 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUGAR: Learning Skeleton Representation with Visual-Motion Knowledge for Action Recognition
Nov 13, 2025Large Language Models (LLMs) hold rich implicit knowledge and powerful transferability. In this paper, we explore the combination of LLMs with the human skeleton to perform action classification and description. However, when treating LLM as a recognizer, two questions arise: 1) How can LLMs understand skeleton? 2) How can LLMs distinguish among actions? To address these problems, we introduce a novel paradigm named learning Skeleton representation with visUal-motion knowledGe for Action Recognition (SUGAR). In our pipeline, we first utilize off-the-shelf large-scale video models as a knowledge base to generate visual, motion information related to actions. Then, we propose to supervise skeleton learning through this prior knowledge to yield discrete representations. Finally, we use the LLM with untouched pre-training weights to understand these representations and generate the desired action targets and descriptions. Notably, we present a Temporal Query Projection (TQP) module to continuously model the skeleton signals with long sequences. Experiments on several skeleton-based action classification benchmarks demonstrate the efficacy of our SUGAR. Moreover, experiments on zero-shot scenarios show that SUGAR is more versatile than linear-based methods.
When Eyes and Ears Disagree: Can MLLMs Discern Audio-Visual Confusion?
Nov 13, 2025Can Multimodal Large Language Models (MLLMs) discern confused objects that are visually present but audio-absent? To study this, we introduce a new benchmark, AV-ConfuseBench, which simulates an ``Audio-Visual Confusion'' scene by modifying the corresponding sound of an object in the video, e.g., mute the sounding object and ask MLLMs Is there a/an muted-object sound''. Experimental results reveal that MLLMs, such as Qwen2.5-Omni and Gemini 2.5, struggle to discriminate non-existent audio due to visually dominated reasoning. Motivated by this observation, we introduce RL-CoMM, a Reinforcement Learning-based Collaborative Multi-MLLM that is built upon the Qwen2.5-Omni foundation. RL-CoMM includes two stages: 1) To alleviate visually dominated ambiguities, we introduce an external model, a Large Audio Language Model (LALM), as the reference model to generate audio-only reasoning. Then, we design a Step-wise Reasoning Reward function that enables MLLMs to self-improve audio-visual reasoning with the audio-only reference. 2) To ensure an accurate answer prediction, we introduce Answer-centered Confidence Optimization to reduce the uncertainty of potential heterogeneous reasoning differences. Extensive experiments on audio-visual question answering and audio-visual hallucination show that RL-CoMM improves the accuracy by 10~30\% over the baseline model with limited training data. Follow: https://github.com/rikeilong/AVConfusion.
MuSc-V2: Zero-Shot Multimodal Industrial Anomaly Classification and Segmentation with Mutual Scoring of Unlabeled Samples
Nov 13, 2025Zero-shot anomaly classification (AC) and segmentation (AS) methods aim to identify and outline defects without using any labeled samples. In this paper, we reveal a key property that is overlooked by existing methods: normal image patches across industrial products typically find many other similar patches, not only in 2D appearance but also in 3D shapes, while anomalies remain diverse and isolated. To explicitly leverage this discriminative property, we propose a Mutual Scoring framework (MuSc-V2) for zero-shot AC/AS, which flexibly supports single 2D/3D or multimodality. Specifically, our method begins by improving 3D representation through Iterative Point Grouping (IPG), which reduces false positives from discontinuous surfaces. Then we use Similarity Neighborhood Aggregation with Multi-Degrees (SNAMD) to fuse 2D/3D neighborhood cues into more discriminative multi-scale patch features for mutual scoring. The core comprises a Mutual Scoring Mechanism (MSM) that lets samples within each modality to assign score to each other, and Cross-modal Anomaly Enhancement (CAE) that fuses 2D and 3D scores to recover modality-specific missing anomalies. Finally, Re-scoring with Constrained Neighborhood (RsCon) suppresses false classification based on similarity to more representative samples. Our framework flexibly works on both the full dataset and smaller subsets with consistently robust performance, ensuring seamless adaptability across diverse product lines. In aid of the novel framework, MuSc-V2 achieves significant performance improvements: a $\textbf{+23.7\%}$ AP gain on the MVTec 3D-AD dataset and a $\textbf{+19.3\%}$ boost on the Eyecandies dataset, surpassing previous zero-shot benchmarks and even outperforming most few-shot methods. The code will be available at The code will be available at \href{https://github.com/HUST-SLOW/MuSc-V2}{https://github.com/HUST-SLOW/MuSc-V2}.
