 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERTMap: A BERT-based Ontology Alignment System
Dec 23, 2021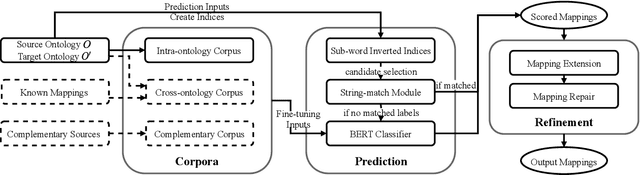
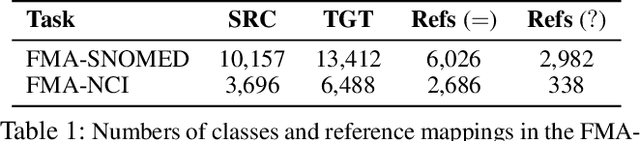
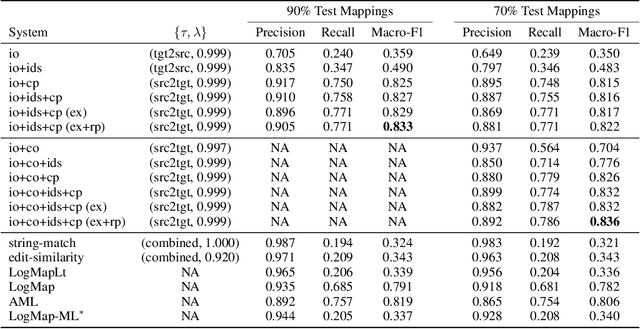
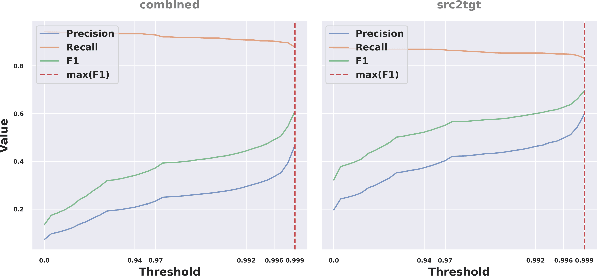
Ontology alignment (a.k.a ontology matching (OM)) plays a critical role in knowledge integration. Owing to the success of machine learning in many domains, it has been applied in OM. However, the existing methods, which often adopt ad-hoc feature engineering or non-contextual word embeddings, have not yet outperformed rule-based systems especially in an unsupervised setting. In this paper, we propose a novel OM system named BERTMap which can support both unsupervised and semi-supervised settings. It first predicts mappings using a classifier based on fine-tuning the contextual embedding model BERT on text semantics corpora extracted from ontologies, and then refines the mappings through extension and repair by utilizing the ontology structure and logic. Our evaluation with three alignment tasks on biomedical ontologies demonstrates that BERTMap can often perform better than the leading OM systems LogMap and AML.
Unrestricted Adversarial Attacks on ImageNet Competition
Oct 25, 2021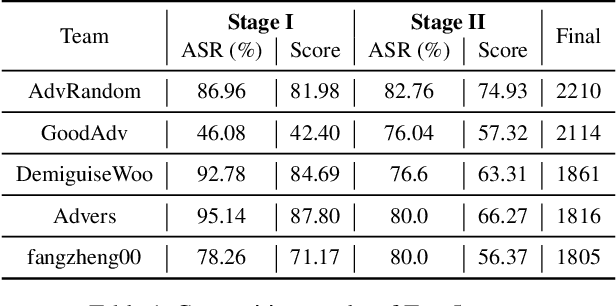
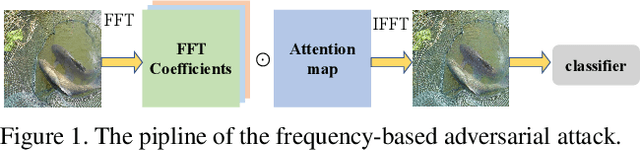
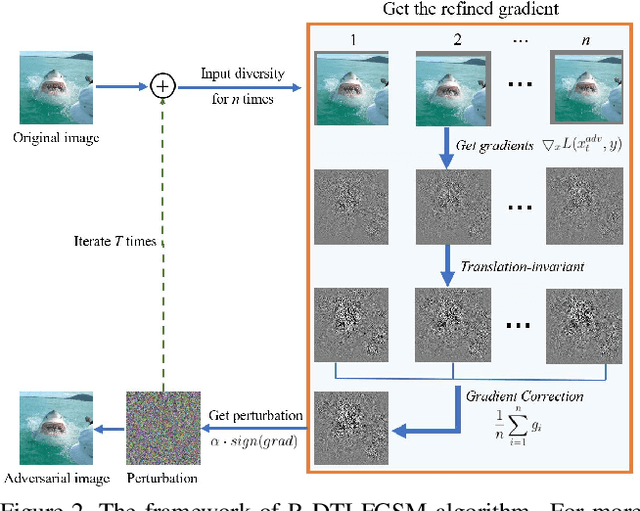
Many works have investigated the adversarial attacks or defenses under the settings where a bounded and imperceptible perturbation can be added to the input. However in the real-world, the attacker does not need to comply with this restriction. In fact, more threats to the deep model come from unrestricted adversarial examples, that is, the attacker makes large and visible modifications on the image, which causes the model classifying mistakenly, but does not affect the normal observation in human perspective. Unrestricted adversarial attack is a popular and practical direction but has not been studied thoroughly. We organize this competition with