 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Video Object Segmentation With Temporal Aggregation Network and Dynamic Template Matching
Jul 11, 2020
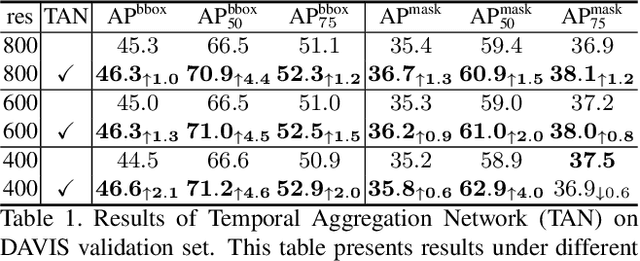
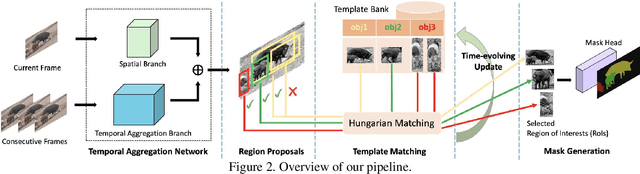
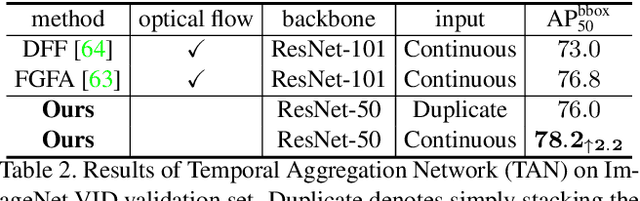
Significant progress has been made in Video Object Segmentation (VOS), the video object tracking task in its finest level. While the VOS task can be naturally decoupled into image semantic segmentation and video object tracking, significantly much more research effort has been made in segmentation than tracking. In this paper, we introduce "tracking-by-detection" into VOS which can coherently integrate segmentation into tracking, by proposing a new temporal aggregation network and a novel dynamic time-evolving template matching mechanism to achieve significantly improved performance. Notably, our method is entirely online and thus suitable for one-shot learning, and our end-to-end trainable model allows multiple object segmentation in one forward pass. We achieve new state-of-the-art performance on the DAVIS benchmark without complicated bells and whistles in both speed and accuracy, with a speed of 0.14 second per frame and J&F measure of 75.9% respectively.
Cascaded deep monocular 3D human pose estimation with evolutionary training data
Jun 14, 2020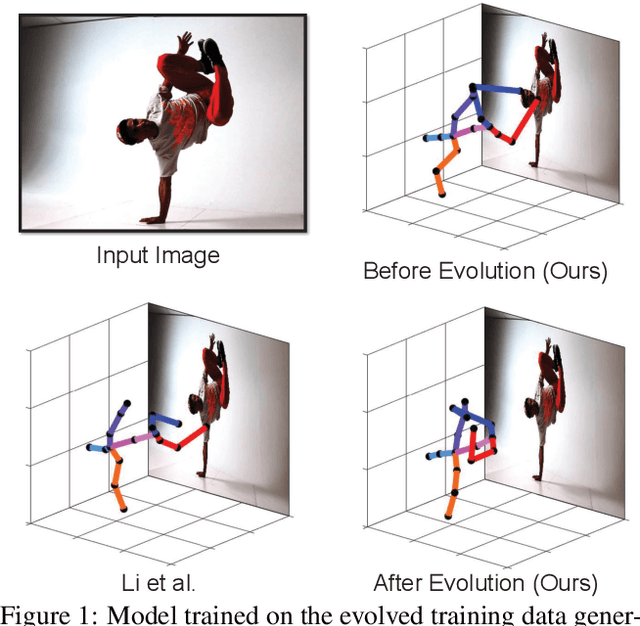
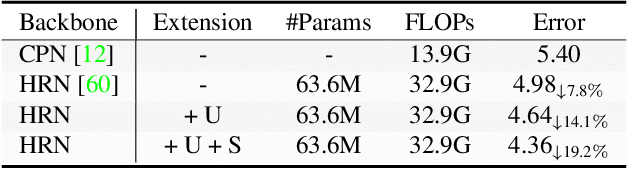
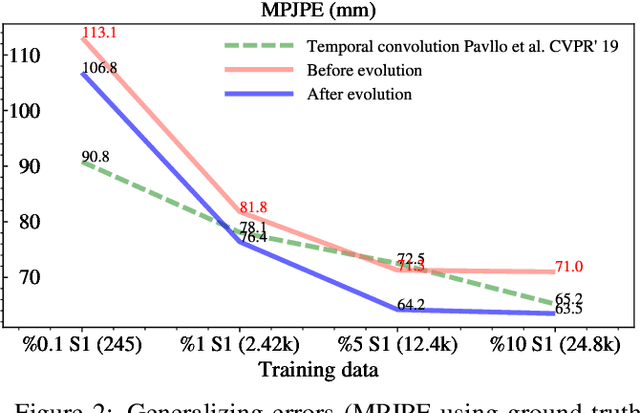
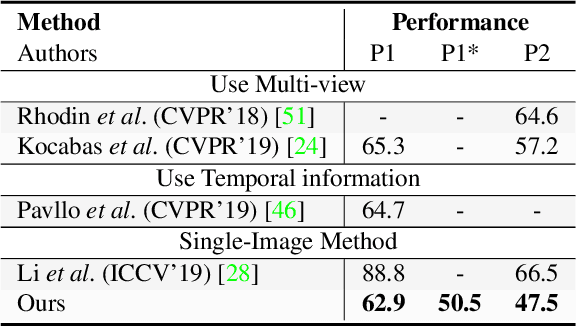