Task-Aware 3D Affordance Segmentation via 2D Guidance and Geometric Refinement
Nov 12, 2025Understanding 3D scene-level affordances from natural language instructions is essential for enabling embodied agents to interact meaningfully in complex environments. However, this task remains challenging due to the need for semantic reasoning and spatial grounding. Existing methods mainly focus on object-level affordances or merely lift 2D predictions to 3D, neglecting rich geometric structure information in point clouds and incurring high computational costs. To address these limitations, we introduce Task-Aware 3D Scene-level Affordance segmentation (TASA), a novel geometry-optimized framework that jointly leverages 2D semantic cues and 3D geometric reasoning in a coarse-to-fine manner. To improve the affordance detection efficiency, TASA features a task-aware 2D affordance detection module to identify manipulable points from language and visual inputs, guiding the selection of task-relevant views. To fully exploit 3D geometric information, a 3D affordance refinement module is proposed to integrate 2D semantic priors with local 3D geometry, resulting in accurate and spatially coherent 3D affordance masks. Experiments on SceneFun3D demonstrate that TASA significantly outperforms the baselines in both accuracy and efficiency in scene-level affordance segmentation.
An Active Learning Pipeline for Biomedical Image Instance Segmentation with Minimal Human Intervention
Nov 06, 2025Biomedical image segmentation is critical for precise structure delineation and downstream analysis. Traditional methods often struggle with noisy data, while deep learning models such as U-Net have set new benchmarks in segmentation performance. nnU-Net further automates model configuration, making it adaptable across datasets without extensive tuning. However, it requires a substantial amount of annotated data for cross-validation, posing a challenge when only raw images but no labels are available. Large foundation models offer zero-shot generalizability, but may underperform on specific datasets with unique characteristics, limiting their direct use for analysis. This work addresses these bottlenecks by proposing a data-centric AI workflow that leverages active learning and pseudo-labeling to combine the strengths of traditional neural networks and large foundation models while minimizing human intervention. The pipeline starts by generating pseudo-labels from a foundation model, which are then used for nnU-Net's self-configuration. Subsequently, a representative core-set is selected for minimal manual annotation, enabling effective fine-tuning of the nnU-Net model. This approach significantly reduces the need for manual annotations while maintaining competitive performance, providing an accessible solution for biomedical researchers to apply state-of-the-art AI techniques in their segmentation tasks. The code is available at https://github.com/MMV-Lab/AL_BioMed_img_seg.