the purpose of exploring more effective unrestricted adversarial attack algorithm, so as to accelerate the academical research on the model robustness under stronger unbounded attacks. The competition is held on the TianChi platform (\url{https://tianchi.aliyun.com/competition/entrance/531853/introduction}) as one of the series of AI Security Challengers Program.
Adversarial Attacks on ML Defense Models Competition
Oct 15, 2021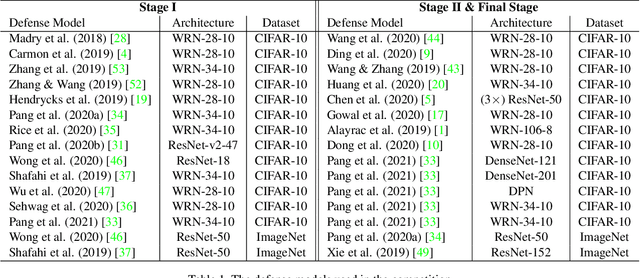
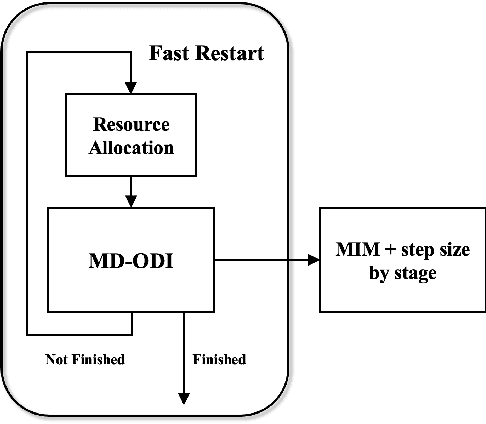
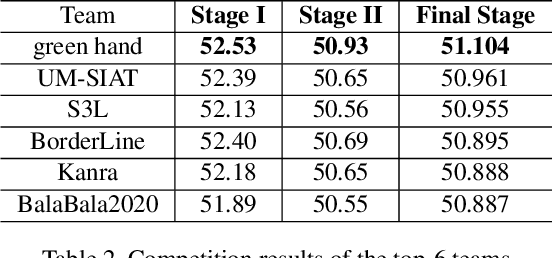
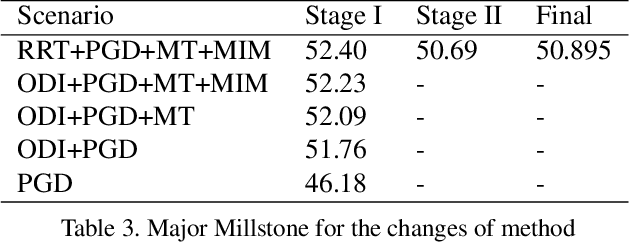
Due to the vulnerability of deep neural networks (DNNs) to adversarial examples, a large number of defense techniques have been proposed to alleviate this problem in recent years. However, the progress of building more robust models is usually hampered by the incomplete or incorrect robustness evaluation. To accelerate the research on reliable evaluation of adversarial robustness of the current defense models in image classification, the TSAIL group at Tsinghua University and the Alibaba Security group organized this competition along with a CVPR 2021 workshop on adversarial machine learning (https://aisecure-workshop.github.io/amlcvpr2021/). The purpose of this competition is to motivate novel attack algorithms to evaluate adversarial robustness more effectively and reliably. The participants were encouraged to develop stronger white-box attack algorithms to find the worst-case robustness of different defenses. This competition was conducted on an adversarial robustness evaluation platform -- ARES (https://github.com/thu-ml/ares), and is held on the TianChi platform (https://tianchi.aliyun.com/competition/entrance/531847/introduction) as one of the series of AI Security Challengers Program. After the competition, we summarized the results and established a new adversarial robustness benchmark at https://ml.cs.tsinghua.edu.cn/ares-bench/, which allows users to upload adversarial attack algorithms and defense models for evaluation.
