 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArrowGEV: Grounding Events in Video via Learning the Arrow of Time
Jan 10, 2026Grounding events in videos serves as a fundamental capability in video analysis. While Vision-Language Models (VLMs) are increasingly employed for this task, existing approaches predominantly train models to associate events with timestamps in the forward video only. This paradigm hinders VLMs from capturing the inherent temporal structure and directionality of events, thereby limiting robustness and generalization. To address this limitation, inspired by the arrow of time in physics, which characterizes the intrinsic directionality of temporal processes, we propose ArrowGEV, a reinforcement learning framework that explicitly models temporal directionality in events to improve both event grounding and temporal directionality understanding in VLMs. Specifically, we categorize events into time-sensitive (e.g., putting down a bag) and time-insensitive (e.g., holding a towel in the left hand). The former denote events whose reversal substantially alters their meaning, while the latter remain semantically unchanged under reversal. For time-sensitive events, ArrowGEV introduces a reward that encourages VLMs to discriminate between forward and backward videos, whereas for time-insensitive events, it enforces consistent grounding across both directions. Extensive experiments demonstrate that ArrowGEV not only improves grounding precision and temporal directionality recognition, but also enhances general video understanding and reasoning ability.
MaskMamba: A Hybrid Mamba-Transformer Model for Masked Image Generation
Sep 30, 2024



Image generation models have encountered challenges related to scalability and quadratic complexity, primarily due to the reliance on Transformer-based backbones. In this study, we introduce MaskMamba, a novel hybrid model that combines Mamba and Transformer architectures, utilizing Masked Image Modeling for non-autoregressive image synthesis. We meticulously redesign the bidirectional Mamba architecture by implementing two key modifications: (1) replacing causal convolutions with standard convolutions to better capture global context, and (2) utilizing concatenation instead of multiplication, which significantly boosts performance while accelerating inference speed. Additionally, we explore various hybrid schemes of MaskMamba, including both serial and grouped parallel arrangements. Furthermore, we incorporate an in-context condition that allows our model to perform both class-to-image and text-to-image generation tasks. Our MaskMamba outperforms Mamba-based and Transformer-based models in generation quality. Notably, it achieves a remarkable $54.44\%$ improvement in inference speed at a resolution of $2048\times 2048$ over Transformer.
