 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsk, Don't Judge: Binary Questions for Interpretable LLM Evaluation and Self-Improvement
Jun 25, 2026Evaluating LLM outputs remains a major bottleneck in NLP: human evaluation is expensive and slow, lexical metrics correlate poorly with human judgments on open-ended generation, and holistic LLM judges often produce opaque scores that are hard to debug. We propose BINEVAL, a framework that decomposes evaluation criteria into atomic binary questions and aggregates the resulting verdicts into interpretable, multi-dimensional scores. Given a task prompt, a meta-prompt generates fine-grained evaluation questions, and an LLM answers them independently for each output, yielding transparent question-level feedback together with calibrated overall scores. This decomposition makes evaluation easier to inspect, easier to diagnose, and directly usable for prompt improvement. Across SummEval, Topical-Chat, and QAGS, BINEVAL matches or outperforms strong baselines including UniEval and G-Eval, with especially strong results on factual consistency benchmarks such as QAGS. Beyond competitive correlation with human judgments, BINEVAL better matches human score distributions and avoids the ceiling effects common in prior LLM judges, leading to better discrimination between borderline and clearly flawed outputs. We further show that the same question-level feedback supports iterative prompt optimization, improving evaluator prompts on summarization and generation prompts on IFBench under both self-update and cross-model update settings. Overall, BINEVAL provides a task-agnostic, training-free, and interpretable evaluation framework that combines strong empirical performance with practical diagnostic and optimization value.
SAFARI: Scaling Long Horizon Agentic Fault Attribution via Active Investigation
Jun 23, 2026As autonomous agents tackle increasingly complex multi-step, multi-agent tasks, their execution trajectories have scaled beyond the constraints of even the largest context windows. Current methods for effectively diagnosing agent failures load the full trajectory into an LLM's context window, which suffers from attention dilution and fails when agentic traces inevitably exceed context limits. To address this, we introduce SAFARI (Scaling long-horizon Agentic Fault AttRibution via active Investigation), a framework that replaces linear context loading with a tool-augmented diagnostic loop. By equipping LLMs with a specialized toolbox to read and search trajectory segments alongside a persistent Short-Term Memory (STM) for cross-turn reasoning, SAFARI effectively decouples diagnostic accuracy from architectural context limits. Our experiments demonstrate that SAFARI outperforms state-of-the-art results by 20% on the Who&When dataset within a 1M token budget, and by 19% on TRAIL GAIA subset on a 25K token budget. Most significantly, SAFARI maintains a 0.58 precision even when the target fault resides 5x beyond the model's native context window, a scenario where traditional evaluators fail entirely.
RECAP: Regression Evaluation for Continual Adaptation of Prompts
Jun 04, 2026Production agentic systems routinely face evolving constraints and must comply from the very next interaction. Scenarios like a tool-call notification changing a compliance threshold or a policy update adding disclosure requirements fit this criteria, having close to no room for errors in production. This proactive adaptation setting is common in deployment, but absent from current benchmarks, which assume either static constraint sets or reactive protocols with evaluation feedback. We introduce RECAP, a benchmark that measures continual-learning phenomena (forgetting, regression, forward transfer) at the constraint level under a strictly proactive adapt-then-test protocol: prompt optimization methods receive only the constraint specification and must generalize before seeing any test data. Evaluating six methods across four LLMs and three schedules with evolving constraints, we find that these methods show no significant improvement in performance, even after incurring a higher latency. These methods, designed for offline or reactive settings, are inadequate for the proactive paradigm. Our work emphasizes the growing need for designing proactive prompt adaptation methods, where the models must remain robust to evolving needs in deployment.
Lessons from the Field: An Adaptable Lifecycle Approach to Applied Dialogue Summarization
Jan 13, 2026Summarization of multi-party dialogues is a critical capability in industry, enhancing knowledge transfer and operational effectiveness across many domains. However, automatically generating high-quality summaries is challenging, as the ideal summary must satisfy a set of complex, multi-faceted requirements. While summarization has received immense attention in research, prior work has primarily utilized static datasets and benchmarks, a condition rare in practical scenarios where requirements inevitably evolve. In this work, we present an industry case study on developing an agentic system to summarize multi-party interactions. We share practical insights spanning the full development lifecycle to guide practitioners in building reliable, adaptable summarization systems, as well as to inform future research, covering: 1) robust methods for evaluation despite evolving requirements and task subjectivity, 2) component-wise optimization enabled by the task decomposition inherent in an agentic architecture, 3) the impact of upstream data bottlenecks, and 4) the realities of vendor lock-in due to the poor transferability of LLM prompts.
