 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEscherVerse: An Open World Benchmark and Dataset for Teleo-Spatial Intelligence with Physical-Dynamic and Intent-Driven Understanding
Jan 04, 2026The ability to reason about spatial dynamics is a cornerstone of intelligence, yet current research overlooks the human intent behind spatial changes. To address these limitations, we introduce Teleo-Spatial Intelligence (TSI), a new paradigm that unifies two critical pillars: Physical-Dynamic Reasoning--understanding the physical principles of object interactions--and Intent-Driven Reasoning--inferring the human goals behind these actions. To catalyze research in TSI, we present EscherVerse, consisting of a large-scale, open-world benchmark (Escher-Bench), a dataset (Escher-35k), and models (Escher series). Derived from real-world videos, EscherVerse moves beyond constrained settings to explicitly evaluate an agent's ability to reason about object permanence, state transitions, and trajectory prediction in dynamic, human-centric scenarios. Crucially, it is the first benchmark to systematically assess Intent-Driven Reasoning, challenging models to connect physical events to their underlying human purposes. Our work, including a novel data curation pipeline, provides a foundational resource to advance spatial intelligence from passive scene description toward a holistic, purpose-driven understanding of the world.
FLEG: Feed-Forward Language Embedded Gaussian Splatting from Any Views
Dec 19, 2025



We present FLEG, a feed-forward network that reconstructs language-embedded 3D Gaussians from any views. Previous straightforward solutions combine feed-forward reconstruction with Gaussian heads but suffer from fixed input views and insufficient 3D training data. In contrast, we propose a 3D-annotation-free training framework for 2D-to-3D lifting from arbitrary uncalibrated and unposed multi-view images. Since the framework does not require 3D annotations, we can leverage large-scale video data with easily obtained 2D instance information to enrich semantic embedding. We also propose an instance-guided contrastive learning to align 2D semantics with the 3D representations. In addition, to mitigate the high memory and computational cost of dense views, we further propose a geometry-semantic hierarchical sparsification strategy. Our FLEG efficiently reconstructs language-embedded 3D Gaussian representation in a feed-forward manner from arbitrary sparse or dense views, jointly producing accurate geometry, high-fidelity appearance, and language-aligned semantics. Extensive experiments show that it outperforms existing methods on various related tasks. Project page: https://fangzhou2000.github.io/projects/fleg.
3D Guard-Layer: An Integrated Agentic AI Safety System for Edge Artificial Intelligence
Nov 11, 2025AI systems have found a wide range of real-world applications in recent years. The adoption of edge artificial intelligence, embedding AI directly into edge devices, is rapidly growing. Despite the implementation of guardrails and safety mechanisms, security vulnerabilities and challenges have become increasingly prevalent in this domain, posing a significant barrier to the practical deployment and safety of AI systems. This paper proposes an agentic AI safety architecture that leverages 3D to integrate a dedicated safety layer. It introduces an adaptive AI safety infrastructure capable of dynamically learning and mitigating attacks against the AI system. The system leverages the inherent advantages of co-location with the edge computing hardware to continuously monitor, detect and proactively mitigate threats to the AI system. The integration of local processing and learning capabilities enhances resilience against emerging network-based attacks while simultaneously improving system reliability, modularity, and performance, all with minimal cost and 3D integration overhead.
CaRF: Enhancing Multi-View Consistency in Referring 3D Gaussian Splatting Segmentation
Nov 06, 2025



Referring 3D Gaussian Splatting Segmentation (R3DGS) aims to interpret free-form language expressions and localize the corresponding 3D regions in Gaussian fields. While recent advances have introduced cross-modal alignment between language and 3D geometry, existing pipelines still struggle with cross-view consistency due to their reliance on 2D rendered pseudo supervision and view specific feature learning. In this work, we present Camera Aware Referring Field (CaRF), a fully differentiable framework that operates directly in the 3D Gaussian space and achieves multi view consistency. Specifically, CaRF introduces Gaussian Field Camera Encoding (GFCE), which incorporates camera geometry into Gaussian text interactions to explicitly model view dependent variations and enhance geometric reasoning. Building on this, In Training Paired View Supervision (ITPVS) is proposed to align per Gaussian logits across calibrated views during training, effectively mitigating single view overfitting and exposing inter view discrepancies for optimization. Extensive experiments on three representative benchmarks demonstrate that CaRF achieves average improvements of 16.8%, 4.3%, and 2.0% in mIoU over state of the art methods on the Ref LERF, LERF OVS, and 3D OVS datasets, respectively. Moreover, this work promotes more reliable and view consistent 3D scene understanding, with potential benefits for embodied AI, AR/VR interaction, and autonomous perception.