End-to-end deep representation learning has achieved remarkable accuracy for monocular 3D human pose estimation, yet these models may fail for unseen poses with limited and fixed training data. This paper proposes a novel data augmentation method that: (1) is scalable for synthesizing massive amount of training data (over 8 million valid 3D human poses with corresponding 2D projections) for training 2D-to-3D networks, (2) can effectively reduce dataset bias. Our method evolves a limited dataset to synthesize unseen 3D human skeletons based on a hierarchical human representation and heuristics inspired by prior knowledge. Extensive experiments show that our approach not only achieves state-of-the-art accuracy on the largest public benchmark, but also generalizes significantly better to unseen and rare poses. Relevant files and tools are available at the project website.
One-Shot Object Detection without Fine-Tuning
May 08, 2020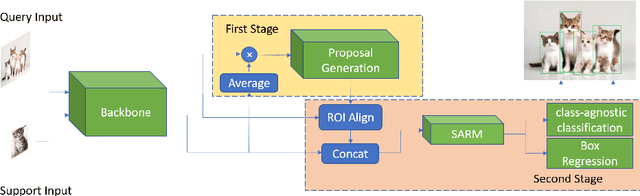
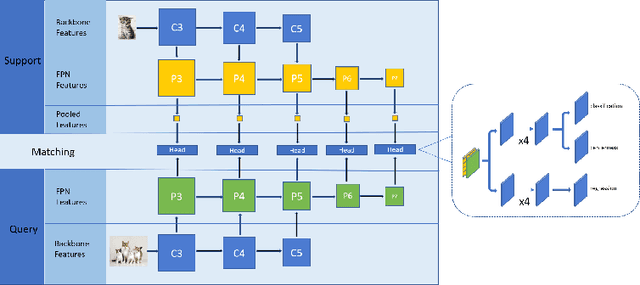
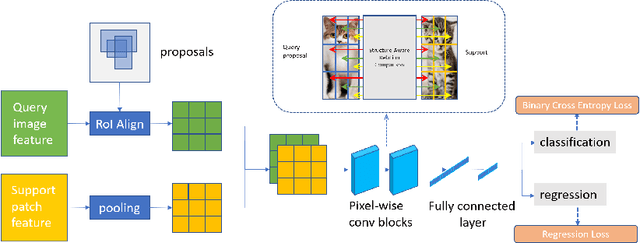
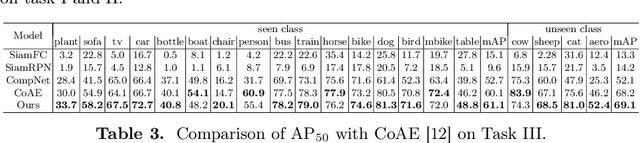
Deep learning has revolutionized object detection thanks to large-scale datasets, but their object categories are still arguably very limited. In this paper, we attempt to enrich such categories by addressing the one-shot object detection problem, where the number of annotated training examples for learning an unseen class is limited to one. We introduce a two-stage model consisting of a first stage Matching-FCOS network and a second stage Structure-Aware Relation Module, the combination of which integrates metric learning with an anchor-free Faster R-CNN-style detection pipeline, eventually eliminating the need to fine-tune on the support images. We also propose novel training strategies that effectively improve detection performance. Extensive quantitative and qualitative evaluations were performed and our method exceeds the state-of-the-art one-shot performance consistently on multiple datasets.