Prior-Guided Deep Interference Mitigation for FMCW Radars
Aug 30, 2021
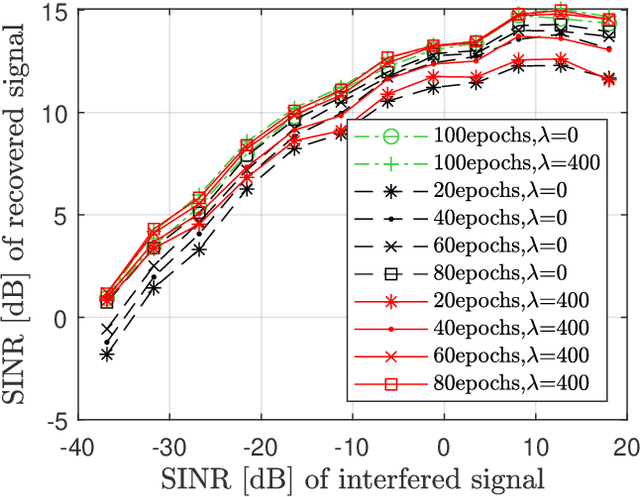
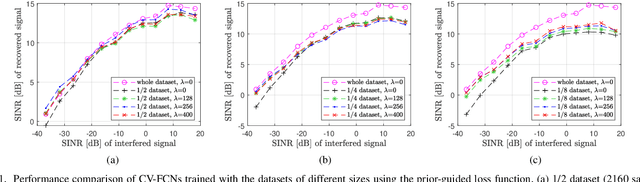
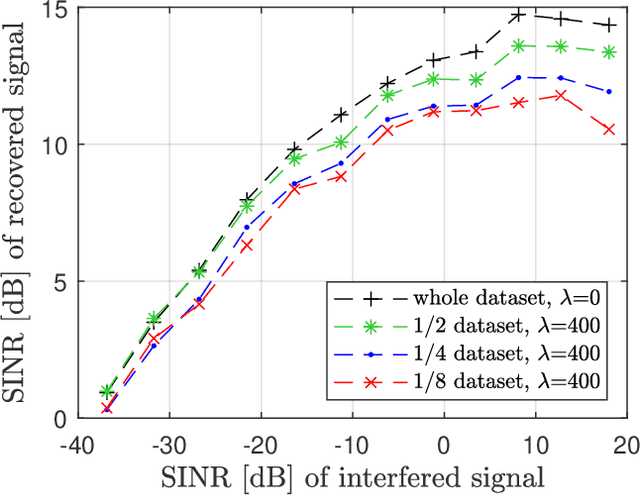
A prior-guided deep learning (DL) based interference mitigation approach is proposed for frequency modulated continuous wave (FMCW) radars. In this paper, the interference mitigation problem is tackled as a regression problem. Considering the complex-valued nature of radar signals, the complex-valued convolutional neural network is utilized as an architecture for implementation, which is different from the conventional real-valued counterparts. Meanwhile, as the useful beat signals of FMCW radars and interferences exhibit different distributions in the time-frequency domain, this prior feature is exploited as a regularization term to avoid overfitting of the learned representation. The effectiveness and accuracy of our proposed complex-valued fully convolutional network (CV-FCN) based interference mitigation approach are verified and analyzed through both simulated and measured radar signals. Compared to the real-valued counterparts, the CV-FCN shows a better interference mitigation performance with a potential of half memory reduction in low Signal to Interference plus Noise Ratio (SINR) scenarios. Moreover, the CV-FCN trained using only simulated data can be directly utilized for interference mitigation in various measured radar signals and shows a superior generalization capability. Furthermore, by incorporating the prior feature, the CV-FCN trained on only 1/8 of the full data achieves comparable performance as that on the full dataset in low SINR scenarios, and the training procedure converges faster.
