 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformer for Graphs: An Overview from Architecture Perspective
Feb 17, 2022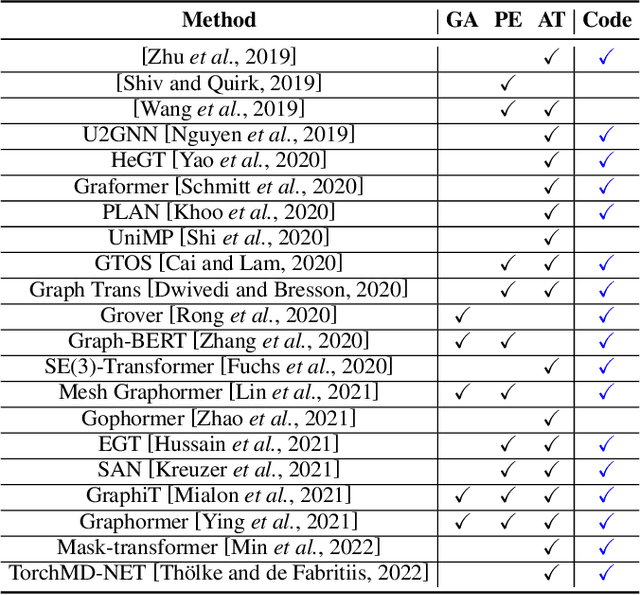
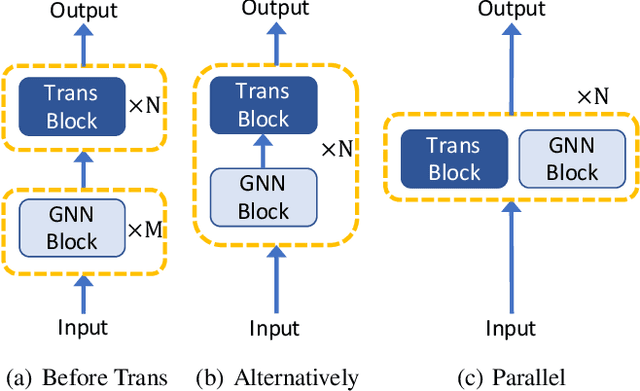
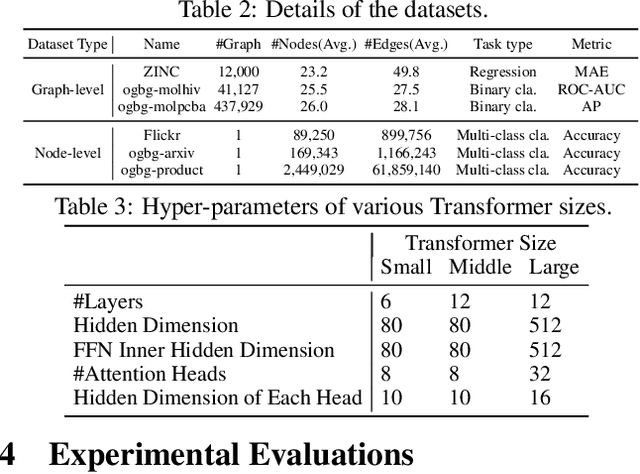
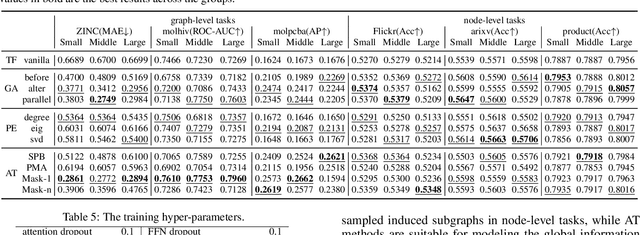
Recently, Transformer model, which has achieved great success in many artificial intelligence fields, has demonstrated its great potential in modeling graph-structured data. Till now, a great variety of Transformers has been proposed to adapt to the graph-structured data. However, a comprehensive literature review and systematical evaluation of these Transformer variants for graphs are still unavailable. It's imperative to sort out the existing Transformer models for graphs and systematically investigate their effectiveness on various graph tasks. In this survey, we provide a comprehensive review of various Graph Transformer models from the architectural design perspective. We first disassemble the existing models and conclude three typical ways to incorporate the graph information into the vanilla Transformer: 1) GNNs as Auxiliary Modules, 2) Improved Positional Embedding from Graphs, and 3) Improved Attention Matrix from Graphs. Furthermore, we implement the representative components in three groups and conduct a comprehensive comparison on various kinds of famous graph data benchmarks to investigate the real performance gain of each component. Our experiments confirm the benefits of current graph-specific modules on Transformer and reveal their advantages on different kinds of graph tasks.
