 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Geometric Graph Neural Networks: Data Structures, Models and Applications
Mar 01, 2024Geometric graph is a special kind of graph with geometric features, which is vital to model many scientific problems. Unlike generic graphs, geometric graphs often exhibit physical symmetries of translations, rotations, and reflections, making them ineffectively processed by current Graph Neural Networks (GNNs). To tackle this issue, researchers proposed a variety of Geometric Graph Neural Networks equipped with invariant/equivariant properties to better characterize the geometry and topology of geometric graphs. Given the current progress in this field, it is imperative to conduct a comprehensive survey of data structures, models, and applications related to geometric GNNs. In this paper, based on the necessary but concise mathematical preliminaries, we provide a unified view of existing models from the geometric message passing perspective. Additionally, we summarize the applications as well as the related datasets to facilitate later research for methodology development and experimental evaluation. We also discuss the challenges and future potential directions of Geometric GNNs at the end of this survey.
Long-Range Neural Atom Learning for Molecular Graphs
Nov 02, 2023



Graph Neural Networks (GNNs) have been widely adopted for drug discovery with molecular graphs. Nevertheless, current GNNs are mainly good at leveraging short-range interactions (SRI) but struggle to capture long-range interactions (LRI), both of which are crucial for determining molecular properties. To tackle this issue, we propose a method that implicitly projects all original atoms into a few Neural Atoms, which abstracts the collective information of atomic groups within a molecule. Specifically, we explicitly exchange the information among neural atoms and project them back to the atoms' representations as an enhancement. With this mechanism, neural atoms establish the communication channels among distant nodes, effectively reducing the interaction scope of arbitrary node pairs into a single hop. To provide an inspection of our method from a physical perspective, we reveal its connection with the traditional LRI calculation method, Ewald Summation. We conduct extensive experiments on three long-range graph benchmarks, covering both graph-level and link-level tasks on molecular graphs. We empirically justify that our method can be equipped with an arbitrary GNN and help to capture LRI.
Be Selfish, But Wisely: Investigating the Impact of Agent Personality in Mixed-Motive Human-Agent Interactions
Oct 22, 2023



A natural way to design a negotiation dialogue system is via self-play RL: train an agent that learns to maximize its performance by interacting with a simulated user that has been designed to imitate human-human dialogue data. Although this procedure has been adopted in prior work, we find that it results in a fundamentally flawed system that fails to learn the value of compromise in a negotiation, which can often lead to no agreements (i.e., the partner walking away without a deal), ultimately hurting the model's overall performance. We investigate this observation in the context of the DealOrNoDeal task, a multi-issue negotiation over books, hats, and balls. Grounded in negotiation theory from Economics, we modify the training procedure in two novel ways to design agents with diverse personalities and analyze their performance with human partners. We find that although both techniques show promise, a selfish agent, which maximizes its own performance while also avoiding walkaways, performs superior to other variants by implicitly learning to generate value for both itself and the negotiation partner. We discuss the implications of our findings for what it means to be a successful negotiation dialogue system and how these systems should be designed in the future.
Deep Insights into Noisy Pseudo Labeling on Graph Data
Oct 02, 2023



Pseudo labeling (PL) is a wide-applied strategy to enlarge the labeled dataset by self-annotating the potential samples during the training process. Several works have shown that it can improve the graph learning model performance in general. However, we notice that the incorrect labels can be fatal to the graph training process. Inappropriate PL may result in the performance degrading, especially on graph data where the noise can propagate. Surprisingly, the corresponding error is seldom theoretically analyzed in the literature. In this paper, we aim to give deep insights of PL on graph learning models. We first present the error analysis of PL strategy by showing that the error is bounded by the confidence of PL threshold and consistency of multi-view prediction. Then, we theoretically illustrate the effect of PL on convergence property. Based on the analysis, we propose a cautious pseudo labeling methodology in which we pseudo label the samples with highest confidence and multi-view consistency. Finally, extensive experiments demonstrate that the proposed strategy improves graph learning process and outperforms other PL strategies on link prediction and node classification tasks.
Physics-Inspired Neural Graph ODE for Long-term Dynamical Simulation
Aug 25, 2023Simulating and modeling the long-term dynamics of multi-object physical systems is an essential and challenging task. Current studies model the physical systems utilizing Graph Neural Networks (GNNs) with equivariant properties. Specifically, they model the dynamics as a sequence of discrete states with a fixed time interval and learn a direct mapping for all the two adjacent states. However, this direct mapping overlooks the continuous nature between the two states. Namely, we have verified that there are countless possible trajectories between two discrete dynamic states in current GNN-based direct mapping models. This issue greatly hinders the model generalization ability, leading to poor performance of the long-term simulation. In this paper, to better model the latent trajectory through discrete supervision signals, we propose a Physics-Inspired Neural Graph ODE (PINGO) algorithm. In PINGO, to ensure the uniqueness of the trajectory, we construct a Physics-Inspired Neural ODE framework to update the latent trajectory. Meanwhile, to effectively capture intricate interactions among objects, we use a GNN-based model to parameterize Neural ODE in a plug-and-play manner. Furthermore, we prove that the discrepancy between the learned trajectory of PIGNO and the true trajectory can be theoretically bounded. Extensive experiments verify our theoretical findings and demonstrate that our model yields an order-of-magnitude improvement over the state-of-the-art baselines, especially on long-term predictions and roll-out errors.
Structure-Aware DropEdge Towards Deep Graph Convolutional Networks
Jun 21, 2023



