 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCycleChart: A Unified Consistency-Based Learning Framework for Bidirectional Chart Understanding and Generation
Dec 22, 2025Current chart-specific tasks, such as chart question answering, chart parsing, and chart generation, are typically studied in isolation, preventing models from learning the shared semantics that link chart generation and interpretation. We introduce CycleChart, a consistency-based learning framework for bidirectional chart understanding and generation. CycleChart adopts a schema-centric formulation as a common interface across tasks. We construct a consistent multi-task dataset, where each chart sample includes aligned annotations for schema prediction, data parsing, and question answering. To learn cross-directional chart semantics, CycleChart introduces a generate-parse consistency objective: the model generates a chart schema from a table and a textual query, then learns to recover the schema and data from the generated chart, enforcing semantic alignment across directions. CycleChart achieves strong results on chart generation, chart parsing, and chart question answering, demonstrating improved cross-task generalization and marking a step toward more general chart understanding models.
Flowing from Reasoning to Motion: Learning 3D Hand Trajectory Prediction from Egocentric Human Interaction Videos
Dec 18, 2025Prior works on 3D hand trajectory prediction are constrained by datasets that decouple motion from semantic supervision and by models that weakly link reasoning and action. To address these, we first present the EgoMAN dataset, a large-scale egocentric dataset for interaction stage-aware 3D hand trajectory prediction with 219K 6DoF trajectories and 3M structured QA pairs for semantic, spatial, and motion reasoning. We then introduce the EgoMAN model, a reasoning-to-motion framework that links vision-language reasoning and motion generation via a trajectory-token interface. Trained progressively to align reasoning with motion dynamics, our approach yields accurate and stage-aware trajectories with generalization across real-world scenes.
Embodied Image Compression
Dec 12, 2025



Image Compression for Machines (ICM) has emerged as a pivotal research direction in the field of visual data compression. However, with the rapid evolution of machine intelligence, the target of compression has shifted from task-specific virtual models to Embodied agents operating in real-world environments. To address the communication constraints of Embodied AI in multi-agent systems and ensure real-time task execution, this paper introduces, for the first time, the scientific problem of Embodied Image Compression. We establish a standardized benchmark, EmbodiedComp, to facilitate systematic evaluation under ultra-low bitrate conditions in a closed-loop setting. Through extensive empirical studies in both simulated and real-world settings, we demonstrate that existing Vision-Language-Action models (VLAs) fail to reliably perform even simple manipulation tasks when compressed below the Embodied bitrate threshold. We anticipate that EmbodiedComp will catalyze the development of domain-specific compression tailored for Embodied agents , thereby accelerating the Embodied AI deployment in the Real-world.
MACEval: A Multi-Agent Continual Evaluation Network for Large Models
Nov 12, 2025Hundreds of benchmarks dedicated to evaluating large models from multiple perspectives have been presented over the past few years. Albeit substantial efforts, most of them remain closed-ended and are prone to overfitting due to the potential data contamination in the ever-growing training corpus of large models, thereby undermining the credibility of the evaluation. Moreover, the increasing scale and scope of current benchmarks with transient metrics, as well as the heavily human-dependent curation procedure, pose significant challenges for timely maintenance and adaptation to gauge the advancing capabilities of large models. In this paper, we introduce MACEval, a \Multi-Agent Continual Evaluation network for dynamic evaluation of large models, and define a new set of metrics to quantify performance longitudinally and sustainably. MACEval adopts an interactive and autonomous evaluation mode that employs role assignment, in-process data generation, and evaluation routing through a cascaded agent network. Extensive experiments on 9 open-ended tasks with 23 participating large models demonstrate that MACEval is (1) human-free and automatic, mitigating laborious result processing with inter-agent judgment guided; (2) efficient and economical, reducing a considerable amount of data and overhead to obtain similar results compared to related benchmarks; and (3) flexible and scalable, migrating or integrating existing benchmarks via customized evaluation topologies. We hope that MACEval can broaden future directions of large model evaluation.