Masked Transformer for Neighhourhood-aware Click-Through Rate Prediction
Jan 25, 2022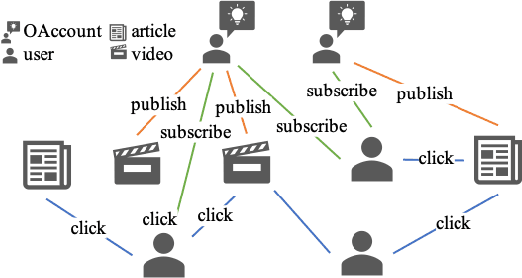
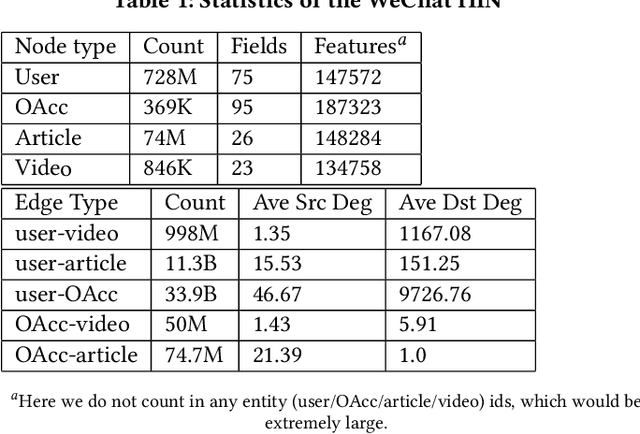
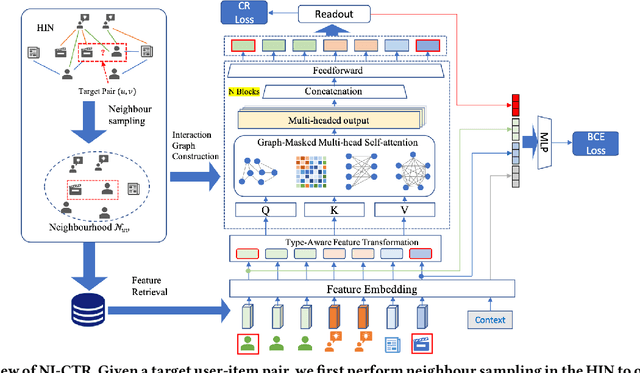
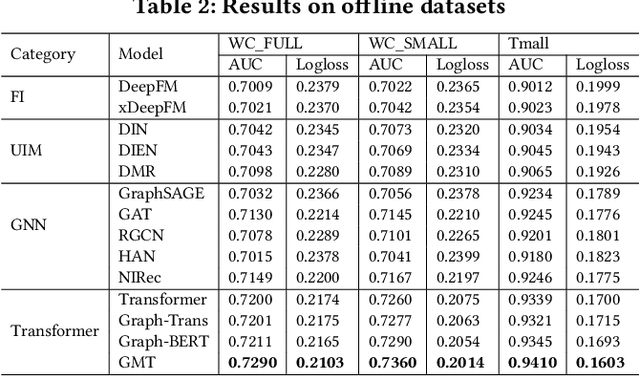
Click-Through Rate (CTR) prediction, is an essential component of online advertising. The mainstream techniques mostly focus on feature interaction or user interest modeling, which rely on users' directly interacted items. The performance of these methods are usally impeded by inactive behaviours and system's exposure, incurring that the features extracted do not contain enough information to represent all potential interests. For this sake, we propose Neighbor-Interaction based CTR prediction, which put this task into a Heterogeneous Information Network (HIN) setting, then involves local neighborhood of the target user-item pair in the HIN to predict their linkage. In order to enhance the representation of the local neighbourhood, we consider four types of topological interaction among the nodes, and propose a novel Graph-masked Transformer architecture to effectively incorporates both feature and topological information. We conduct comprehensive experiments on two real world datasets and the experimental results show that our proposed method outperforms state-of-the-art CTR models significantly.