CascadePSP: Toward Class-Agnostic and Very High-Resolution Segmentation via Global and Local Refinement
May 06, 2020
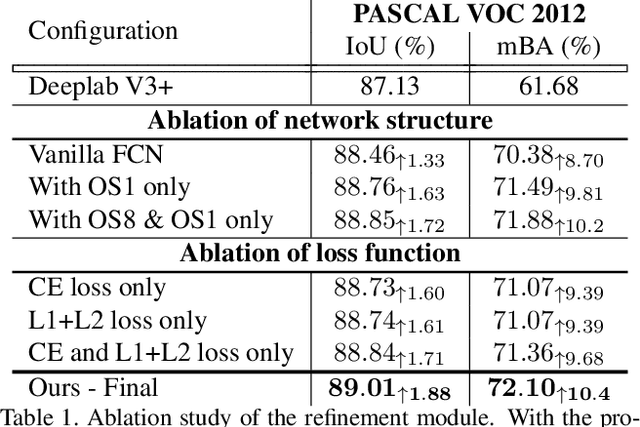
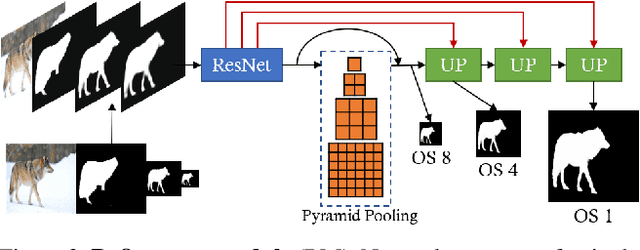
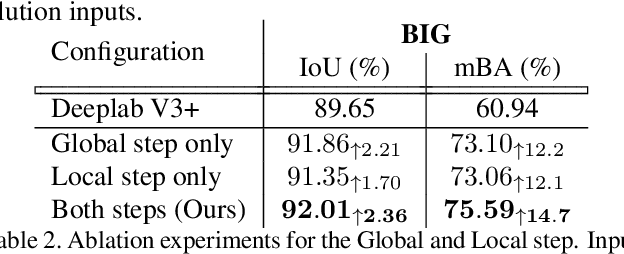
State-of-the-art semantic segmentation methods were almost exclusively trained on images within a fixed resolution range. These segmentations are inaccurate for very high-resolution images since using bicubic upsampling of low-resolution segmentation does not adequately capture high-resolution details along object boundaries. In this paper, we propose a novel approach to address the high-resolution segmentation problem without using any high-resolution training data. The key insight is our CascadePSP network which refines and corrects local boundaries whenever possible. Although our network is trained with low-resolution segmentation data, our method is applicable to any resolution even for very high-resolution images larger than 4K. We present quantitative and qualitative studies on different datasets to show that CascadePSP can reveal pixel-accurate segmentation boundaries using our novel refinement module without any finetuning. Thus, our method can be regarded as class-agnostic. Finally, we demonstrate the application of our model to scene parsing in multi-class segmentation.
