 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting Large-scale Parallel Training Efficiency with C4: A Communication-Driven Approach
Jun 07, 2024



The emergence of Large Language Models (LLMs) has necessitated the adoption of parallel training techniques, involving the deployment of thousands of GPUs to train a single model. Unfortunately, we have found that the efficiency of current parallel training is often suboptimal, largely due to the following two main issues. Firstly, hardware failures are inevitable, leading to interruptions in the training tasks. The inability to quickly identify the faulty components results in a substantial waste of GPU resources. Secondly, since GPUs must wait for parameter synchronization to complete before proceeding to the next round of computation, network congestions can greatly increase the waiting time for GPUs. To address these challenges, this paper introduces a communication-driven solution, namely the C4. The key insights of C4 are two folds. First, in parallel training, collective communication exhibits periodic and homogeneous characteristics, so any anomalies are certainly due to some form of hardware malfunction. By leveraging this feature, C4 can rapidly identify the faulty components, swiftly isolate the anomaly, and restart the task, thereby avoiding resource wastage caused by delays in anomaly detection. Second, the predictable communication model of collective communication, involving few large flows, allows C4 to efficiently execute traffic planning, substantially reducing network congestion. C4 has been extensively implemented across our production systems, cutting error-induced overhead by roughly 30% and enhancing runtime performance by about 15% for certain applications with moderate communication costs.
Synthetic CT Generation via Variant Invertible Network for All-digital Brain PET Attenuation Correction
Oct 03, 2023



Attenuation correction (AC) is essential for the generation of artifact-free and quantitatively accurate positron emission tomography (PET) images. However, AC of PET faces challenges including inter-scan motion and erroneous transformation of structural voxel-intensities to PET attenuation-correction factors. Nowadays, the problem of AC for quantitative PET have been solved to a large extent after the commercial availability of devices combining PET with computed tomography (CT). Meanwhile, considering the feasibility of a deep learning approach for PET AC without anatomical imaging, this paper develops a PET AC method, which uses deep learning to generate continuously valued CT images from non-attenuation corrected PET images for AC on brain PET imaging. Specifically, an invertible network combined with the variable augmentation strategy that can achieve the bidirectional inference processes is proposed for synthetic CT generation (IVNAC). To evaluate the performance of the proposed algorithm, we conducted a comprehensive study on a total of 1440 data from 37 clinical patients using comparative algorithms (such as Cycle-GAN and Pix2pix). Perceptual analysis and quantitative evaluations illustrate that the invertible network for PET AC outperforms other existing AC models, which demonstrates the potential of the proposed method and the feasibility of achieving brain PET AC without CT.
Correlated and Multi-frequency Diffusion Modeling for Highly Under-sampled MRI Reconstruction
Sep 02, 2023



Most existing MRI reconstruction methods perform tar-geted reconstruction of the entire MR image without tak-ing specific tissue regions into consideration. This may fail to emphasize the reconstruction accuracy on im-portant tissues for diagnosis. In this study, leveraging a combination of the properties of k-space data and the diffusion process, our novel scheme focuses on mining the multi-frequency prior with different strategies to pre-serve fine texture details in the reconstructed image. In addition, a diffusion process can converge more quickly if its target distribution closely resembles the noise distri-bution in the process. This can be accomplished through various high-frequency prior extractors. The finding further solidifies the effectiveness of the score-based gen-erative model. On top of all the advantages, our method improves the accuracy of MRI reconstruction and accel-erates sampling process. Experimental results verify that the proposed method successfully obtains more accurate reconstruction and outperforms state-of-the-art methods.
ConvBoost: Boosting ConvNets for Sensor-based Activity Recognition
May 22, 2023