DrugOOD: Out-of-Distribution (OOD) Dataset Curator and Benchmark for AI-aided Drug Discovery -- A Focus on Affinity Prediction Problems with Noise Annotations
Jan 24, 2022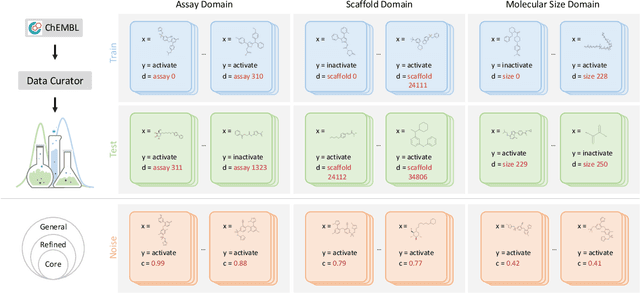

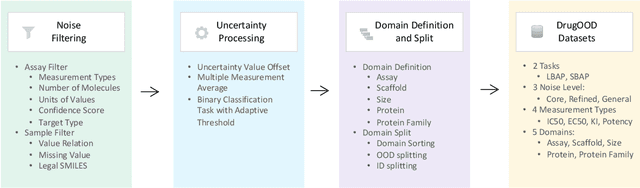
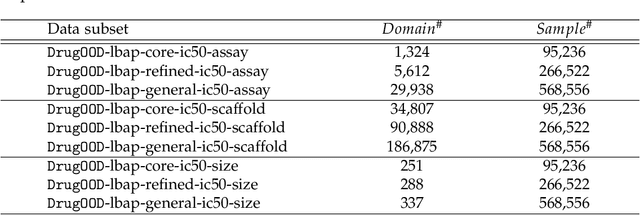
AI-aided drug discovery (AIDD) is gaining increasing popularity due to its promise of making the search for new pharmaceuticals quicker, cheaper and more efficient. In spite of its extensive use in many fields, such as ADMET prediction, virtual screening, protein folding and generative chemistry, little has been explored in terms of the out-of-distribution (OOD) learning problem with \emph{noise}, which is inevitable in real world AIDD applications. In this work, we present DrugOOD, a systematic OOD dataset curator and benchmark for AI-aided drug discovery, which comes with an open-source Python package that fully automates the data curation and OOD benchmarking processes. We focus on one of the most crucial problems in AIDD: drug target binding affinity prediction, which involves both macromolecule (protein target) and small-molecule (drug compound). In contrast to only providing fixed datasets, DrugOOD offers automated dataset curator with user-friendly customization scripts, rich domain annotations aligned with biochemistry knowledge, realistic noise annotations and rigorous benchmarking of state-of-the-art OOD algorithms. Since the molecular data is often modeled as irregular graphs using graph neural network (GNN) backbones, DrugOOD also serves as a valuable testbed for \emph{graph OOD learning} problems. Extensive empirical studies have shown a significant performance gap between in-distribution and out-of-distribution experiments, which highlights the need to develop better schemes that can allow for OOD generalization under noise for AIDD.