GeoGen: A Two-stage Coarse-to-Fine Framework for Fine-grained Synthetic Location-based Social Network Trajectory Generation
Oct 09, 2025



Location-Based Social Network (LBSN) check-in trajectory data are important for many practical applications, like POI recommendation, advertising, and pandemic intervention. However, the high collection costs and ever-increasing privacy concerns prevent us from accessing large-scale LBSN trajectory data. The recent advances in synthetic data generation provide us with a new opportunity to achieve this, which utilizes generative AI to generate synthetic data that preserves the characteristics of real data while ensuring privacy protection. However, generating synthetic LBSN check-in trajectories remains challenging due to their spatially discrete, temporally irregular nature and the complex spatio-temporal patterns caused by sparse activities and uncertain human mobility. To address this challenge, we propose GeoGen, a two-stage coarse-to-fine framework for large-scale LBSN check-in trajectory generation. In the first stage, we reconstruct spatially continuous, temporally regular latent movement sequences from the original LBSN check-in trajectories and then design a Sparsity-aware Spatio-temporal Diffusion model (S$^2$TDiff) with an efficient denosing network to learn their underlying behavioral patterns. In the second stage, we design Coarse2FineNet, a Transformer-based Seq2Seq architecture equipped with a dynamic context fusion mechanism in the encoder and a multi-task hybrid-head decoder, which generates fine-grained LBSN trajectories based on coarse-grained latent movement sequences by modeling semantic relevance and behavioral uncertainty. Extensive experiments on four real-world datasets show that GeoGen excels state-of-the-art models for both fidelity and utility evaluation, e.g., it increases over 69% and 55% in distance and radius metrics on the FS-TKY dataset.
PEHRT: A Common Pipeline for Harmonizing Electronic Health Record data for Translational Research
Sep 10, 2025
Integrative analysis of multi-institutional Electronic Health Record (EHR) data enhances the reliability and generalizability of translational research by leveraging larger, more diverse patient cohorts and incorporating multiple data modalities. However, harmonizing EHR data across institutions poses major challenges due to data heterogeneity, semantic differences, and privacy concerns. To address these challenges, we introduce $\textit{PEHRT}$, a standardized pipeline for efficient EHR data harmonization consisting of two core modules: (1) data pre-processing and (2) representation learning. PEHRT maps EHR data to standard coding systems and uses advanced machine learning to generate research-ready datasets without requiring individual-level data sharing. Our pipeline is also data model agnostic and designed for streamlined execution across institutions based on our extensive real-world experience. We provide a complete suite of open source software, accompanied by a user-friendly tutorial, and demonstrate the utility of PEHRT in a variety of tasks using data from diverse healthcare systems.
Can Large Models Fool the Eye? A New Turing Test for Biological Animation
Aug 08, 2025Evaluating the abilities of large models and manifesting their gaps are challenging. Current benchmarks adopt either ground-truth-based score-form evaluation on static datasets or indistinct textual chatbot-style human preferences collection, which may not provide users with immediate, intuitive, and perceptible feedback on performance differences. In this paper, we introduce BioMotion Arena, a novel framework for evaluating large language models (LLMs) and multimodal large language models (MLLMs) via visual animation. Our methodology draws inspiration from the inherent visual perception of motion patterns characteristic of living organisms that utilizes point-light source imaging to amplify the performance discrepancies between models. Specifically, we employ a pairwise comparison evaluation and collect more than 45k votes for 53 mainstream LLMs and MLLMs on 90 biological motion variants. Data analyses show that the crowd-sourced human votes are in good agreement with those of expert raters, demonstrating the superiority of our BioMotion Arena in offering discriminative feedback. We also find that over 90\% of evaluated models, including the cutting-edge open-source InternVL3 and proprietary Claude-4 series, fail to produce fundamental humanoid point-light groups, much less smooth and biologically plausible motions. This enables BioMotion Arena to serve as a challenging benchmark for performance visualization and a flexible evaluation framework without restrictions on ground-truth.