Learning Video Object Segmentation from Unlabeled Videos
Mar 10, 2020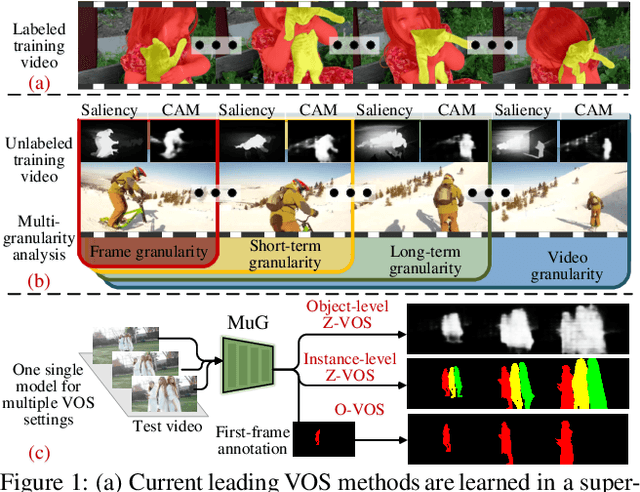
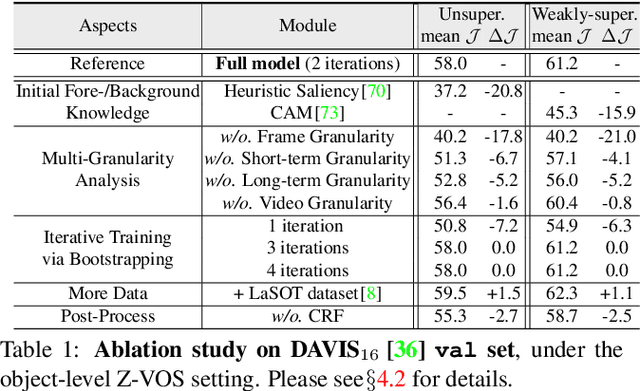
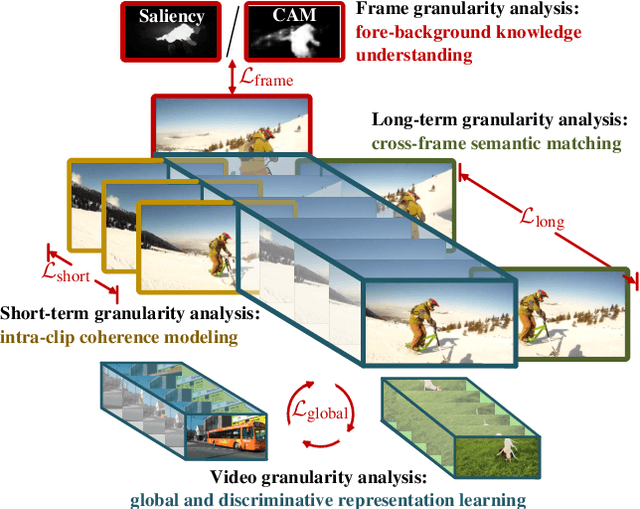

We propose a new method for video object segmentation (VOS) that addresses object pattern learning from unlabeled videos, unlike most existing methods which rely heavily on extensive annotated data. We introduce a unified unsupervised/weakly supervised learning framework, called MuG, that comprehensively captures intrinsic properties of VOS at multiple granularities. Our approach can help advance understanding of visual patterns in VOS and significantly reduce annotation burden. With a carefully-designed architecture and strong representation learning ability, our learned model can be applied to diverse VOS settings, including object-level zero-shot VOS, instance-level zero-shot VOS, and one-shot VOS. Experiments demonstrate promising performance in these settings, as well as the potential of MuG in leveraging unlabeled data to further improve the segmentation accuracy.