AdvDrop: Adversarial Attack to DNNs by Dropping Information
Aug 20, 2021


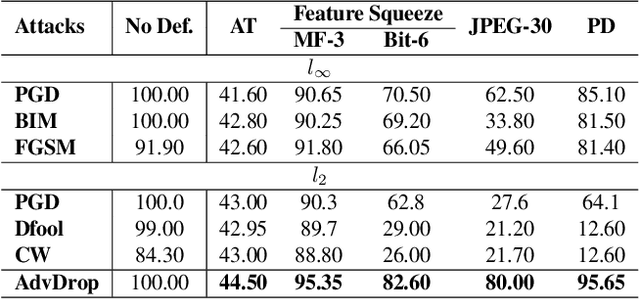
Human can easily recognize visual objects with lost information: even losing most details with only contour reserved, e.g. cartoon. However, in terms of visual perception of Deep Neural Networks (DNNs), the ability for recognizing abstract objects (visual objects with lost information) is still a challenge. In this work, we investigate this issue from an adversarial viewpoint: will the performance of DNNs decrease even for the images only losing a little information? Towards this end, we propose a novel adversarial attack, named \textit{AdvDrop}, which crafts adversarial examples by dropping existing information of images. Previously, most adversarial attacks add extra disturbing information on clean images explicitly. Opposite to previous works, our proposed work explores the adversarial robustness of DNN models in a novel perspective by dropping imperceptible details to craft adversarial examples. We demonstrate the effectiveness of \textit{AdvDrop} by extensive experiments, and show that this new type of adversarial examples is more difficult to be defended by current defense systems.
DRDF: Determining the Importance of Different Multimodal Information with Dual-Router Dynamic Framework
Jul 21, 2021

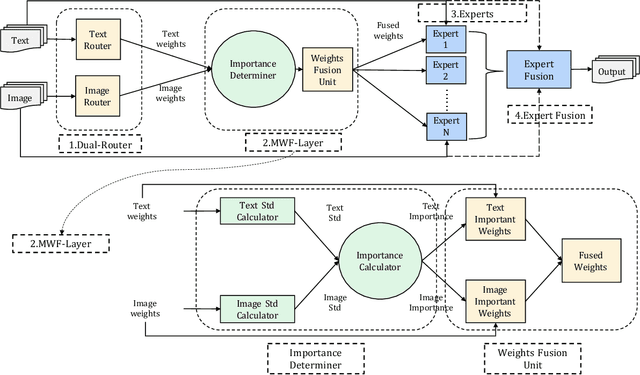
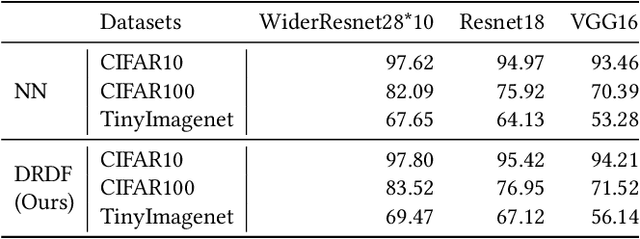
In multimodal tasks, we find that the importance of text and image modal information is different for different input cases, and for this motivation, we propose a high-performance and highly general Dual-Router Dynamic Framework (DRDF), consisting of Dual-Router, MWF-Layer, experts and expert fusion unit. The text router and image router in Dual-Router accept text modal information and image modal information, and use MWF-Layer to determine the importance of modal information. Based on the result of the determination, MWF-Layer generates fused weights for the fusion of experts. Experts are model backbones that match the current task. DRDF has high performance and high generality, and we have tested 12 backbones such as Visual BERT on multimodal dataset Hateful memes, unimodal dataset CIFAR10, CIFAR100, and TinyImagenet. Our DRDF outperforms all the baselines. We also verified the components of DRDF in detail by ablations, compared and discussed the reasons and ideas of DRDF design.