Switchable Token-Specific Codebook Quantization For Face Image Compression
Oct 27, 2025With the ever-increasing volume of visual data, the efficient and lossless transmission, along with its subsequent interpretation and understanding, has become a critical bottleneck in modern information systems. The emerged codebook-based solution utilize a globally shared codebook to quantize and dequantize each token, controlling the bpp by adjusting the number of tokens or the codebook size. However, for facial images, which are rich in attributes, such global codebook strategies overlook both the category-specific correlations within images and the semantic differences among tokens, resulting in suboptimal performance, especially at low bpp. Motivated by these observations, we propose a Switchable Token-Specific Codebook Quantization for face image compression, which learns distinct codebook groups for different image categories and assigns an independent codebook to each token. By recording the codebook group to which each token belongs with a small number of bits, our method can reduce the loss incurred when decreasing the size of each codebook group. This enables a larger total number of codebooks under a lower overall bpp, thereby enhancing the expressive capability and improving reconstruction performance. Owing to its generalizable design, our method can be integrated into any existing codebook-based representation learning approach and has demonstrated its effectiveness on face recognition datasets, achieving an average accuracy of 93.51% for reconstructed images at 0.05 bpp.
InfiR2: A Comprehensive FP8 Training Recipe for Reasoning-Enhanced Language Models
Sep 26, 2025


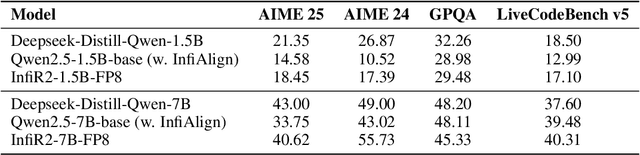
The immense computational cost of training Large Language Models (LLMs) presents a major barrier to innovation. While FP8 training offers a promising solution with significant theoretical efficiency gains, its widespread adoption has been hindered by the lack of a comprehensive, open-source training recipe. To bridge this gap, we introduce an end-to-end FP8 training recipe that seamlessly integrates continual pre-training and supervised fine-tuning. Our methodology employs a fine-grained, hybrid-granularity quantization strategy to maintain numerical fidelity while maximizing computational efficiency. Through extensive experiments, including the continue pre-training of models on a 160B-token corpus, we demonstrate that our recipe is not only remarkably stable but also essentially lossless, achieving performance on par with the BF16 baseline across a suite of reasoning benchmarks. Crucially, this is achieved with substantial efficiency improvements, including up to a 22% reduction in training time, a 14% decrease in peak memory usage, and a 19% increase in throughput. Our results establish FP8 as a practical and robust alternative to BF16, and we will release the accompanying code to further democratize large-scale model training.