FB-RAG: Improving RAG with Forward and Backward Lookup
May 22, 2025The performance of Retrieval Augmented Generation (RAG) systems relies heavily on the retriever quality and the size of the retrieved context. A large enough context ensures that the relevant information is present in the input context for the LLM, but also incorporates irrelevant content that has been shown to confuse the models. On the other hand, a smaller context reduces the irrelevant information, but it often comes at the risk of losing important information necessary to answer the input question. This duality is especially challenging to manage for complex queries that contain little information to retrieve the relevant chunks from the full context. To address this, we present a novel framework, called FB-RAG, which enhances the RAG pipeline by relying on a combination of backward lookup (overlap with the query) and forward lookup (overlap with candidate reasons and answers) to retrieve specific context chunks that are the most relevant for answering the input query. Our evaluations on 9 datasets from two leading benchmarks show that FB-RAG consistently outperforms RAG and Long Context baselines developed recently for these benchmarks. We further show that FB-RAG can improve performance while reducing latency. We perform qualitative analysis of the strengths and shortcomings of our approach, providing specific insights to guide future work.
KODIS: A Multicultural Dispute Resolution Dialogue Corpus
Apr 17, 2025



We present KODIS, a dyadic dispute resolution corpus containing thousands of dialogues from over 75 countries. Motivated by a theoretical model of culture and conflict, participants engage in a typical customer service dispute designed by experts to evoke strong emotions and conflict. The corpus contains a rich set of dispositional, process, and outcome measures. The initial analysis supports theories of how anger expressions lead to escalatory spirals and highlights cultural differences in emotional expression. We make this corpus and data collection framework available to the community.
Are LLMs Effective Negotiators? Systematic Evaluation of the Multifaceted Capabilities of LLMs in Negotiation Dialogues
Feb 21, 2024



A successful negotiation demands a deep comprehension of the conversation context, Theory-of-Mind (ToM) skills to infer the partner's motives, as well as strategic reasoning and effective communication, making it challenging for automated systems. Given the remarkable performance of LLMs across a variety of NLP tasks, in this work, we aim to understand how LLMs can advance different aspects of negotiation research, ranging from designing dialogue systems to providing pedagogical feedback and scaling up data collection practices. To this end, we devise a methodology to analyze the multifaceted capabilities of LLMs across diverse dialogue scenarios covering all the time stages of a typical negotiation interaction. Our analysis adds to the increasing evidence for the superiority of GPT-4 across various tasks while also providing insights into specific tasks that remain difficult for LLMs. For instance, the models correlate poorly with human players when making subjective assessments about the negotiation dialogues and often struggle to generate responses that are contextually appropriate as well as strategically advantageous.
Investigating Content Planning for Navigating Trade-offs in Knowledge-Grounded Dialogue
Feb 03, 2024



Knowledge-grounded dialogue generation is a challenging task because it requires satisfying two fundamental yet often competing constraints: being responsive in a manner that is specific to what the conversation partner has said while also being attributable to an underlying source document. In this work, we bring this trade-off between these two objectives (specificity and attribution) to light and ask the question: Can explicit content planning before the response generation help the model to address this challenge? To answer this question, we design a framework called PLEDGE, which allows us to experiment with various plan variables explored in prior work, supporting both metric-agnostic and metric-aware approaches. While content planning shows promise, our results on whether it can actually help to navigate this trade-off are mixed -- planning mechanisms that are metric-aware (use automatic metrics during training) are better at automatic evaluations but underperform in human judgment compared to metric-agnostic mechanisms. We discuss how this may be caused by over-fitting to automatic metrics and the need for future work to better calibrate these metrics towards human judgment. We hope the observations from our analysis will inform future work that aims to apply content planning in this context.
Be Selfish, But Wisely: Investigating the Impact of Agent Personality in Mixed-Motive Human-Agent Interactions
Oct 22, 2023



A natural way to design a negotiation dialogue system is via self-play RL: train an agent that learns to maximize its performance by interacting with a simulated user that has been designed to imitate human-human dialogue data. Although this procedure has been adopted in prior work, we find that it results in a fundamentally flawed system that fails to learn the value of compromise in a negotiation, which can often lead to no agreements (i.e., the partner walking away without a deal), ultimately hurting the model's overall performance. We investigate this observation in the context of the DealOrNoDeal task, a multi-issue negotiation over books, hats, and balls. Grounded in negotiation theory from Economics, we modify the training procedure in two novel ways to design agents with diverse personalities and analyze their performance with human partners. We find that although both techniques show promise, a selfish agent, which maximizes its own performance while also avoiding walkaways, performs superior to other variants by implicitly learning to generate value for both itself and the negotiation partner. We discuss the implications of our findings for what it means to be a successful negotiation dialogue system and how these systems should be designed in the future.