RAMS-Trans: Recurrent Attention Multi-scale Transformer forFine-grained Image Recognition
Jul 17, 2021
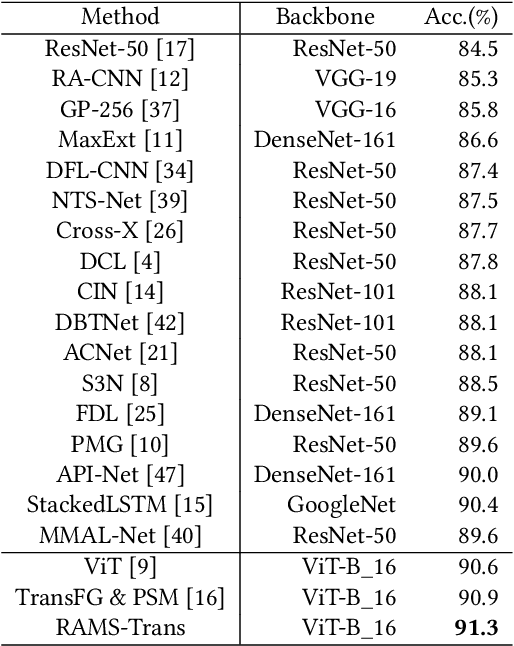
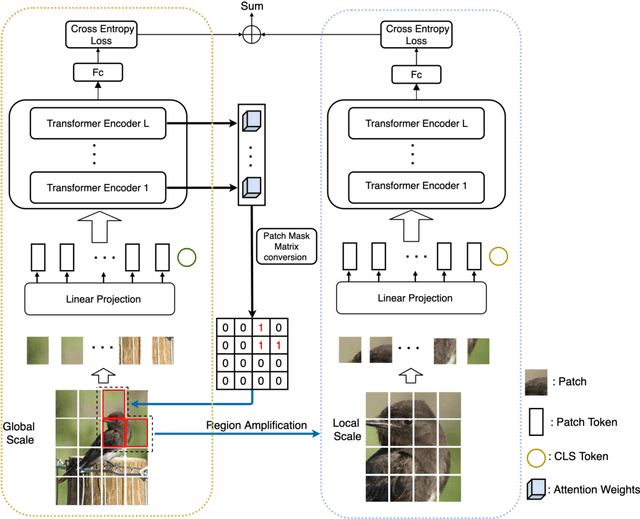
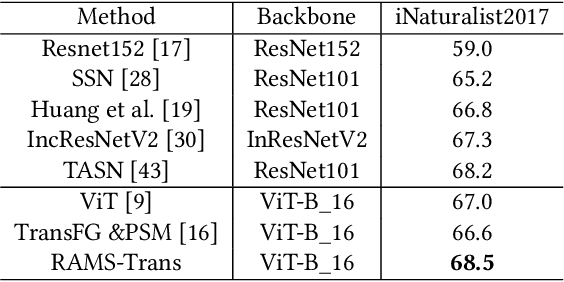
In fine-grained image recognition (FGIR), the localization and amplification of region attention is an important factor, which has been explored a lot by convolutional neural networks (CNNs) based approaches. The recently developed vision transformer (ViT) has achieved promising results on computer vision tasks. Compared with CNNs, Image sequentialization is a brand new manner. However, ViT is limited in its receptive field size and thus lacks local attention like CNNs due to the fixed size of its patches, and is unable to generate multi-scale features to learn discriminative region attention. To facilitate the learning of discriminative region attention without box/part annotations, we use the strength of the attention weights to measure the importance of the patch tokens corresponding to the raw images. We propose the recurrent attention multi-scale transformer (RAMS-Trans), which uses the transformer's self-attention to recursively learn discriminative region attention in a multi-scale manner. Specifically, at the core of our approach lies the dynamic patch proposal module (DPPM) guided region amplification to complete the integration of multi-scale image patches. The DPPM starts with the full-size image patches and iteratively scales up the region attention to generate new patches from global to local by the intensity of the attention weights generated at each scale as an indicator. Our approach requires only the attention weights that come with ViT itself and can be easily trained end-to-end. Extensive experiments demonstrate that RAMS-Trans performs better than concurrent works, in addition to efficient CNN models, achieving state-of-the-art results on three benchmark datasets.