SeqVLM: Proposal-Guided Multi-View Sequences Reasoning via VLM for Zero-Shot 3D Visual Grounding
Aug 28, 2025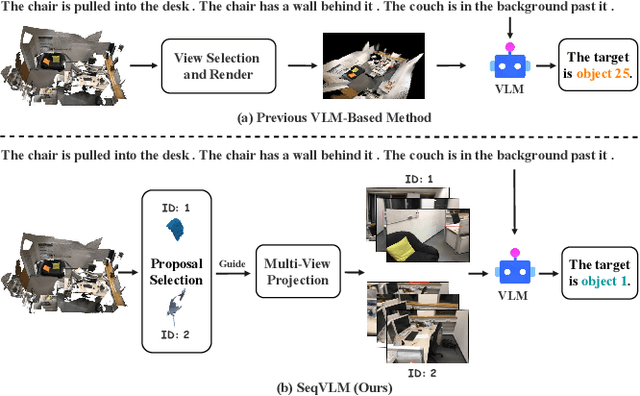
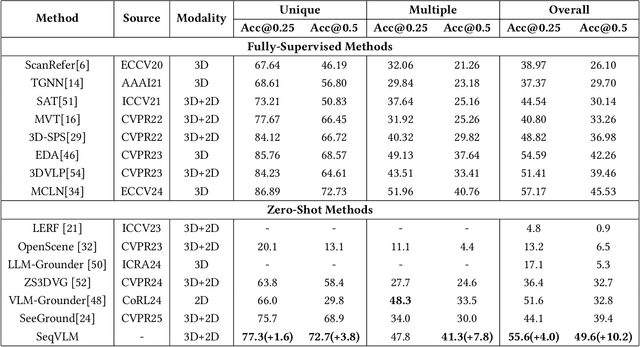
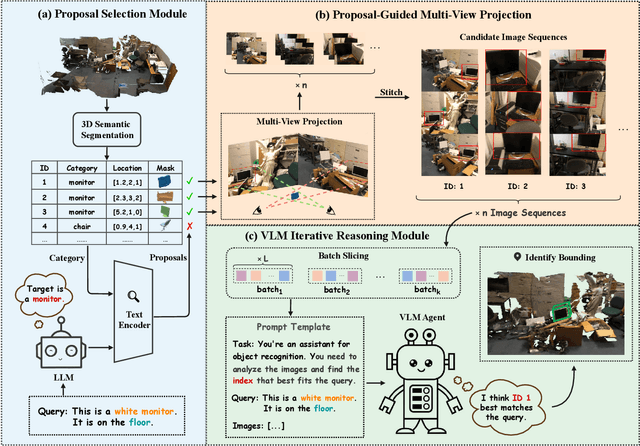
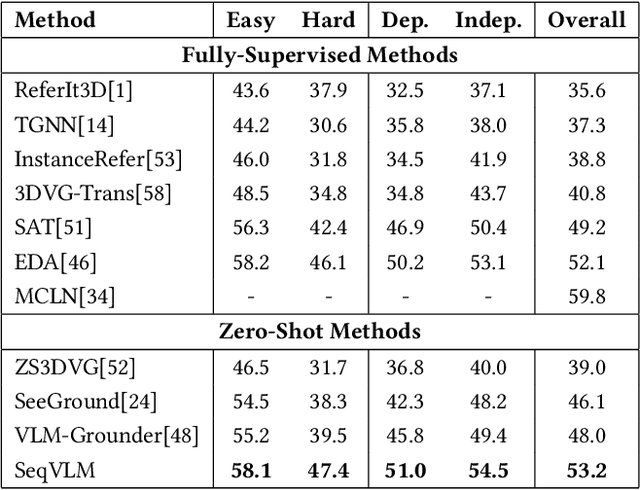
3D Visual Grounding (3DVG) aims to localize objects in 3D scenes using natural language descriptions. Although supervised methods achieve higher accuracy in constrained settings, zero-shot 3DVG holds greater promise for real-world applications since eliminating scene-specific training requirements. However, existing zero-shot methods face challenges of spatial-limited reasoning due to reliance on single-view localization, and contextual omissions or detail degradation. To address these issues, we propose SeqVLM, a novel zero-shot 3DVG framework that leverages multi-view real-world scene images with spatial information for target object reasoning. Specifically, SeqVLM first generates 3D instance proposals via a 3D semantic segmentation network and refines them through semantic filtering, retaining only semantic-relevant candidates. A proposal-guided multi-view projection strategy then projects these candidate proposals onto real scene image sequences, preserving spatial relationships and contextual details in the conversion process of 3D point cloud to images. Furthermore, to mitigate VLM computational overload, we implement a dynamic scheduling mechanism that iteratively processes sequances-query prompts, leveraging VLM's cross-modal reasoning capabilities to identify textually specified objects. Experiments on the ScanRefer and Nr3D benchmarks demonstrate state-of-the-art performance, achieving Acc@0.25 scores of 55.6% and 53.2%, surpassing previous zero-shot methods by 4.0% and 5.2%, respectively, which advance 3DVG toward greater generalization and real-world applicability. The code is available at https://github.com/JiawLin/SeqVLM.