Graph Convolutional Module for Temporal Action Localization in Videos
Dec 01, 2021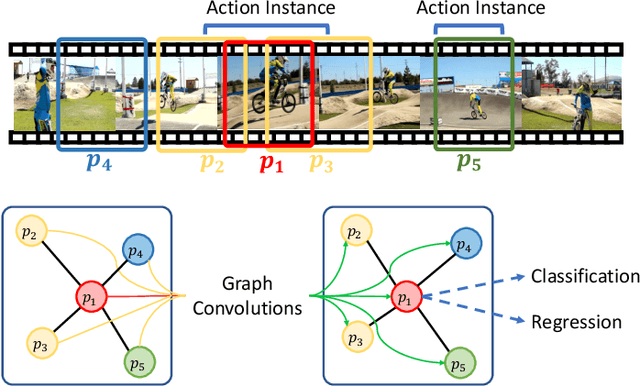
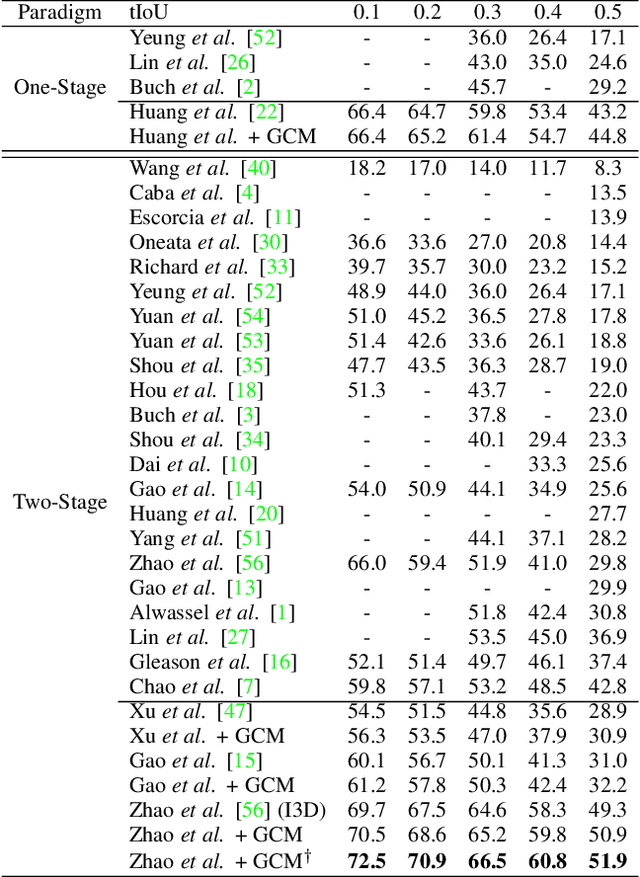
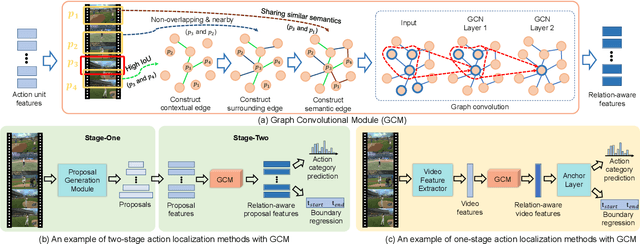
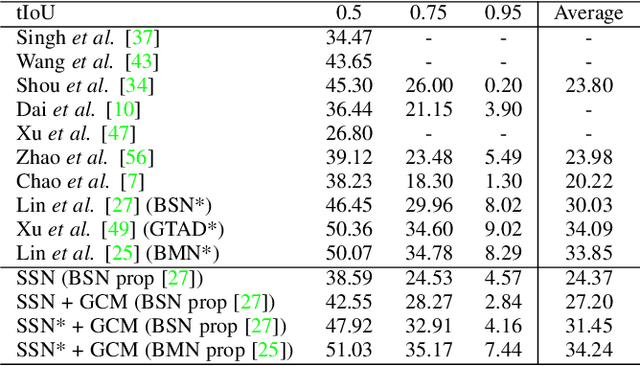
Temporal action localization has long been researched in computer vision. Existing state-of-the-art action localization methods divide each video into multiple action units (i.e., proposals in two-stage methods and segments in one-stage methods) and then perform action recognition/regression on each of them individually, without explicitly exploiting their relations during learning. In this paper, we claim that the relations between action units play an important role in action localization, and a more powerful action detector should not only capture the local content of each action unit but also allow a wider field of view on the context related to it. To this end, we propose a general graph convolutional module (GCM) that can be easily plugged into existing action localization methods, including two-stage and one-stage paradigms. To be specific, we first construct a graph, where each action unit is represented as a node and their relations between two action units as an edge. Here, we use two types of relations, one for capturing the temporal connections between different action units, and the other one for characterizing their semantic relationship. Particularly for the temporal connections in two-stage methods, we further explore two different kinds of edges, one connecting the overlapping action units and the other one connecting surrounding but disjointed units. Upon the graph we built, we then apply graph convolutional networks (GCNs) to model the relations among different action units, which is able to learn more informative representations to enhance action localization. Experimental results show that our GCM consistently improves the performance of existing action localization methods, including two-stage methods (e.g., CBR and R-C3D) and one-stage methods (e.g., D-SSAD), verifying the generality and effectiveness of our GCM.