Monocular 3D Object Detection: An Extrinsic Parameter Free Approach
Jun 30, 2021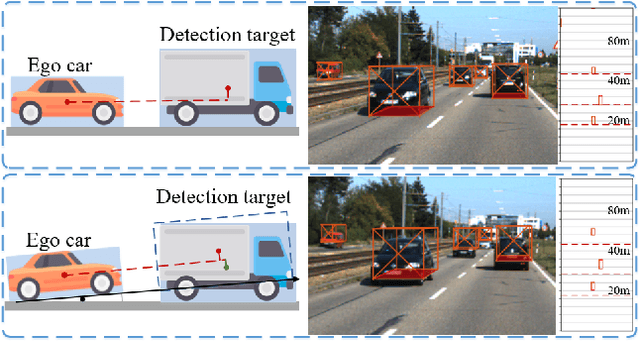
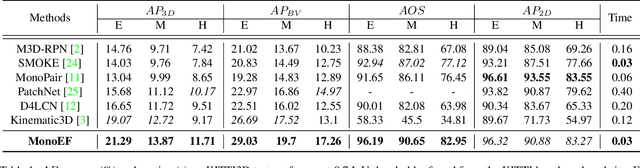
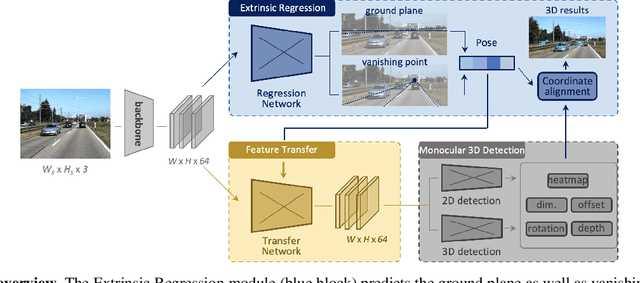
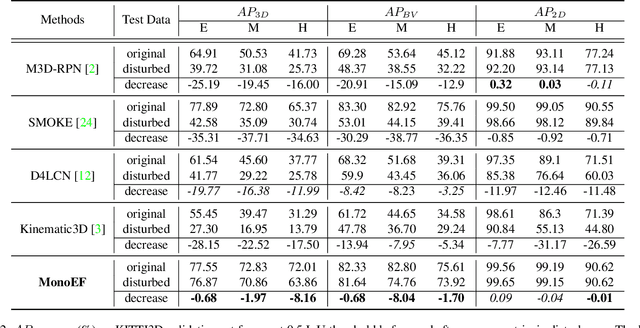
Monocular 3D object detection is an important task in autonomous driving. It can be easily intractable where there exists ego-car pose change w.r.t. ground plane. This is common due to the slight fluctuation of road smoothness and slope. Due to the lack of insight in industrial application, existing methods on open datasets neglect the camera pose information, which inevitably results in the detector being susceptible to camera extrinsic parameters. The perturbation of objects is very popular in most autonomous driving cases for industrial products. To this end, we propose a novel method to capture camera pose to formulate the detector free from extrinsic perturbation. Specifically, the proposed framework predicts camera extrinsic parameters by detecting vanishing point and horizon change. A converter is designed to rectify perturbative features in the latent space. By doing so, our 3D detector works independent of the extrinsic parameter variations and produces accurate results in realistic cases, e.g., potholed and uneven roads, where almost all existing monocular detectors fail to handle. Experiments demonstrate our method yields the best performance compared with the other state-of-the-arts by a large margin on both KITTI 3D and nuScenes datasets.
