 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePC-CrossDiff: Point-Cluster Dual-Level Cross-Modal Differential Attention for Unified 3D Referring and Segmentation
Mar 18, 20263D Visual Grounding (3DVG) aims to localize the referent of natural language referring expressions through two core tasks: Referring Expression Comprehension (3DREC) and Segmentation (3DRES). While existing methods achieve high accuracy in simple, single-object scenes, they suffer from severe performance degradation in complex, multi-object scenes that are common in real-world settings, hindering practical deployment. Existing methods face two key challenges in complex, multi-object scenes: inadequate parsing of implicit localization cues critical for disambiguating visually similar objects, and ineffective suppression of dynamic spatial interference from co-occurring objects, resulting in degraded grounding accuracy. To address these challenges, we propose PC-CrossDiff, a unified dual-task framework with a dual-level cross-modal differential attention architecture for 3DREC and 3DRES. Specifically, the framework introduces: (i) Point-Level Differential Attention (PLDA) modules that apply bidirectional differential attention between text and point clouds, adaptively extracting implicit localization cues via learnable weights to improve discriminative representation; (ii) Cluster-Level Differential Attention (CLDA) modules that establish a hierarchical attention mechanism to adaptively enhance localization-relevant spatial relationships while suppressing ambiguous or irrelevant spatial relations through a localization-aware differential attention block. Our method achieves state-of-the-art performance on the ScanRefer, NR3D, and SR3D benchmarks. Notably, on the Implicit subsets of ScanRefer, it improves the Overall@0.50 score by +10.16% for the 3DREC task, highlighting its strong ability to parse implicit spatial cues.
SeqVLM: Proposal-Guided Multi-View Sequences Reasoning via VLM for Zero-Shot 3D Visual Grounding
Aug 28, 2025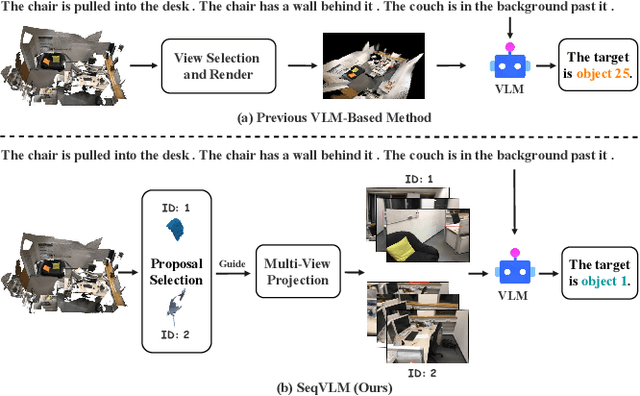
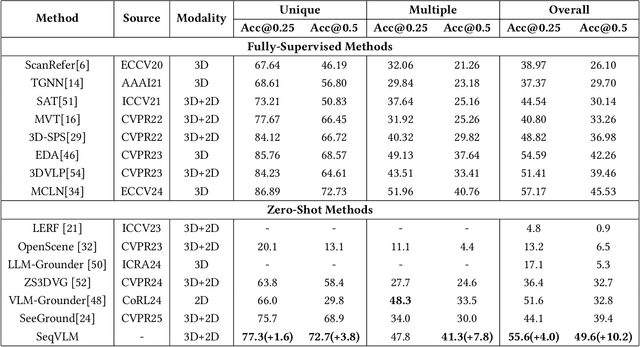
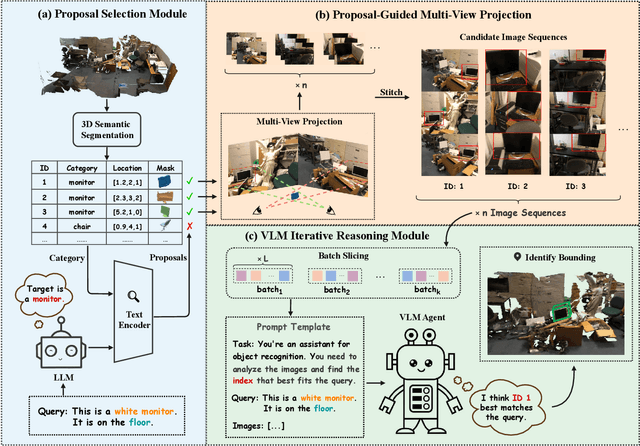
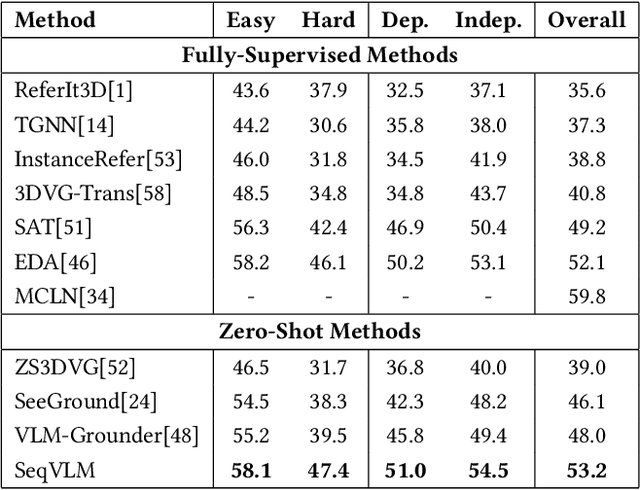
3D Visual Grounding (3DVG) aims to localize objects in 3D scenes using natural language descriptions. Although supervised methods achieve higher accuracy in constrained settings, zero-shot 3DVG holds greater promise for real-world applications since eliminating scene-specific training requirements. However, existing zero-shot methods face challenges of spatial-limited reasoning due to reliance on single-view localization, and contextual omissions or detail degradation. To address these issues, we propose SeqVLM, a novel zero-shot 3DVG framework that leverages multi-view real-world scene images with spatial information for target object reasoning. Specifically, SeqVLM first generates 3D instance proposals via a 3D semantic segmentation network and refines them through semantic filtering, retaining only semantic-relevant candidates. A proposal-guided multi-view projection strategy then projects these candidate proposals onto real scene image sequences, preserving spatial relationships and contextual details in the conversion process of 3D point cloud to images. Furthermore, to mitigate VLM computational overload, we implement a dynamic scheduling mechanism that iteratively processes sequances-query prompts, leveraging VLM's cross-modal reasoning capabilities to identify textually specified objects. Experiments on the ScanRefer and Nr3D benchmarks demonstrate state-of-the-art performance, achieving Acc@0.25 scores of 55.6% and 53.2%, surpassing previous zero-shot methods by 4.0% and 5.2%, respectively, which advance 3DVG toward greater generalization and real-world applicability. The code is available at https://github.com/JiawLin/SeqVLM.