Monocular 3D Reconstruction of Interacting Hands via Collision-Aware Factorized Refinements
Nov 01, 2021
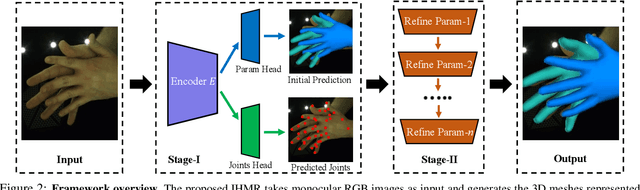
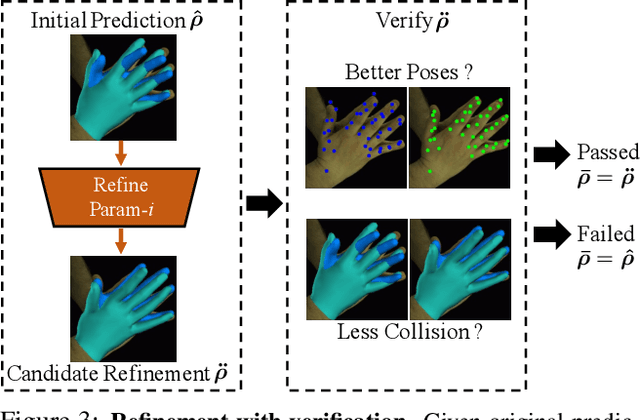
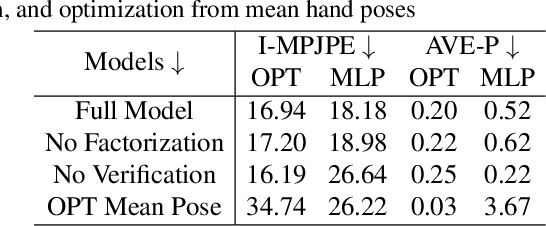
3D interacting hand reconstruction is essential to facilitate human-machine interaction and human behaviors understanding. Previous works in this field either rely on auxiliary inputs such as depth images or they can only handle a single hand if monocular single RGB images are used. Single-hand methods tend to generate collided hand meshes, when applied to closely interacting hands, since they cannot model the interactions between two hands explicitly. In this paper, we make the first attempt to reconstruct 3D interacting hands from monocular single RGB images. Our method can generate 3D hand meshes with both precise 3D poses and minimal collisions. This is made possible via a two-stage framework. Specifically, the first stage adopts a convolutional neural network to generate coarse predictions that tolerate collisions but encourage pose-accurate hand meshes. The second stage progressively ameliorates the collisions through a series of factorized refinements while retaining the preciseness of 3D poses. We carefully investigate potential implementations for the factorized refinement, considering the trade-off between efficiency and accuracy. Extensive quantitative and qualitative results on large-scale datasets such as InterHand2.6M demonstrate the effectiveness of the proposed approach.
VoteHMR: Occlusion-Aware Voting Network for Robust 3D Human Mesh Recovery from Partial Point Clouds
Oct 17, 2021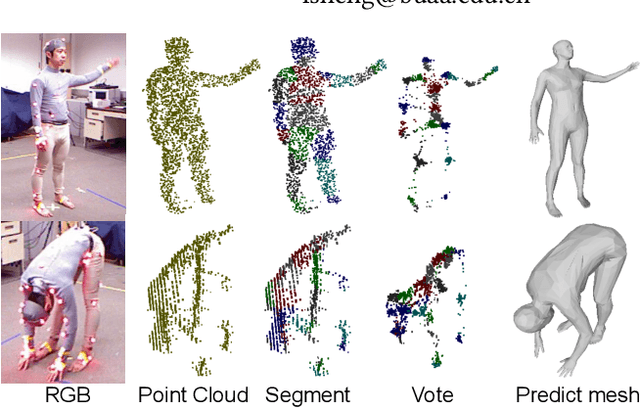
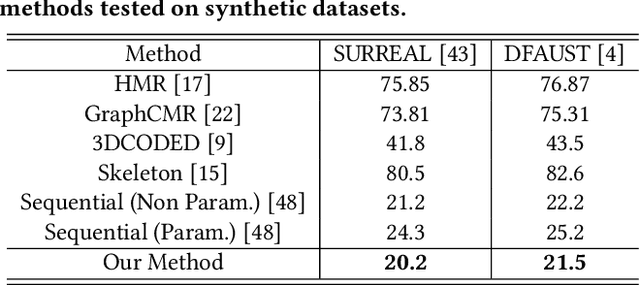
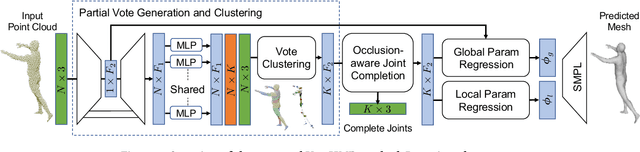
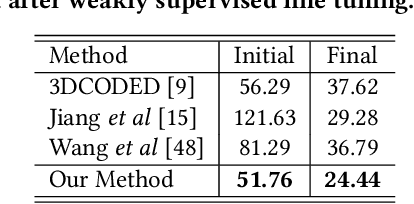
3D human mesh recovery from point clouds is essential for various tasks, including AR/VR and human behavior understanding. Previous works in this field either require high-quality 3D human scans or sequential point clouds, which cannot be easily applied to low-quality 3D scans captured by consumer-level depth sensors. In this paper, we make the first attempt to reconstruct reliable 3D human shapes from single-frame partial point clouds.To achieve this, we propose an end-to-end learnable method, named VoteHMR. The core of VoteHMR is a novel occlusion-aware