Towards Robust Vision Transformer
May 26, 2021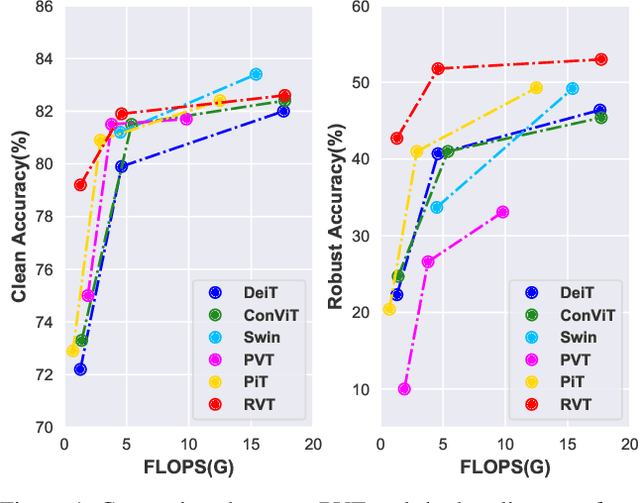
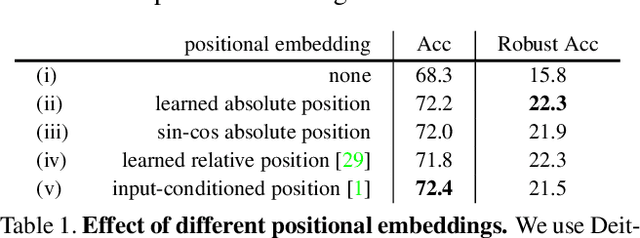
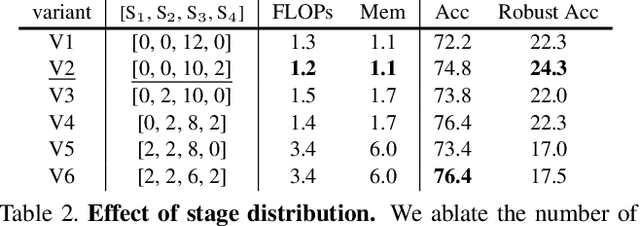
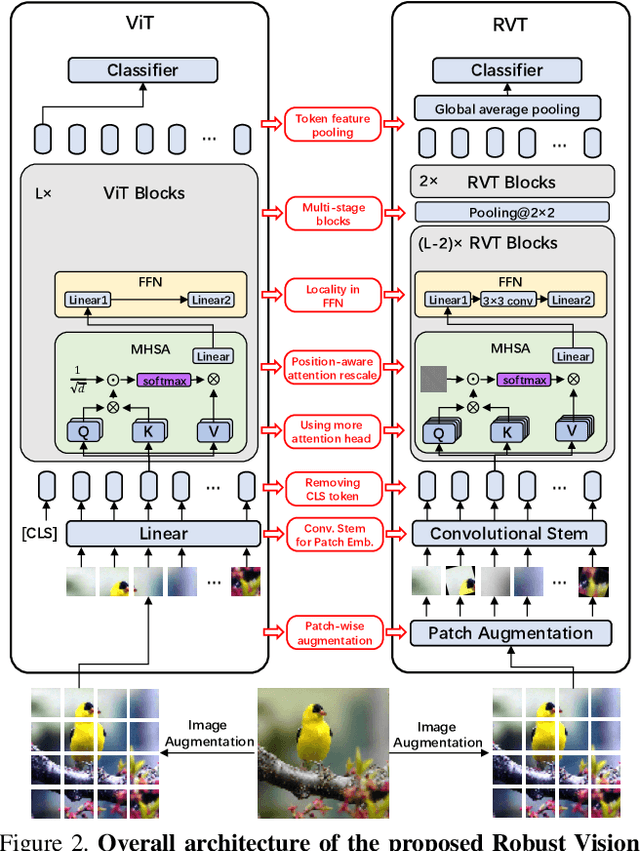
Recent advances on Vision Transformer (ViT) and its improved variants have shown that self-attention-based networks surpass traditional Convolutional Neural Networks (CNNs) in most vision tasks. However, existing ViTs focus on the standard accuracy and computation cost, lacking the investigation of the intrinsic influence on model robustness and generalization. In this work, we conduct systematic evaluation on components of ViTs in terms of their impact on robustness to adversarial examples, common corruptions and distribution shifts. We find some components can be harmful to robustness. By using and combining robust components as building blocks of ViTs, we propose Robust Vision Transformer (RVT), which is a new vision transformer and has superior performance with strong robustness. We further propose two new plug-and-play techniques called position-aware attention scaling and patch-wise augmentation to augment our RVT, which we abbreviate as RVT*. The experimental results on ImageNet and six robustness benchmarks show the advanced robustness and generalization ability of RVT compared with previous ViTs and state-of-the-art CNNs. Furthermore, RVT-S* also achieves Top-1 rank on multiple robustness leaderboards including ImageNet-C and ImageNet-Sketch. The code will be available at \url{https://git.io/Jswdk}.
