeepLearnXMU/MM-DCCN.
Iterative Dual Domain Adaptation for Neural Machine Translation
Dec 16, 2019
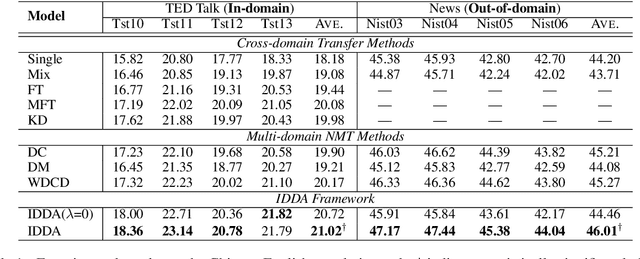
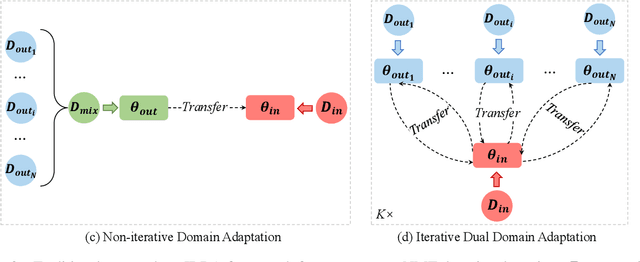
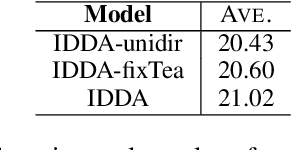
Previous studies on the domain adaptation for neural machine translation (NMT) mainly focus on the one-pass transferring out-of-domain translation knowledge to in-domain NMT model. In this paper, we argue that such a strategy fails to fully extract the domain-shared translation knowledge, and repeatedly utilizing corpora of different domains can lead to better distillation of domain-shared translation knowledge. To this end, we propose an iterative dual domain adaptation framework for NMT. Specifically, we first pre-train in-domain and out-of-domain NMT models using their own training corpora respectively, and then iteratively perform bidirectional translation knowledge transfer (from in-domain to out-of-domain and then vice versa) based on knowledge distillation until the in-domain NMT model convergences. Furthermore, we extend the proposed framework to the scenario of multiple out-of-domain training corpora, where the above-mentioned transfer is performed sequentially between the in-domain and each out-of-domain NMT models in the ascending order of their domain similarities. Empirical results on Chinese-English and English-German translation tasks demonstrate the effectiveness of our framework.
Deep Verifier Networks: Verification of Deep Discriminative Models with Deep Generative Models
Nov 18, 2019
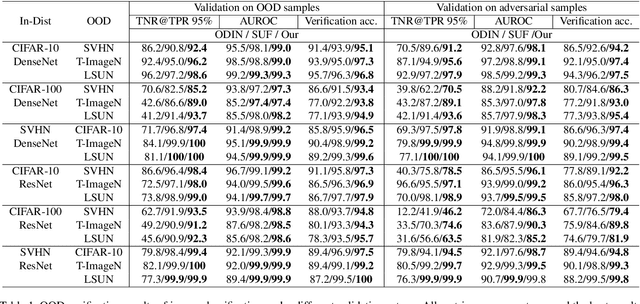
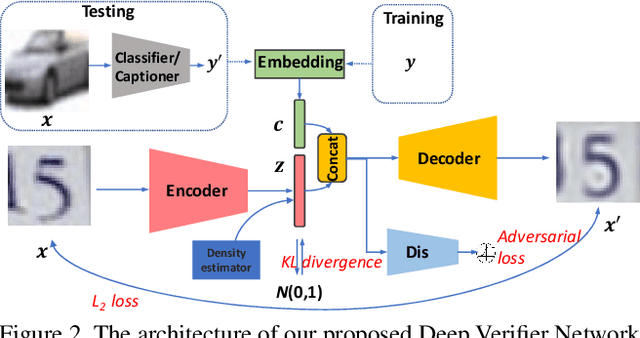

AI Safety is a major concern in many deep learning applications such as autonomous driving. Given a trained deep learning model, an important natural problem is how to reliably verify the model's prediction. In this paper, we propose a novel framework --- deep verifier networks (DVN) to verify the inputs and outputs of deep discriminative models with deep generative models. Our proposed model is based on conditional variational auto-encoders with disentanglement constraints. We give both intuitive and theoretical justifications of the model. Our verifier network is trained independently with the prediction model, which eliminates the need of retraining the verifier network for a new model. We test the verifier network on out-of-distribution detection and adversarial example detection problems, as well as anomaly detection problems in structured prediction tasks such as image caption generation. We achieve state-of-the-art results in all of these problems.