* 6 pages, 4 figures, presented at Bildverarbeitung f\"ur die Medizin (BVM) 2025, Wiesbaden, Germany
DialectGen: Benchmarking and Improving Dialect Robustness in Multimodal Generation
Oct 16, 2025

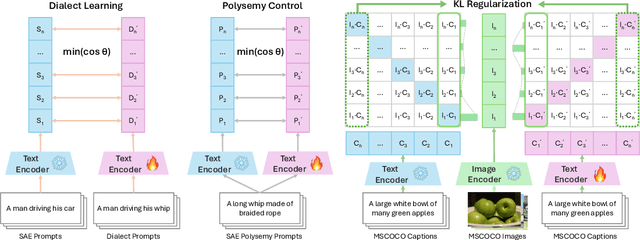

Contact languages like English exhibit rich regional variations in the form of dialects, which are often used by dialect speakers interacting with generative models. However, can multimodal generative models effectively produce content given dialectal textual input? In this work, we study this question by constructing a new large-scale benchmark spanning six common English dialects. We work with dialect speakers to collect and verify over 4200 unique prompts and evaluate on 17 image and video generative models. Our automatic and human evaluation results show that current state-of-the-art multimodal generative models exhibit 32.26% to 48.17% performance degradation when a single dialect word is used in the prompt. Common mitigation methods such as fine-tuning and prompt rewriting can only improve dialect performance by small margins (< 7%), while potentially incurring significant performance degradation in Standard American English (SAE). To this end, we design a general encoder-based mitigation strategy for multimodal generative models. Our method teaches the model to recognize new dialect features while preserving SAE performance. Experiments on models such as Stable Diffusion 1.5 show that our method is able to simultaneously raise performance on five dialects to be on par with SAE (+34.4%), while incurring near zero cost to SAE performance.
LLMs as Scalable, General-Purpose Simulators For Evolving Digital Agent Training
Oct 16, 2025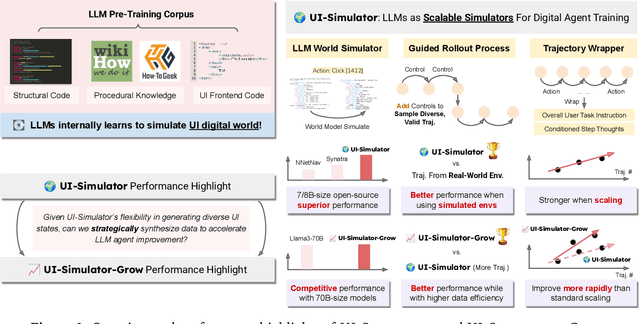
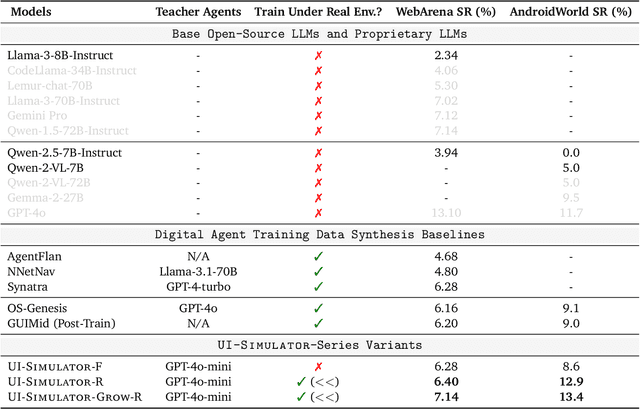

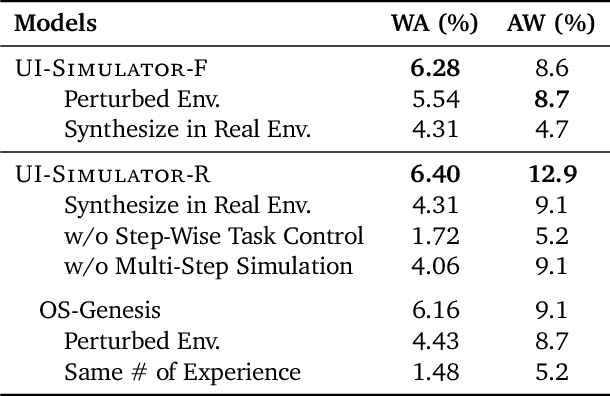
Digital agents require diverse, large-scale UI trajectories to generalize across real-world tasks, yet collecting such data is prohibitively expensive in both human annotation, infra and engineering perspectives. To this end, we introduce $\textbf{UI-Simulator}$, a scalable paradigm that generates structured UI states and transitions to synthesize training trajectories at scale. Our paradigm integrates a digital world simulator for diverse UI states, a guided rollout process for coherent exploration, and a trajectory wrapper that produces high-quality and diverse trajectories for agent training. We further propose $\textbf{UI-Simulator-Grow}$, a targeted scaling strategy that enables more rapid and data-efficient scaling by prioritizing high-impact tasks and synthesizes informative trajectory variants. Experiments on WebArena and AndroidWorld show that UI-Simulator rivals or surpasses open-source agents trained on real UIs with significantly better robustness, despite using weaker teacher models. Moreover, UI-Simulator-Grow matches the performance of Llama-3-70B-Instruct using only Llama-3-8B-Instruct as the base model, highlighting the potential of targeted synthesis scaling paradigm to continuously and efficiently enhance the digital agents.