Spatial-Scale Aligned Network for Fine-Grained Recognition
Jan 05, 2020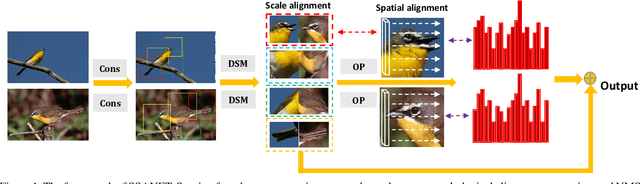


Existing approaches for fine-grained visual recognition focus on learning marginal region-based representations while neglecting the spatial and scale misalignments, leading to inferior performance. In this paper, we propose the spatial-scale aligned network (SSANET) and implicitly address misalignments during the recognition process. Especially, SSANET consists of 1) a self-supervised proposal mining formula with Morphological Alignment Constraints; 2) a discriminative scale mining (DSM) module, which exploits the feature pyramid via a circulant matrix, and provides the Fourier solver for fast scale alignments; 3) an oriented pooling (OP) module, that performs the pooling operation in several pre-defined orientations. Each orientation defines one kind of spatial alignment, and the network automatically determines which is the optimal alignments through learning. With the proposed two modules, our algorithm can automatically determine the accurate local proposal regions and generate more robust target representations being invariant to various appearance variances. Extensive experiments verify that SSANET is competent at learning better spatial-scale invariant target representations, yielding superior performance on the fine-grained recognition task on several benchmarks.
Pyramid Multi-view Stereo Net with Self-adaptive View Aggregation
Dec 06, 2019
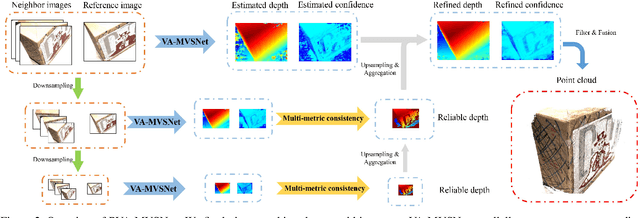
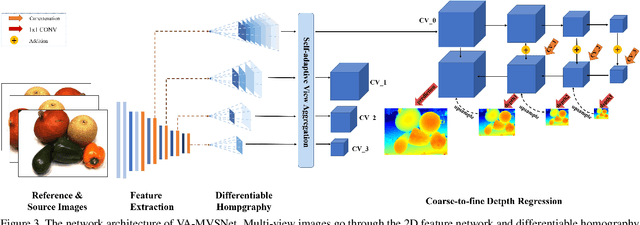
In this paper, we propose an effective and efficient pyramid multi-view stereo (MVS) net for accurate and complete dense point cloud reconstruction. Different from existing deep-learning based MVS methods, our VA-MVSNet incorporates the cost variance between different views by introducing two novel self-adaptive view aggregation: pixel-wise view aggregation and voxel-wise view aggregation. Moreover, to enhance the point cloud reconstruction on the texture-less regions, we extend VA-MVSNet with pyramid multi-scale images input as PVA-MVSNet, where multi-metric constraints are leveraged to aggregate the reliable depth estimation at the coarser scale to fill-in the mismatched regions at the finer scale. Experimental results show that our approach establishes a new state-of-the-art on the DTU dataset with significant improvements in the completeness and overall quality of 3D reconstruction, and ranks 1st on the Tanks and Temples benchmark among all published deep-learning based methods. Our codebase is available at https://github.com/yhw-yhw/PVAMVSNet.