Fine-Grained Fashion Similarity Prediction by Attribute-Specific Embedding Learning
Apr 06, 2021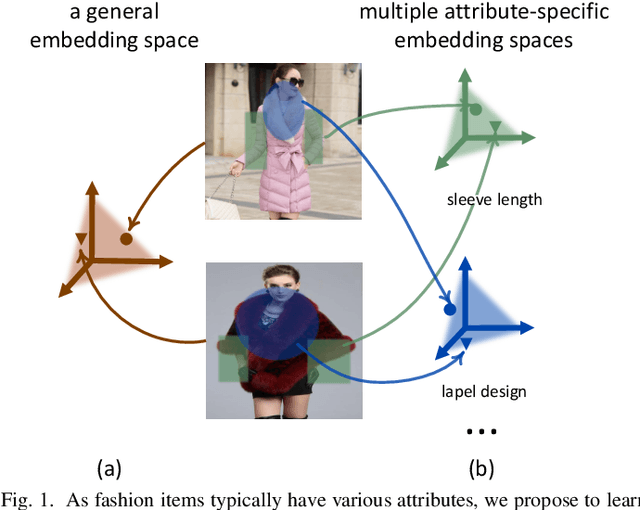
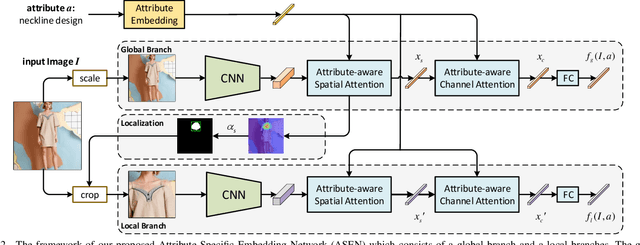
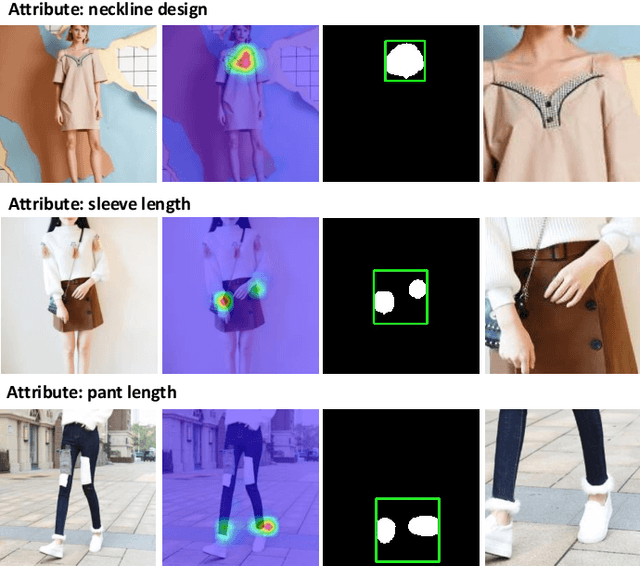

This paper strives to predict fine-grained fashion similarity. In this similarity paradigm, one should pay more attention to the similarity in terms of a specific design/attribute between fashion items. For example, whether the collar designs of the two clothes are similar. It has potential value in many fashion related applications, such as fashion copyright protection. To this end, we propose an Attribute-Specific Embedding Network (ASEN) to jointly learn multiple attribute-specific embeddings, thus measure the fine-grained similarity in the corresponding space. The proposed ASEN is comprised of a global branch and a local branch. The global branch takes the whole image as input to extract features from a global perspective, while the local branch takes as input the zoomed-in region-of-interest (RoI) w.r.t. the specified attribute thus able to extract more fine-grained features. As the global branch and the local branch extract the features from different perspectives, they are complementary to each other. Additionally, in each branch, two attention modules, i.e., Attribute-aware Spatial Attention and Attribute-aware Channel Attention, are integrated to make ASEN be able to locate the related regions and capture the essential patterns under the guidance of the specified attribute, thus make the learned attribute-specific embeddings better reflect the fine-grained similarity. Extensive experiments on three fashion-related datasets, i.e., FashionAI, DARN, and DeepFashion, show the effectiveness of ASEN for fine-grained fashion similarity prediction and its potential for fashion reranking. Code and data are available at https://github.com/maryeon/asenpp .