Neural Collective Entity Linking Based on Recurrent Random Walk Network Learning
Jun 20, 2019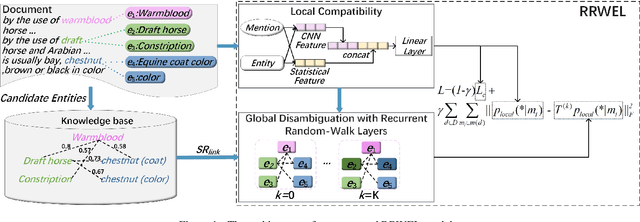
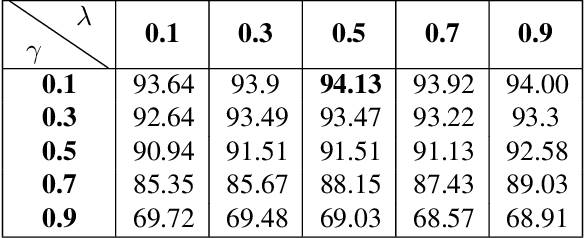
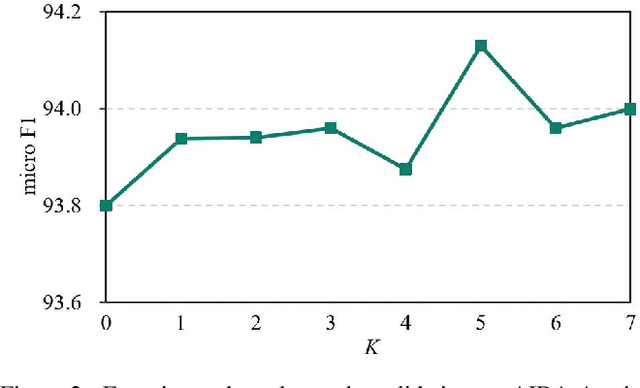
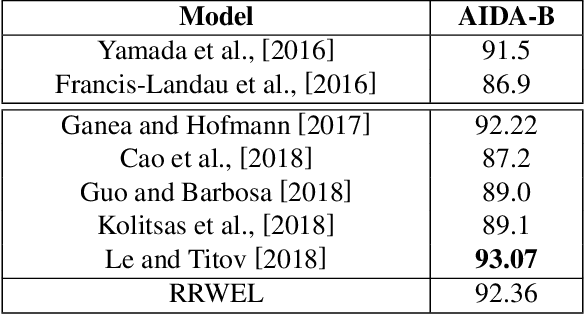
Benefiting from the excellent ability of neural networks on learning semantic representations, existing studies for entity linking (EL) have resorted to neural networks to exploit both the local mention-to-entity compatibility and the global interdependence between different EL decisions for target entity disambiguation. However, most neural collective EL methods depend entirely upon neural networks to automatically model the semantic dependencies between different EL decisions, which lack of the guidance from external knowledge. In this paper, we propose a novel end-to-end neural network with recurrent random-walk layers for collective EL, which introduces external knowledge to model the semantic interdependence between different EL decisions. Specifically, we first establish a model based on local context features, and then stack random-walk layers to reinforce the evidence for related EL decisions into high-probability decisions, where the semantic interdependence between candidate entities is mainly induced from an external knowledge base. Finally, a semantic regularizer that preserves the collective EL decisions consistency is incorporated into the conventional objective function, so that the external knowledge base can be fully exploited in collective EL decisions. Experimental results and in-depth analysis on various datasets show that our model achieves better performance than other state-of-the-art models. Our code and data are released at \url{https://github.com/DeepLearnXMU/RRWEL}.
Progressive Self-Supervised Attention Learning for Aspect-Level Sentiment Analysis
Jun 06, 2019
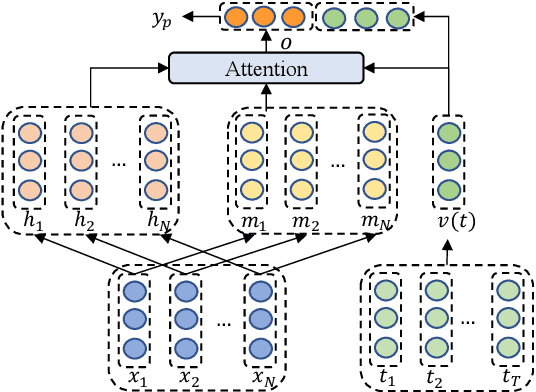
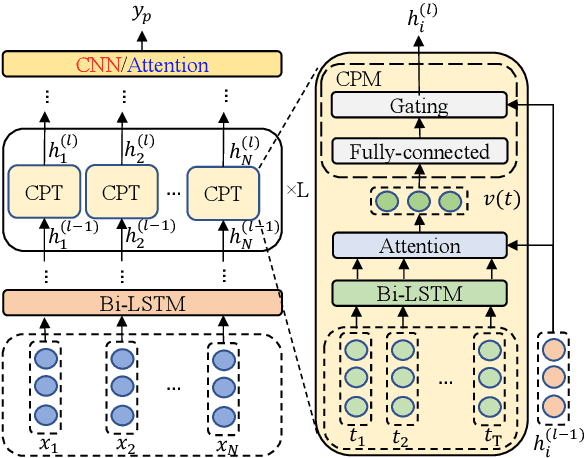

In aspect-level sentiment classification (ASC), it is prevalent to equip dominant neural models with attention mechanisms, for the sake of acquiring the importance of each context word on the given aspect. However, such a mechanism tends to excessively focus on a few frequent words with sentiment polarities, while ignoring infrequent ones. In this paper, we propose a progressive self-supervised attention learning approach for neural ASC models, which automatically mines useful attention supervision information from a training corpus to refine attention mechanisms. Specifically, we iteratively conduct sentiment predictions on all training instances. Particularly, at each iteration, the context word with the maximum attention weight is extracted as the one with active/misleading influence on the correct/incorrect prediction of every instance, and then the word itself is masked for subsequent iterations. Finally, we augment the conventional training objective with a regularization term, which enables ASC models to continue equally focusing on the extracted active context words while decreasing weights of those misleading ones. Experimental results on multiple datasets show that our proposed approach yields better attention mechanisms, leading to substantial improvements over the two state-of-the-art neural ASC models. Source code and trained models are available at https://github.com/DeepLearnXMU/PSSAttention.
* 10 pages