voting network that can first reliably produce visible joint-level features from the input partial point clouds, and then complete the joint-level features through the kinematic tree of the human skeleton. Compared with holistic features used by previous works, the joint-level features can not only effectively encode the human geometry information but also be robust to noisy inputs with self-occlusions and missing areas. By exploiting the rich complementary clues from the joint-level features and global features from the input point clouds, the proposed method encourages reliable and disentangled parameter predictions for statistical 3D human models, such as SMPL. The proposed method achieves state-of-the-art performances on two large-scale datasets, namely SURREAL and DFAUST. Furthermore, VoteHMR also demonstrates superior generalization ability on real-world datasets, such as Berkeley MHAD.
Local Augmentation for Graph Neural Networks
Sep 08, 2021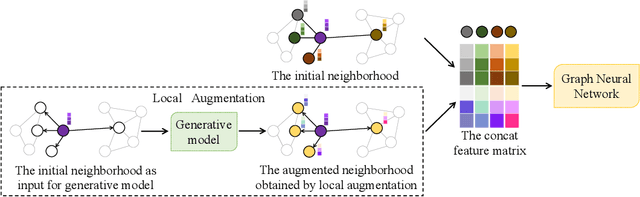
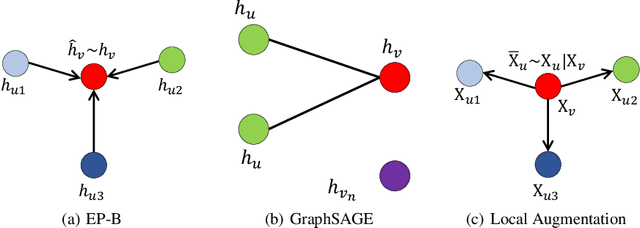

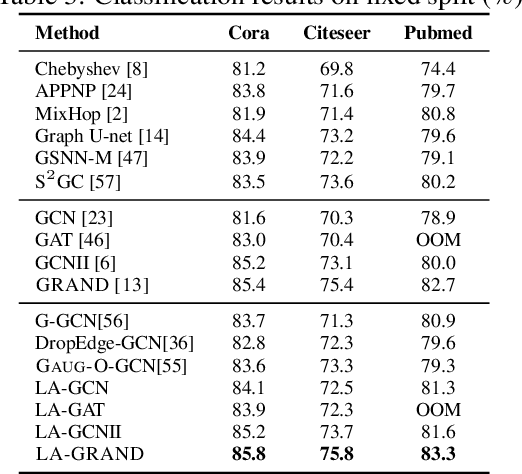
Data augmentation has been widely used in image data and linguistic data but remains under-explored on graph-structured data. Existing methods focus on augmenting the graph data from a global perspective and largely fall into two genres: structural manipulation and adversarial training with feature noise injection. However, the structural manipulation approach suffers information loss issues while the adversarial training approach may downgrade the feature quality by injecting noise. In this work, we introduce the local augmentation, which enhances node features by its local subgraph structures. Specifically, we model the data argumentation as a feature generation process. Given the central node's feature, our local augmentation approach learns the conditional distribution of its neighbors' features and generates the neighbors' optimal feature to boost the performance of downstream tasks. Based on the local augmentation, we further design a novel framework: LA-GNN, which can apply to any GNN models in a plug-and-play manner. Extensive experiments and analyses show that local augmentation consistently yields performance improvement for various GNN architectures across a diverse set of benchmarks. Code is available at https://github.com/Soughing0823/LAGNN.
