 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLMs Truly Embody Human Personality? Analyzing AI and Human Behavior Alignment in Dispute Resolution
Feb 07, 2026Large language models (LLMs) are increasingly used to simulate human behavior in social settings such as legal mediation, negotiation, and dispute resolution. However, it remains unclear whether these simulations reproduce the personality-behavior patterns observed in humans. Human personality, for instance, shapes how individuals navigate social interactions, including strategic choices and behaviors in emotionally charged interactions. This raises the question: Can LLMs, when prompted with personality traits, reproduce personality-driven differences in human conflict behavior? To explore this, we introduce an evaluation framework that enables direct comparison of human-human and LLM-LLM behaviors in dispute resolution dialogues with respect to Big Five Inventory (BFI) personality traits. This framework provides a set of interpretable metrics related to strategic behavior and conflict outcomes. We additionally contribute a novel dataset creation methodology for LLM dispute resolution dialogues with matched scenarios and personality traits with respect to human conversations. Finally, we demonstrate the use of our evaluation framework with three contemporary closed-source LLMs and show significant divergences in how personality manifests in conflict across different LLMs compared to human data, challenging the assumption that personality-prompted agents can serve as reliable behavioral proxies in socially impactful applications. Our work highlights the need for psychological grounding and validation in AI simulations before real-world use.
ASTRA: A Negotiation Agent with Adaptive and Strategic Reasoning through Action in Dynamic Offer Optimization
Mar 10, 2025



Negotiation requires dynamically balancing self-interest and cooperation to maximize one's own utility. Yet, existing agents struggle due to bounded rationality in human data, low adaptability to counterpart behavior, and limited strategic reasoning. To address this, we introduce principle-driven negotiation agents, powered by ASTRA, a novel framework for turn-level offer optimization grounded in two core principles: opponent modeling and Tit-for-Tat reciprocity. ASTRA operates in three stages: (1) interpreting counterpart behavior, (2) optimizing counteroffers via a linear programming (LP) solver, and (3) selecting offers based on negotiation tactics and the partner's acceptance probability. Through simulations and human evaluations, our agent effectively adapts to an opponent's shifting stance and achieves favorable outcomes through enhanced adaptability and strategic reasoning. Beyond improving negotiation performance, it also serves as a powerful coaching tool, offering interpretable strategic feedback and optimal offer recommendations.
Enhancing Building Safety Design for Active Shooter Incidents: Exploration of Building Exit Parameters using Reinforcement Learning-Based Simulations
Jul 15, 2024



With the alarming rise in active shooter incidents (ASIs) in the United States, enhancing public safety through building design has become a pressing need. This study proposes a reinforcement learning-based simulation approach addressing gaps in existing research that has neglected the dynamic behaviours of shooters. We developed an autonomous agent to simulate an active shooter within a realistic office environment, aiming to offer insights into the interactions between building design parameters and ASI outcomes. A case study is conducted to quantitatively investigate the impact of building exit numbers (total count of accessible exits) and configuration (arrangement of which exits are available or not) on evacuation and harm rates. Findings demonstrate that greater exit availability significantly improves evacuation outcomes and reduces harm. Exits nearer to the shooter's initial position hold greater importance for accessibility than those farther away. By encompassing dynamic shooter behaviours, this study offers preliminary insights into effective building safety design against evolving threats.
Are LLMs Effective Negotiators? Systematic Evaluation of the Multifaceted Capabilities of LLMs in Negotiation Dialogues
Feb 21, 2024



A successful negotiation demands a deep comprehension of the conversation context, Theory-of-Mind (ToM) skills to infer the partner's motives, as well as strategic reasoning and effective communication, making it challenging for automated systems. Given the remarkable performance of LLMs across a variety of NLP tasks, in this work, we aim to understand how LLMs can advance different aspects of negotiation research, ranging from designing dialogue systems to providing pedagogical feedback and scaling up data collection practices. To this end, we devise a methodology to analyze the multifaceted capabilities of LLMs across diverse dialogue scenarios covering all the time stages of a typical negotiation interaction. Our analysis adds to the increasing evidence for the superiority of GPT-4 across various tasks while also providing insights into specific tasks that remain difficult for LLMs. For instance, the models correlate poorly with human players when making subjective assessments about the negotiation dialogues and often struggle to generate responses that are contextually appropriate as well as strategically advantageous.
Be Selfish, But Wisely: Investigating the Impact of Agent Personality in Mixed-Motive Human-Agent Interactions
Oct 22, 2023