Customizing Visual Emotion Evaluation for MLLMs: An Open-vocabulary, Multifaceted, and Scalable Approach
Sep 26, 2025Recently, Multimodal Large Language Models (MLLMs) have achieved exceptional performance across diverse tasks, continually surpassing previous expectations regarding their capabilities. Nevertheless, their proficiency in perceiving emotions from images remains debated, with studies yielding divergent results in zero-shot scenarios. We argue that this inconsistency stems partly from constraints in existing evaluation methods, including the oversight of plausible responses, limited emotional taxonomies, neglect of contextual factors, and labor-intensive annotations. To facilitate customized visual emotion evaluation for MLLMs, we propose an Emotion Statement Judgment task that overcomes these constraints. Complementing this task, we devise an automated pipeline that efficiently constructs emotion-centric statements with minimal human effort. Through systematically evaluating prevailing MLLMs, our study showcases their stronger performance in emotion interpretation and context-based emotion judgment, while revealing relative limitations in comprehending perception subjectivity. When compared to humans, even top-performing MLLMs like GPT4o demonstrate remarkable performance gaps, underscoring key areas for future improvement. By developing a fundamental evaluation framework and conducting a comprehensive MLLM assessment, we hope this work contributes to advancing emotional intelligence in MLLMs. Project page: https://github.com/wdqqdw/MVEI.
A Correction for the Paper "Symplectic geometry mode decomposition and its application to rotating machinery compound fault diagnosis"
Aug 29, 2025



The symplectic geometry mode decomposition (SGMD) is a powerful method for decomposing time series, which is based on the diagonal averaging principle (DAP) inherited from the singular spectrum analysis (SSA). Although the authors of SGMD method generalized the form of the trajectory matrix in SSA, the DAP is not updated simultaneously. In this work, we pointed out the limitations of the SGMD method and fixed the bugs with the pulling back theorem for computing the given component of time series from the corresponding component of trajectory matrix.
PathMR: Multimodal Visual Reasoning for Interpretable Pathology Diagnosis
Aug 28, 2025Deep learning based automated pathological diagnosis has markedly improved diagnostic efficiency and reduced variability between observers, yet its clinical adoption remains limited by opaque model decisions and a lack of traceable rationale. To address this, recent multimodal visual reasoning architectures provide a unified framework that generates segmentation masks at the pixel level alongside semantically aligned textual explanations. By localizing lesion regions and producing expert style diagnostic narratives, these models deliver the transparent and interpretable insights necessary for dependable AI assisted pathology. Building on these advancements, we propose PathMR, a cell-level Multimodal visual Reasoning framework for Pathological image analysis. Given a pathological image and a textual query, PathMR generates expert-level diagnostic explanations while simultaneously predicting cell distribution patterns. To benchmark its performance, we evaluated our approach on the publicly available PathGen dataset as well as on our newly developed GADVR dataset. Extensive experiments on these two datasets demonstrate that PathMR consistently outperforms state-of-the-art visual reasoning methods in text generation quality, segmentation accuracy, and cross-modal alignment. These results highlight the potential of PathMR for improving interpretability in AI-driven pathological diagnosis. The code will be publicly available in https://github.com/zhangye-zoe/PathMR.