Reflective Decoding Network for Image Captioning
Aug 30, 2019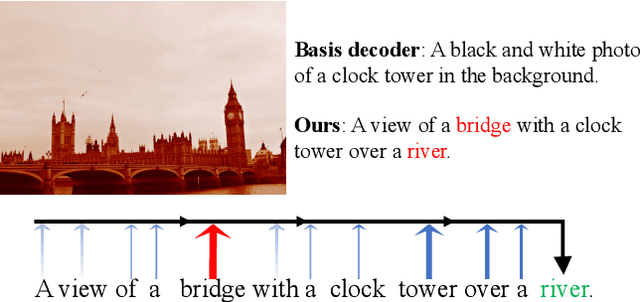

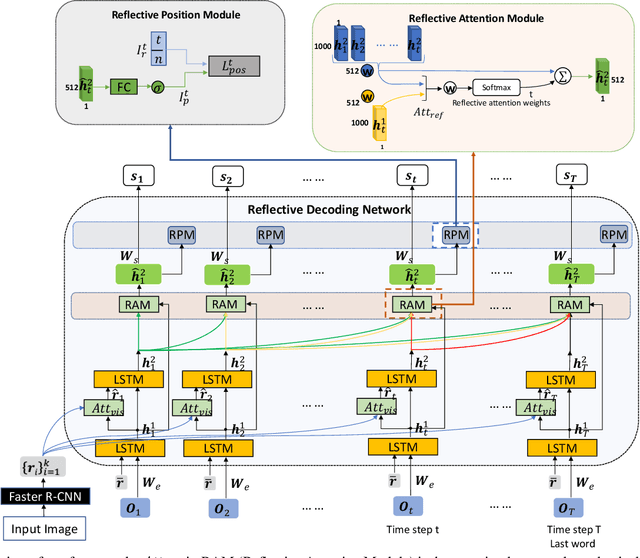
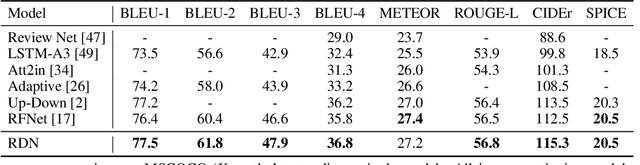
State-of-the-art image captioning methods mostly focus on improving visual features, less attention has been paid to utilizing the inherent properties of language to boost captioning performance. In this paper, we show that vocabulary coherence between words and syntactic paradigm of sentences are also important to generate high-quality image caption. Following the conventional encoder-decoder framework, we propose the Reflective Decoding Network (RDN) for image captioning, which enhances both the long-sequence dependency and position perception of words in a caption decoder. Our model learns to collaboratively attend on both visual and textual features and meanwhile perceive each word's relative position in the sentence to maximize the information delivered in the generated caption. We evaluate the effectiveness of our RDN on the COCO image captioning datasets and achieve superior performance over the previous methods. Further experiments reveal that our approach is particularly advantageous for hard cases with complex scenes to describe by captions.
Orthogonal Center Learning with Subspace Masking for Person Re-Identification
Aug 28, 2019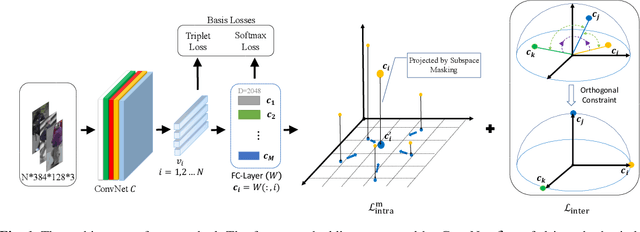
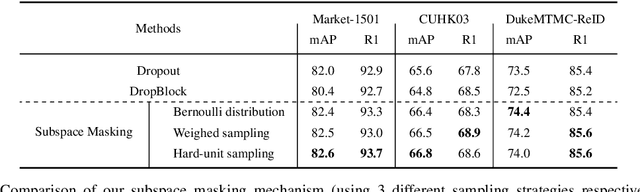
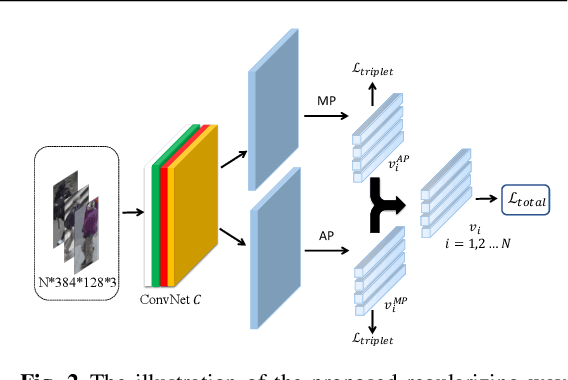
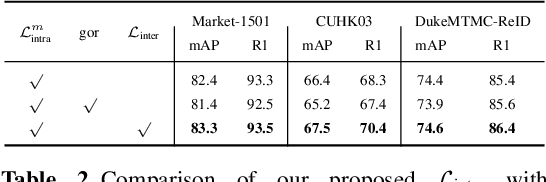
Person re-identification aims to identify whether pairs of images belong to the same person or not. This problem is challenging due to large differences in camera views, lighting and background. One of the mainstream in learning CNN features is to design loss functions which reinforce both the class separation and intra-class compactness. In this paper, we propose a novel Orthogonal Center Learning method with Subspace Masking for person re-identification. We make the following contributions: (i) we develop a center learning module to learn the class centers by simultaneously reducing the intra-class differences and inter-class correlations by orthogonalization; (ii) we introduce a subspace masking mechanism to enhance the generalization of the learned class centers; and (iii) we devise to integrate the average pooling and max pooling in a regularizing manner that fully exploits their powers. Extensive experiments show that our proposed method consistently outperforms the state-of-the-art methods on the large-scale ReID datasets including Market-1501, DukeMTMC-ReID, CUHK03 and MSMT17.