MOL: Joint Estimation of Micro-Expression, Optical Flow, and Landmark via Transformer-Graph-Style Convolution
Jun 17, 2025


Facial micro-expression recognition (MER) is a challenging problem, due to transient and subtle micro-expression (ME) actions. Most existing methods depend on hand-crafted features, key frames like onset, apex, and offset frames, or deep networks limited by small-scale and low-diversity datasets. In this paper, we propose an end-to-end micro-action-aware deep learning framework with advantages from transformer, graph convolution, and vanilla convolution. In particular, we propose a novel F5C block composed of fully-connected convolution and channel correspondence convolution to directly extract local-global features from a sequence of raw frames, without the prior knowledge of key frames. The transformer-style fully-connected convolution is proposed to extract local features while maintaining global receptive fields, and the graph-style channel correspondence convolution is introduced to model the correlations among feature patterns. Moreover, MER, optical flow estimation, and facial landmark detection are jointly trained by sharing the local-global features. The two latter tasks contribute to capturing facial subtle action information for MER, which can alleviate the impact of insufficient training data. Extensive experiments demonstrate that our framework (i) outperforms the state-of-the-art MER methods on CASME II, SAMM, and SMIC benchmarks, (ii) works well for optical flow estimation and facial landmark detection, and (iii) can capture facial subtle muscle actions in local regions associated with MEs. The code is available at https://github.com/CYF-cuber/MOL.
UniForward: Unified 3D Scene and Semantic Field Reconstruction via Feed-Forward Gaussian Splatting from Only Sparse-View Images
Jun 11, 2025We propose a feed-forward Gaussian Splatting model that unifies 3D scene and semantic field reconstruction. Combining 3D scenes with semantic fields facilitates the perception and understanding of the surrounding environment. However, key challenges include embedding semantics into 3D representations, achieving generalizable real-time reconstruction, and ensuring practical applicability by using only images as input without camera parameters or ground truth depth. To this end, we propose UniForward, a feed-forward model to predict 3D Gaussians with anisotropic semantic features from only uncalibrated and unposed sparse-view images. To enable the unified representation of the 3D scene and semantic field, we embed semantic features into 3D Gaussians and predict them through a dual-branch decoupled decoder. During training, we propose a loss-guided view sampler to sample views from easy to hard, eliminating the need for ground truth depth or masks required by previous methods and stabilizing the training process. The whole model can be trained end-to-end using a photometric loss and a distillation loss that leverages semantic features from a pre-trained 2D semantic model. At the inference stage, our UniForward can reconstruct 3D scenes and the corresponding semantic fields in real time from only sparse-view images. The reconstructed 3D scenes achieve high-quality rendering, and the reconstructed 3D semantic field enables the rendering of view-consistent semantic features from arbitrary views, which can be further decoded into dense segmentation masks in an open-vocabulary manner. Experiments on novel view synthesis and novel view segmentation demonstrate that our method achieves state-of-the-art performances for unifying 3D scene and semantic field reconstruction.
SHTOcc: Effective 3D Occupancy Prediction with Sparse Head and Tail Voxels
May 29, 20253D occupancy prediction has attracted much attention in the field of autonomous driving due to its powerful geometric perception and object recognition capabilities. However, existing methods have not explored the most essential distribution patterns of voxels, resulting in unsatisfactory results. This paper first explores the inter-class distribution and geometric distribution of voxels, thereby solving the long-tail problem caused by the inter-class distribution and the poor performance caused by the geometric distribution. Specifically, this paper proposes SHTOcc (Sparse Head-Tail Occupancy), which uses sparse head-tail voxel construction to accurately identify and balance key voxels in the head and tail classes, while using decoupled learning to reduce the model's bias towards the dominant (head) category and enhance the focus on the tail class. Experiments show that significant improvements have been made on multiple baselines: SHTOcc reduces GPU memory usage by 42.2%, increases inference speed by 58.6%, and improves accuracy by about 7%, verifying its effectiveness and efficiency. The code is available at https://github.com/ge95net/SHTOcc