A natural way to design a negotiation dialogue system is via self-play RL: train an agent that learns to maximize its performance by interacting with a simulated user that has been designed to imitate human-human dialogue data. Although this procedure has been adopted in prior work, we find that it results in a fundamentally flawed system that fails to learn the value of compromise in a negotiation, which can often lead to no agreements (i.e., the partner walking away without a deal), ultimately hurting the model's overall performance. We investigate this observation in the context of the DealOrNoDeal task, a multi-issue negotiation over books, hats, and balls. Grounded in negotiation theory from Economics, we modify the training procedure in two novel ways to design agents with diverse personalities and analyze their performance with human partners. We find that although both techniques show promise, a selfish agent, which maximizes its own performance while also avoiding walkaways, performs superior to other variants by implicitly learning to generate value for both itself and the negotiation partner. We discuss the implications of our findings for what it means to be a successful negotiation dialogue system and how these systems should be designed in the future.
Opponent Modeling in Negotiation Dialogues by Related Data Adaptation
May 03, 2022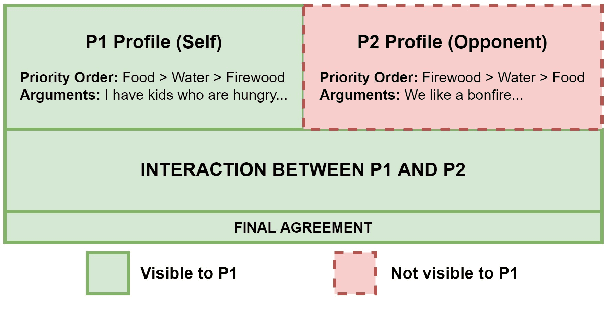
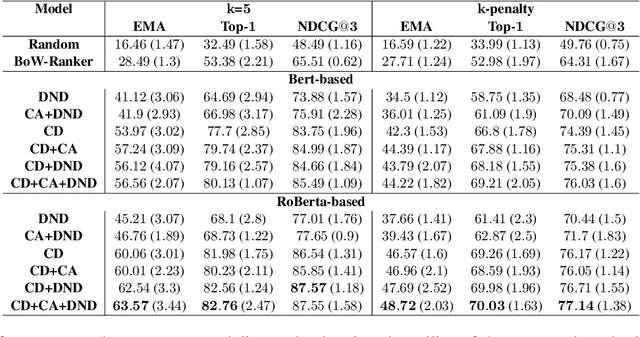
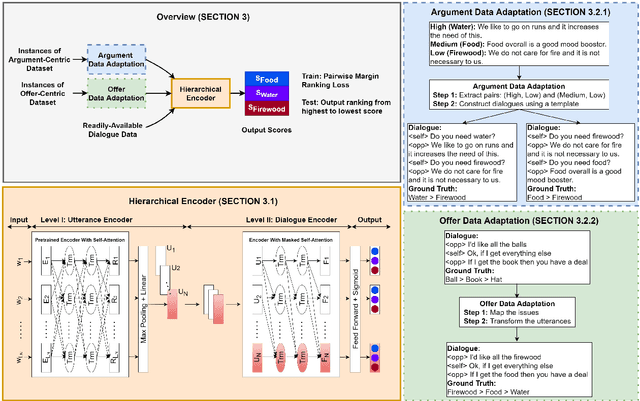

Opponent modeling is the task of inferring another party's mental state within the context of social interactions. In a multi-issue negotiation, it involves inferring the relative importance that the opponent assigns to each issue under discussion, which is crucial for finding high-value deals. A practical model for this task needs to infer these priorities of the opponent on the fly based on partial dialogues as input, without needing additional annotations for training. In this work, we propose a ranker for identifying these priorities from negotiation dialogues. The model takes in a partial dialogue as input and predicts the priority order of the opponent. We further devise ways to adapt related data sources for this task to provide more explicit supervision for incorporating the opponent's preferences and offers, as a proxy to relying on granular utterance-level annotations. We show the utility of our proposed approach through extensive experiments based on two dialogue datasets. We find that the proposed data adaptations lead to strong performance in zero-shot and few-shot scenarios. Moreover, they allow the model to perform better than baselines while accessing fewer utterances from the opponent. We release our code to support future work in this direction.