FrankMocap: A Monocular 3D Whole-Body Pose Estimation System via Regression and Integration
Aug 13, 2021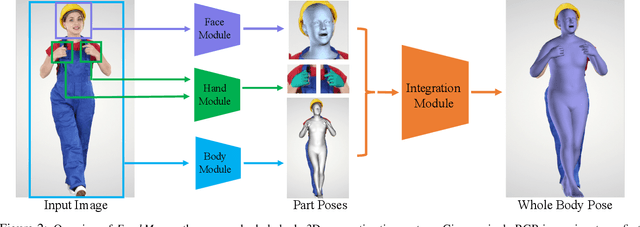
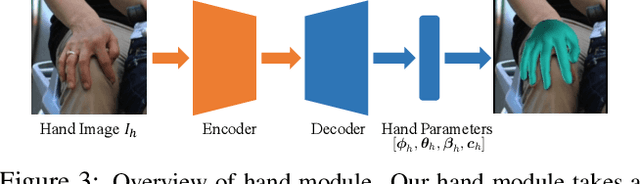
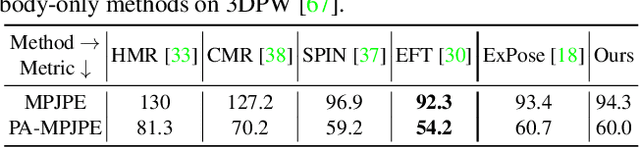

Most existing monocular 3D pose estimation approaches only focus on a single body part, neglecting the fact that the essential nuance of human motion is conveyed through a concert of subtle movements of face, hands, and body. In this paper, we present FrankMocap, a fast and accurate whole-body 3D pose estimation system that can produce 3D face, hands, and body simultaneously from in-the-wild monocular images. The core idea of FrankMocap is its modular design: We first run 3D pose regression methods for face, hands, and body independently, followed by composing the regression outputs via an integration module. The separate regression modules allow us to take full advantage of their state-of-the-art performances without compromising the original accuracy and reliability in practice. We develop three different integration modules that trade off between latency and accuracy. All of them are capable of providing simple yet effective solutions to unify the separate outputs into seamless whole-body pose estimation results. We quantitatively and qualitatively demonstrate that our modularized system outperforms both the optimization-based and end-to-end methods of estimating whole-body pose.
Frustratingly Easy Transferability Estimation
Jun 17, 2021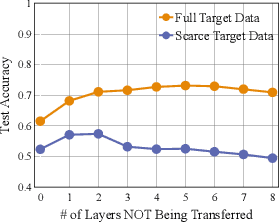
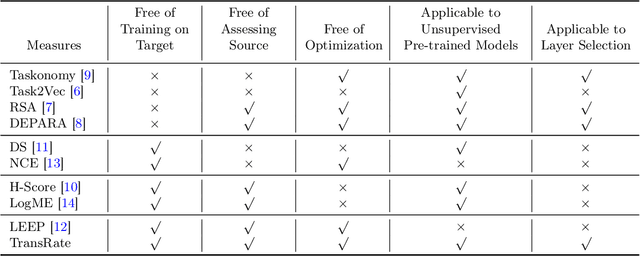
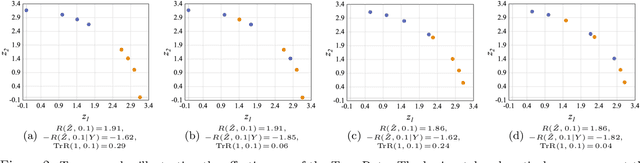
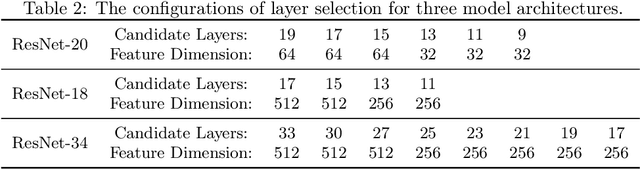
Transferability estimation has been an essential tool in selecting a pre-trained model and the layers of it to transfer, so as to maximize the performance on a target task and prevent negative transfer. Existing estimation algorithms either require intensive training on target tasks or have difficulties in evaluating the transferability between layers. We propose a simple, efficient, and effective transferability measure named TransRate. With single pass through the target data, TransRate measures the transferability as the mutual information between the features of target examples extracted by a pre-trained model and labels of them. We overcome the challenge of efficient mutual information estimation by resorting to coding rate that serves as an effective alternative to entropy. TransRate is theoretically analyzed to be closely related to the performance after transfer learning. Despite its extraordinary simplicity in 10 lines of codes, TransRate performs remarkably well in extensive evaluations on 22 pre-trained models and 16 downstream tasks.