Towards Robust k-Nearest-Neighbor Machine Translation
Oct 17, 2022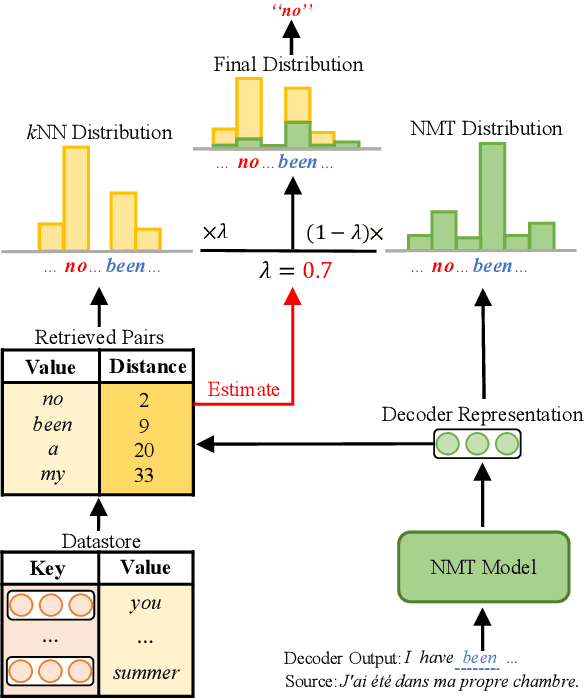
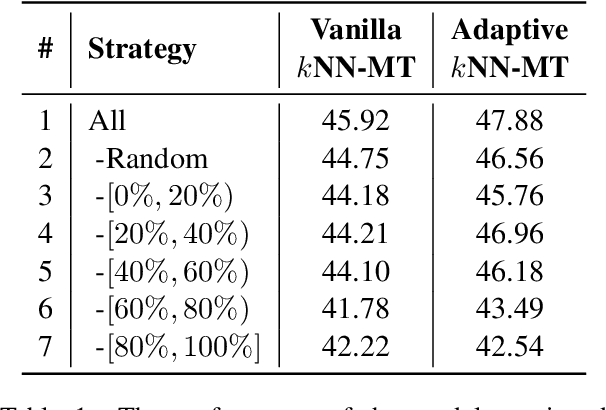
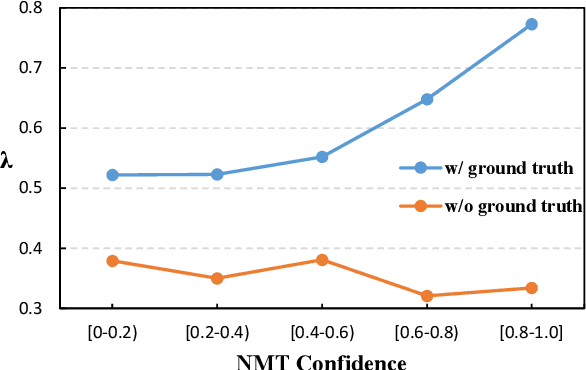
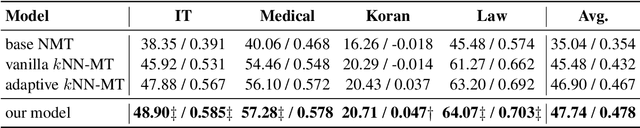
k-Nearest-Neighbor Machine Translation (kNN-MT) becomes an important research direction of NMT in recent years. Its main idea is to retrieve useful key-value pairs from an additional datastore to modify translations without updating the NMT model. However, the underlying retrieved noisy pairs will dramatically deteriorate the model performance. In this paper, we conduct a preliminary study and find that this problem results from not fully exploiting the prediction of the NMT model. To alleviate the impact of noise, we propose a confidence-enhanced kNN-MT model with robust training. Concretely, we introduce the NMT confidence to refine the modeling of two important components of kNN-MT: kNN distribution and the interpolation weight. Meanwhile we inject two types of perturbations into the retrieved pairs for robust training. Experimental results on four benchmark datasets demonstrate that our model not only achieves significant improvements over current kNN-MT models, but also exhibits better robustness. Our code is available at https://github.com/DeepLearnXMU/Robust-knn-mt.
ClidSum: A Benchmark Dataset for Cross-Lingual Dialogue Summarization
Feb 11, 2022
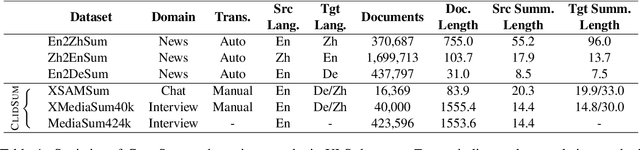
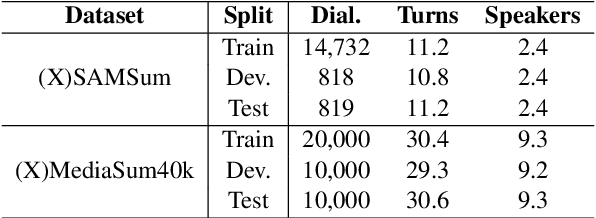

We present ClidSum, a benchmark dataset for building cross-lingual summarization systems on dialogue documents. It consists of 67k+ dialogue documents from two subsets (i.e., SAMSum and MediaSum) and 112k+ annotated summaries in different target languages. Based on the proposed ClidSum, we introduce two benchmark settings for supervised and semi-supervised scenarios, respectively. We then build various baseline systems in different paradigms (pipeline and end-to-end) and conduct extensive experiments on ClidSum to provide deeper analyses. Furthermore, we propose mDialBART which extends mBART-50 (a multi-lingual BART) via further pre-training. The multiple objectives used in the further pre-training stage help the pre-trained model capture the structural characteristics as well as important content in dialogues and the transformation from source to the target language. Experimental results show the superiority of mDialBART, as an end-to-end model, outperforms strong pipeline models on ClidSum. Finally, we discuss specific challenges that current approaches faced with this task and give multiple promising directions for future research. We have released the dataset and code at https://github.com/krystalan/ClidSum.