SDEval: Safety Dynamic Evaluation for Multimodal Large Language Models
Aug 08, 2025



In the rapidly evolving landscape of Multimodal Large Language Models (MLLMs), the safety concerns of their outputs have earned significant attention. Although numerous datasets have been proposed, they may become outdated with MLLM advancements and are susceptible to data contamination issues. To address these problems, we propose \textbf{SDEval}, the \textit{first} safety dynamic evaluation framework to controllably adjust the distribution and complexity of safety benchmarks. Specifically, SDEval mainly adopts three dynamic strategies: text, image, and text-image dynamics to generate new samples from original benchmarks. We first explore the individual effects of text and image dynamics on model safety. Then, we find that injecting text dynamics into images can further impact safety, and conversely, injecting image dynamics into text also leads to safety risks. SDEval is general enough to be applied to various existing safety and even capability benchmarks. Experiments across safety benchmarks, MLLMGuard and VLSBench, and capability benchmarks, MMBench and MMVet, show that SDEval significantly influences safety evaluation, mitigates data contamination, and exposes safety limitations of MLLMs. Code is available at https://github.com/hq-King/SDEval
MAMBO-NET: Multi-Causal Aware Modeling Backdoor-Intervention Optimization for Medical Image Segmentation Network
May 28, 2025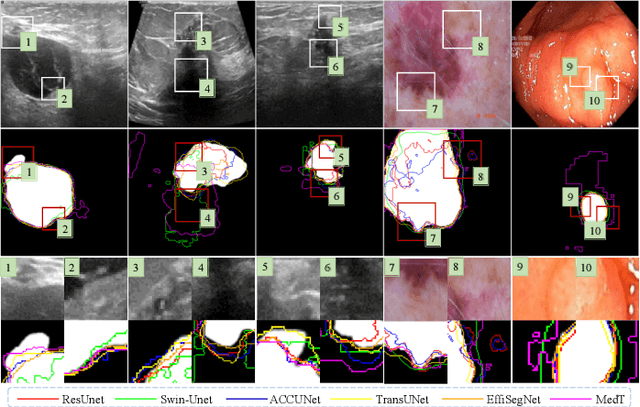
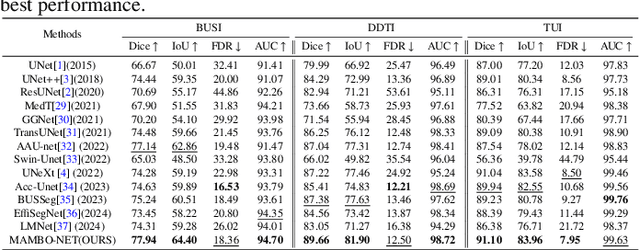
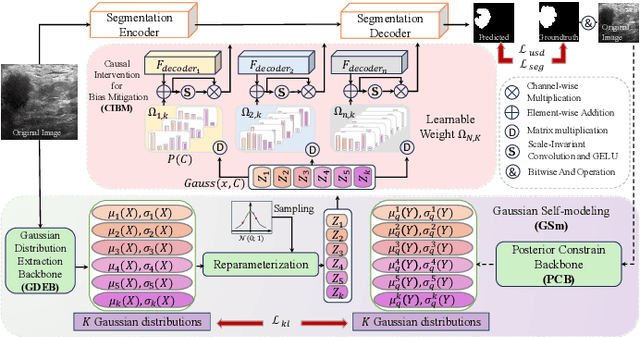
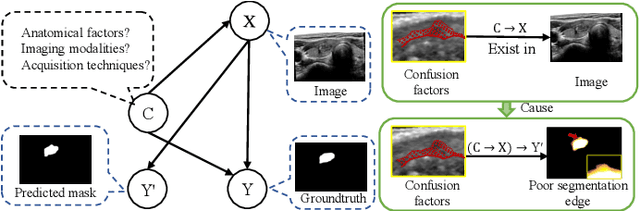
Medical image segmentation methods generally assume that the process from medical image to segmentation is unbiased, and use neural networks to establish conditional probability models to complete the segmentation task. This assumption does not consider confusion factors, which can affect medical images, such as complex anatomical variations and imaging modality limitations. Confusion factors obfuscate the relevance and causality of medical image segmentation, leading to unsatisfactory segmentation results. To address this issue, we propose a multi-causal aware modeling backdoor-intervention optimization (MAMBO-NET) network for medical image segmentation. Drawing insights from causal inference, MAMBO-NET utilizes self-modeling with multi-Gaussian distributions to fit the confusion factors and introduce causal intervention into the segmentation process. Moreover, we design appropriate posterior probability constraints to effectively train the distributions of confusion factors. For the distributions to effectively guide the segmentation and mitigate and eliminate the Impact of confusion factors on the segmentation, we introduce classical backdoor intervention techniques and analyze their feasibility in the segmentation task. To evaluate the effectiveness of our approach, we conducted extensive experiments on five medical image datasets. The results demonstrate that our method significantly reduces the influence of confusion factors, leading to enhanced segmentation accuracy.
Perceptual Quality Assessment for Embodied AI
May 22, 2025



Embodied AI has developed rapidly in recent years, but it is still mainly deployed in laboratories, with various distortions in the Real-world limiting its application. Traditionally, Image Quality Assessment (IQA) methods are applied to predict human preferences for distorted images; however, there is no IQA method to assess the usability of an image in embodied tasks, namely, the perceptual quality for robots. To provide accurate and reliable quality indicators for future embodied scenarios, we first propose the topic: IQA for Embodied AI. Specifically, we (1) based on the Mertonian system and meta-cognitive theory, constructed a perception-cognition-decision-execution pipeline and defined a comprehensive subjective score collection process; (2) established the Embodied-IQA database, containing over 36k reference/distorted image pairs, with more than 5m fine-grained annotations provided by Vision Language Models/Vision Language Action-models/Real-world robots; (3) trained and validated the performance of mainstream IQA methods on Embodied-IQA, demonstrating the need to develop more accurate quality indicators for Embodied AI. We sincerely hope that through evaluation, we can promote the application of Embodied AI under complex distortions in the Real-world. Project page: https://github.com/lcysyzxdxc/EmbodiedIQA