Non-local Recurrent Neural Memory for Supervised Sequence Modeling
Aug 26, 2019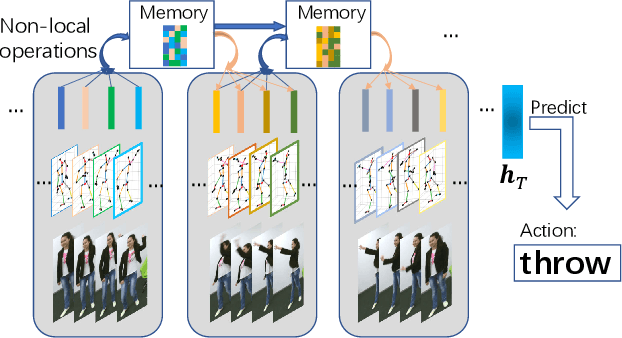
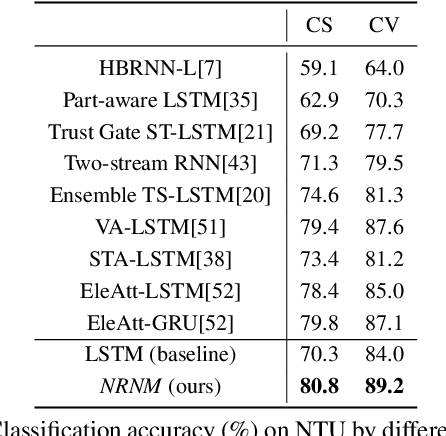
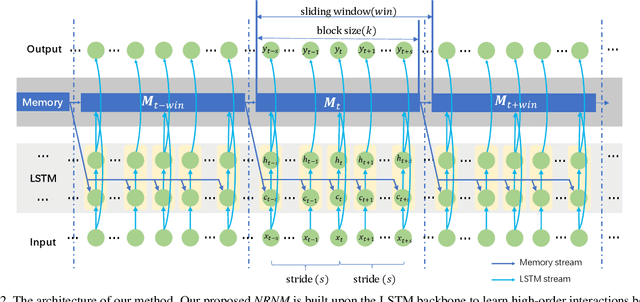
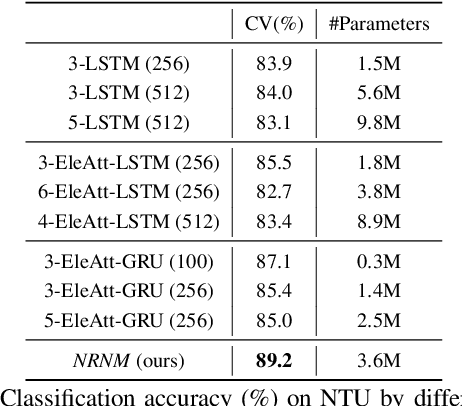
Typical methods for supervised sequence modeling are built upon the recurrent neural networks to capture temporal dependencies. One potential limitation of these methods is that they only model explicitly information interactions between adjacent time steps in a sequence, hence the high-order interactions between nonadjacent time steps are not fully exploited. It greatly limits the capability of modeling the long-range temporal dependencies since one-order interactions cannot be maintained for a long term due to information dilution and gradient vanishing. To tackle this limitation, we propose the Non-local Recurrent Neural Memory (NRNM) for supervised sequence modeling, which performs non-local operations to learn full-order interactions within a sliding temporal block and models global interactions between blocks in a gated recurrent manner. Consequently, our model is able to capture the long-range dependencies. Besides, the latent high-level features contained in high-order interactions can be distilled by our model. We demonstrate the merits of our NRNM on two different tasks: action recognition and sentiment analysis.