It has been discovered that Graph Convolutional Networks (GCNs) encounter a remarkable drop in performance when multiple layers are piled up. The main factor that accounts for why deep GCNs fail lies in over-smoothing, which isolates the network output from the input with the increase of network depth, weakening expressivity and trainability. In this paper, we start by investigating refined measures upon DropEdge -- an existing simple yet effective technique to relieve over-smoothing. We term our method as DropEdge++ for its two structure-aware samplers in contrast to DropEdge: layer-dependent sampler and feature-dependent sampler. Regarding the layer-dependent sampler, we interestingly find that increasingly sampling edges from the bottom layer yields superior performance than the decreasing counterpart as well as DropEdge. We theoretically reveal this phenomenon with Mean-Edge-Number (MEN), a metric closely related to over-smoothing. For the feature-dependent sampler, we associate the edge sampling probability with the feature similarity of node pairs, and prove that it further correlates the convergence subspace of the output layer with the input features. Extensive experiments on several node classification benchmarks, including both full- and semi- supervised tasks, illustrate the efficacy of DropEdge++ and its compatibility with a variety of backbones by achieving generally better performance over DropEdge and the no-drop version.
Vision Guided MIMO Radar Beamforming for Enhanced Vital Signs Detection in Crowds
Jun 18, 2023



Radar as a remote sensing technology has been used to analyze human activity for decades. Despite all the great features such as motion sensitivity, privacy preservation, penetrability, and more, radar has limited spatial degrees of freedom compared to optical sensors and thus makes it challenging to sense crowded environments without prior information. In this paper, we develop a novel dual-sensing system, in which a vision sensor is leveraged to guide digital beamforming in a multiple-input multiple-output (MIMO) radar. Also, we develop a calibration algorithm to align the two types of sensors and show that the calibrated dual system achieves about two centimeters precision in three-dimensional space within a field of view of $75^\circ$ by $65^\circ$ and for a range of two meters. Finally, we show that the proposed approach is capable of detecting the vital signs simultaneously for a group of closely spaced subjects, sitting and standing, in a cluttered environment, which highlights a promising direction for vital signs detection in realistic environments.
Decision Support System for Chronic Diseases Based on Drug-Drug Interactions
Mar 04, 2023