Social Influence Dialogue Systems: A Scoping Survey of the Efforts Towards Influence Capabilities of Dialogue Systems
Oct 11, 2022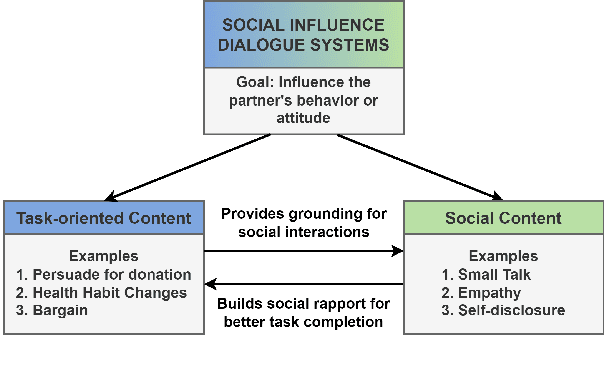
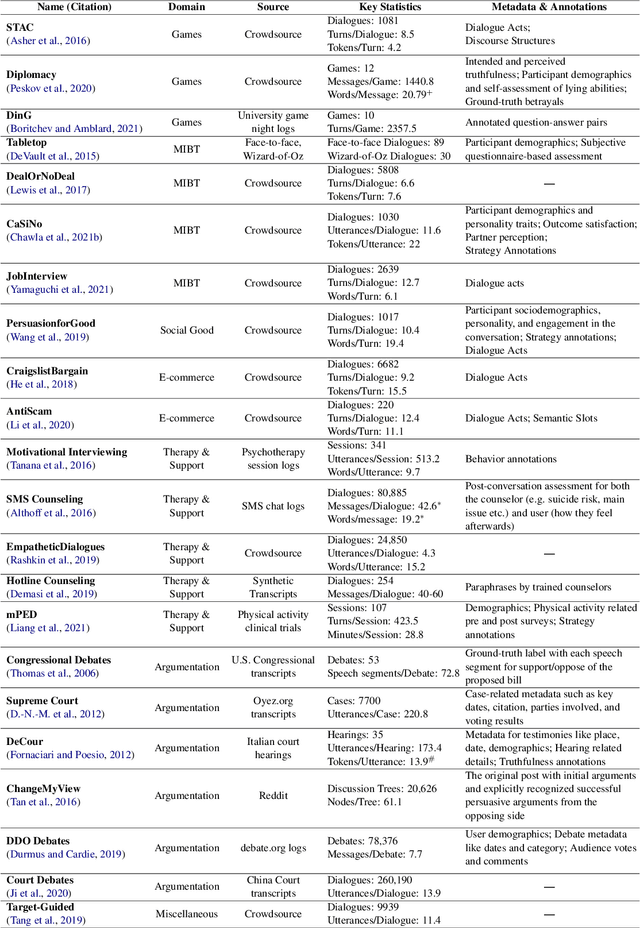
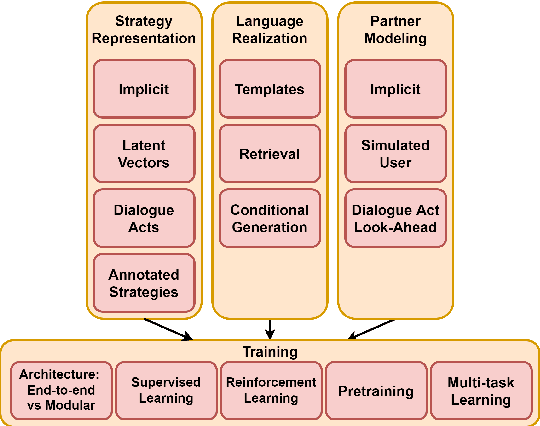
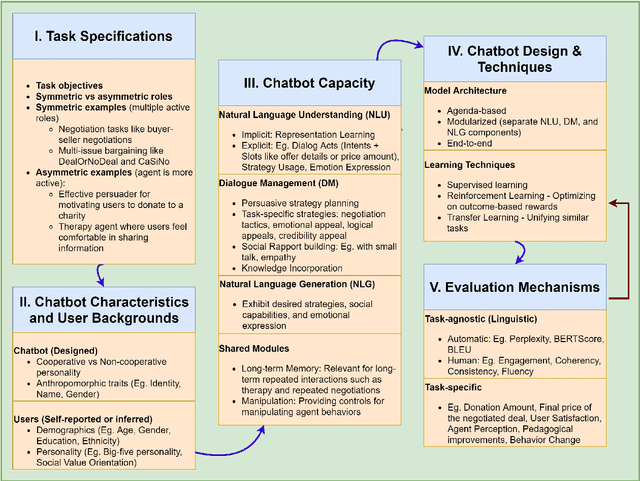
Dialogue systems capable of social influence such as persuasion, negotiation, and therapy, are essential for extending the use of technology to numerous realistic scenarios. However, existing research primarily focuses on either task-oriented or open-domain scenarios, a categorization that has been inadequate for capturing influence skills systematically. There exists no formal definition or category for dialogue systems with these skills and data-driven efforts in this direction are highly limited. In this work, we formally define and introduce the category of \emph{social influence dialogue systems} that influence users' cognitive and emotional responses, leading to changes in thoughts, opinions, and behaviors through natural conversations. We present a survey of various tasks, datasets, and methods, compiling the progress across seven diverse domains. We discuss the commonalities and differences between the examined systems, identify limitations, and recommend future directions. This study serves as a comprehensive reference for social influence dialogue systems to inspire more dedicated research and discussion in this emerging area.