PI-GNN: A Novel Perspective on Semi-Supervised Node Classification against Noisy Labels
Jun 14, 2021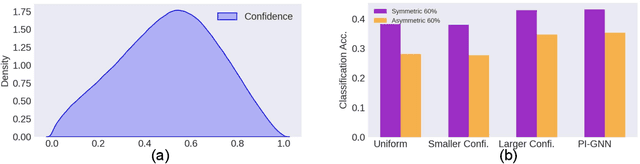
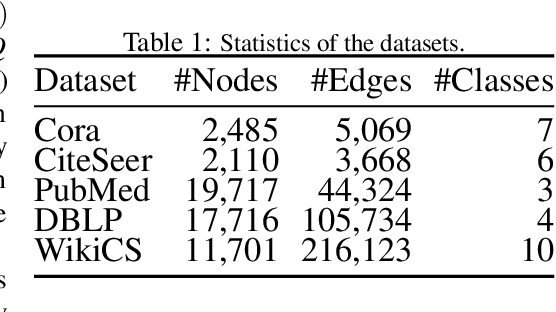
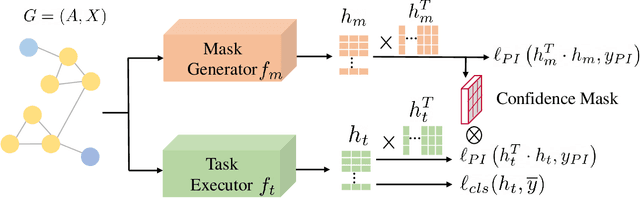
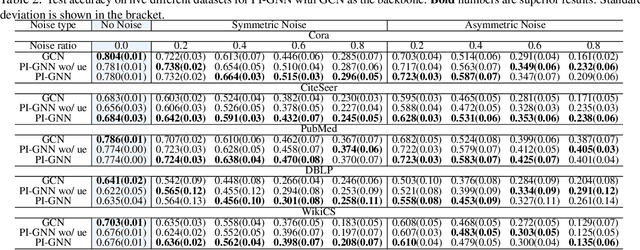
Semi-supervised node classification, as a fundamental problem in graph learning, leverages unlabeled nodes along with a small portion of labeled nodes for training. Existing methods rely heavily on high-quality labels, which, however, are expensive to obtain in real-world applications since certain noises are inevitably involved during the labeling process. It hence poses an unavoidable challenge for the learning algorithm to generalize well. In this paper, we propose a novel robust learning objective dubbed pairwise interactions (PI) for the model, such as Graph Neural Network (GNN) to combat noisy labels. Unlike classic robust training approaches that operate on the pointwise interactions between node and class label pairs, PI explicitly forces the embeddings for node pairs that hold a positive PI label to be close to each other, which can be applied to both labeled and unlabeled nodes. We design several instantiations for PI labels based on the graph structure and the node class labels, and further propose a new uncertainty-aware training technique to mitigate the negative effect of the sub-optimal PI labels. Extensive experiments on different datasets and GNN architectures demonstrate the effectiveness of PI, yielding a promising improvement over the state-of-the-art methods.