Many patients with chronic diseases resort to multiple medications to relieve various symptoms, which raises concerns about the safety of multiple medication use, as severe drug-drug antagonism can lead to serious adverse effects or even death. This paper presents a Decision Support System, called DSSDDI, based on drug-drug interactions to support doctors prescribing decisions. DSSDDI contains three modules, Drug-Drug Interaction (DDI) module, Medical Decision (MD) module and Medical Support (MS) module. The DDI module learns safer and more effective drug representations from the drug-drug interactions. To capture the potential causal relationship between DDI and medication use, the MD module considers the representations of patients and drugs as context, DDI and patients' similarity as treatment, and medication use as outcome to construct counterfactual links for the representation learning. Furthermore, the MS module provides drug candidates to doctors with explanations. Experiments on the chronic data collected from the Hong Kong Chronic Disease Study Project and a public diagnostic data MIMIC-III demonstrate that DSSDDI can be a reliable reference for doctors in terms of safety and efficiency of clinical diagnosis, with significant improvements compared to baseline methods.
Human Mobility Modeling During the COVID-19 Pandemic via Deep Graph Diffusion Infomax
Dec 12, 2022Non-Pharmaceutical Interventions (NPIs), such as social gathering restrictions, have shown effectiveness to slow the transmission of COVID-19 by reducing the contact of people. To support policy-makers, multiple studies have first modeled human mobility via macro indicators (e.g., average daily travel distance) and then studied the effectiveness of NPIs. In this work, we focus on mobility modeling and, from a micro perspective, aim to predict locations that will be visited by COVID-19 cases. Since NPIs generally cause economic and societal loss, such a micro perspective prediction benefits governments when they design and evaluate them. However, in real-world situations, strict privacy data protection regulations result in severe data sparsity problems (i.e., limited case and location information). To address these challenges, we formulate the micro perspective mobility modeling into computing the relevance score between a diffusion and a location, conditional on a geometric graph. we propose a model named Deep Graph Diffusion Infomax (DGDI), which jointly models variables including a geometric graph, a set of diffusions and a set of locations.To facilitate the research of COVID-19 prediction, we present two benchmarks that contain geometric graphs and location histories of COVID-19 cases. Extensive experiments on the two benchmarks show that DGDI significantly outperforms other competing methods.
3D Equivariant Molecular Graph Pretraining
Jul 20, 2022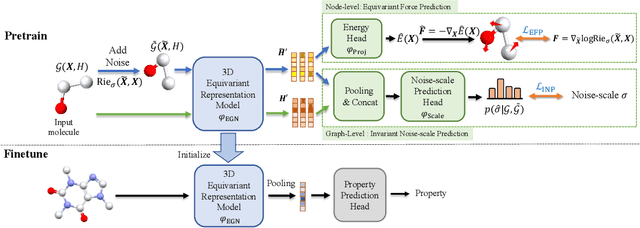
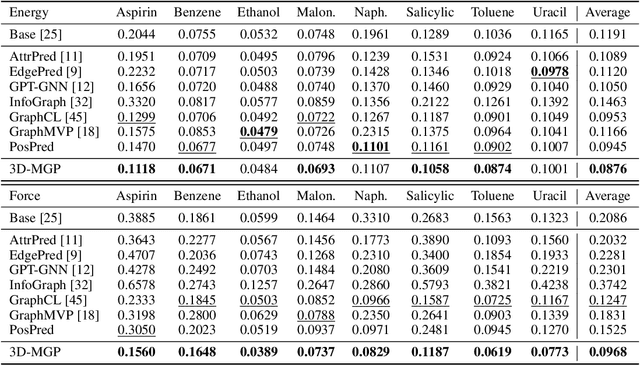
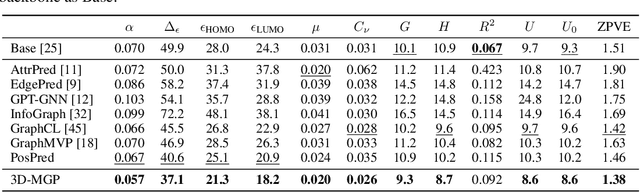
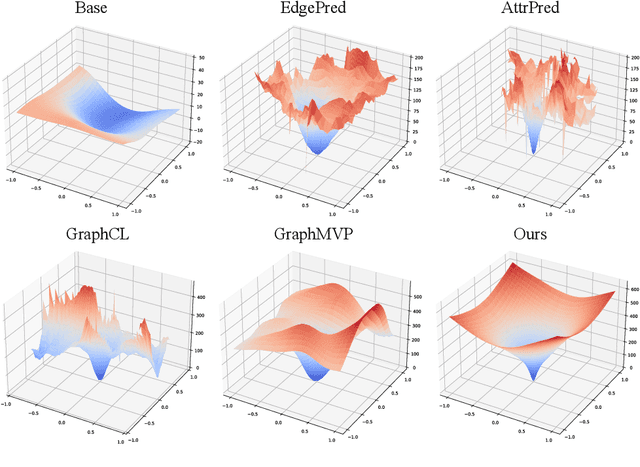
Pretraining molecular representation models without labels is fundamental to various applications. Conventional methods mainly process 2D molecular graphs and focus solely on 2D tasks, making their pretrained models incapable of characterizing 3D geometry and thus defective for downstream 3D tasks. In this work, we tackle 3D molecular pretraining in a complete and novel sense. In particular, we first propose to adopt an equivariant energy-based model as the backbone for pretraining, which enjoys the merit of fulfilling the symmetry of 3D space. Then we develop a node-level pretraining loss for force prediction, where we further exploit the Riemann-Gaussian distribution to ensure the loss to be E(3)-invariant, enabling more robustness. Moreover, a graph-level noise scale prediction task is also leveraged to further promote the eventual performance. We evaluate our model pretrained from a large-scale 3D dataset GEOM-QM9 on two challenging 3D benchmarks: MD17 and QM9. The experimental results support the better efficacy of our method against current state-of-the-art pretraining approaches, and verify the validity of our design for each proposed component.