Enhanced Aspect-Based Sentiment Analysis Models with Progressive Self-supervised Attention Learning
Mar 05, 2021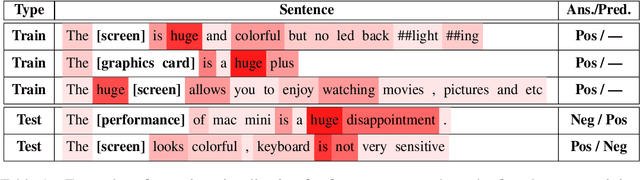
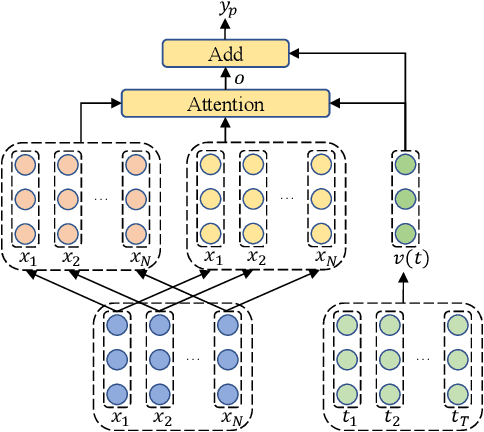
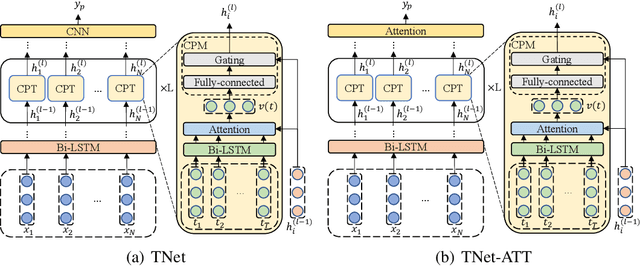

In aspect-based sentiment analysis (ABSA), many neural models are equipped with an attention mechanism to quantify the contribution of each context word to sentiment prediction. However, such a mechanism suffers from one drawback: only a few frequent words with sentiment polarities are tended to be taken into consideration for final sentiment decision while abundant infrequent sentiment words are ignored by models. To deal with this issue, we propose a progressive self-supervised attention learning approach for attentional ABSA models. In this approach, we iteratively perform sentiment prediction on all training instances, and continually learn useful attention supervision information in the meantime. During training, at each iteration, context words with the highest impact on sentiment prediction, identified based on their attention weights or gradients, are extracted as words with active/misleading influence on the correct/incorrect prediction for each instance. Words extracted in this way are masked for subsequent iterations. To exploit these extracted words for refining ABSA models, we augment the conventional training objective with a regularization term that encourages ABSA models to not only take full advantage of the extracted active context words but also decrease the weights of those misleading words. We integrate the proposed approach into three state-of-the-art neural ABSA models. Experiment results and in-depth analyses show that our approach yields better attention results and significantly enhances the performance of all three models. We release the source code and trained models at https://github.com/DeepLearnXMU/PSSAttention.
* 31 pages. arXiv admin note: text overlap with arXiv:1906.01213
Progressive Self-Supervised Attention Learning for Aspect-Level Sentiment Analysis
Jun 06, 2019
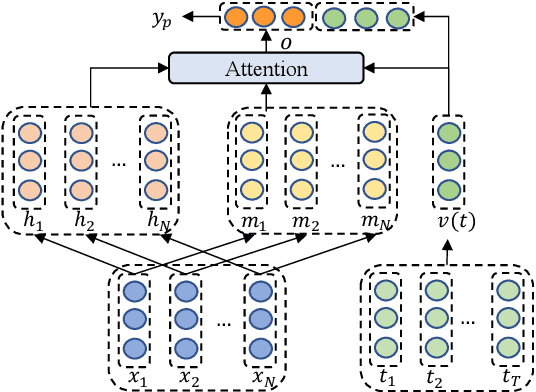
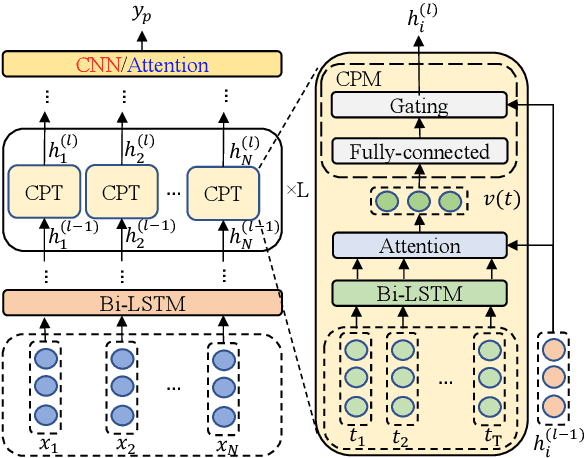

In aspect-level sentiment classification (ASC), it is prevalent to equip dominant neural models with attention mechanisms, for the sake of acquiring the importance of each context word on the given aspect. However, such a mechanism tends to excessively focus on a few frequent words with sentiment polarities, while ignoring infrequent ones. In this paper, we propose a progressive self-supervised attention learning approach for neural ASC models, which automatically mines useful attention supervision information from a training corpus to refine attention mechanisms. Specifically, we iteratively conduct sentiment predictions on all training instances. Particularly, at each iteration, the context word with the maximum attention weight is extracted as the one with active/misleading influence on the correct/incorrect prediction of every instance, and then the word itself is masked for subsequent iterations. Finally, we augment the conventional training objective with a regularization term, which enables ASC models to continue equally focusing on the extracted active context words while decreasing weights of those misleading ones. Experimental results on multiple datasets show that our proposed approach yields better attention mechanisms, leading to substantial improvements over the two state-of-the-art neural ASC models. Source code and trained models are available at https://github.com/DeepLearnXMU/PSSAttention.
* 10 pages