Human activity recognition (HAR) is one of the core research themes in ubiquitous and wearable computing. With the shift to deep learning (DL) based analysis approaches, it has become possible to extract high-level features and perform classification in an end-to-end manner. Despite their promising overall capabilities, DL-based HAR may suffer from overfitting due to the notoriously small, often inadequate, amounts of labeled sample data that are available for typical HAR applications. In response to such challenges, we propose ConvBoost -- a novel, three-layer, structured model architecture and boosting framework for convolutional network based HAR. Our framework generates additional training data from three different perspectives for improved HAR, aiming to alleviate the shortness of labeled training data in the field. Specifically, with the introduction of three conceptual layers--Sampling Layer, Data Augmentation Layer, and Resilient Layer -- we develop three "boosters" -- R-Frame, Mix-up, and C-Drop -- to enrich the per-epoch training data by dense-sampling, synthesizing, and simulating, respectively. These new conceptual layers and boosters, that are universally applicable for any kind of convolutional network, have been designed based on the characteristics of the sensor data and the concept of frame-wise HAR. In our experimental evaluation on three standard benchmarks (Opportunity, PAMAP2, GOTOV) we demonstrate the effectiveness of our ConvBoost framework for HAR applications based on variants of convolutional networks: vanilla CNN, ConvLSTM, and Attention Models. We achieved substantial performance gains for all of them, which suggests that the proposed approach is generic and can serve as a practical solution for boosting the performance of existing ConvNet-based HAR models. This is an open-source project, and the code can be found at https://github.com/sshao2013/ConvBoost
* 21 pages
Simple Yet Surprisingly Effective Training Strategies for LSTMs in Sensor-Based Human Activity Recognition
Dec 23, 2022



Human Activity Recognition (HAR) is one of the core research areas in mobile and wearable computing. With the application of deep learning (DL) techniques such as CNN, recognizing periodic or static activities (e.g, walking, lying, cycling, etc.) has become a well studied problem. What remains a major challenge though is the sporadic activity recognition (SAR) problem, where activities of interest tend to be non periodic, and occur less frequently when compared with the often large amount of irrelevant background activities. Recent works suggested that sequential DL models (such as LSTMs) have great potential for modeling nonperiodic behaviours, and in this paper we studied some LSTM training strategies for SAR. Specifically, we proposed two simple yet effective LSTM variants, namely delay model and inverse model, for two SAR scenarios (with and without time critical requirement). For time critical SAR, the delay model can effectively exploit predefined delay intervals (within tolerance) in form of contextual information for improved performance. For regular SAR task, the second proposed, inverse model can learn patterns from the time series in an inverse manner, which can be complementary to the forward model (i.e.,LSTM), and combining both can boost the performance. These two LSTM variants are very practical, and they can be deemed as training strategies without alteration of the LSTM fundamentals. We also studied some additional LSTM training strategies, which can further improve the accuracy. We evaluated our models on two SAR and one non-SAR datasets, and the promising results demonstrated the effectiveness of our approaches in HAR applications.
Universal Generative Modeling in Dual-domain for Dynamic MR Imaging
Dec 15, 2022



Dynamic magnetic resonance image reconstruction from incomplete k-space data has generated great research interest due to its capability to reduce scan time. Never-theless, the reconstruction problem is still challenging due to its ill-posed nature. Recently, diffusion models espe-cially score-based generative models have exhibited great potential in algorithm robustness and usage flexi-bility. Moreover, the unified framework through the variance exploding stochastic differential equation (VE-SDE) is proposed to enable new sampling methods and further extend the capabilities of score-based gener-ative models. Therefore, by taking advantage of the uni-fied framework, we proposed a k-space and image Du-al-Domain collaborative Universal Generative Model (DD-UGM) which combines the score-based prior with low-rank regularization penalty to reconstruct highly under-sampled measurements. More precisely, we extract prior components from both image and k-space domains via a universal generative model and adaptively handle these prior components for faster processing while maintaining good generation quality. Experimental comparisons demonstrated the noise reduction and detail preservation abilities of the proposed method. Much more than that, DD-UGM can reconstruct data of differ-ent frames by only training a single frame image, which reflects the flexibility of the proposed model.
Part-aware Prototypical Graph Network for One-shot Skeleton-based Action Recognition
Aug 19, 2022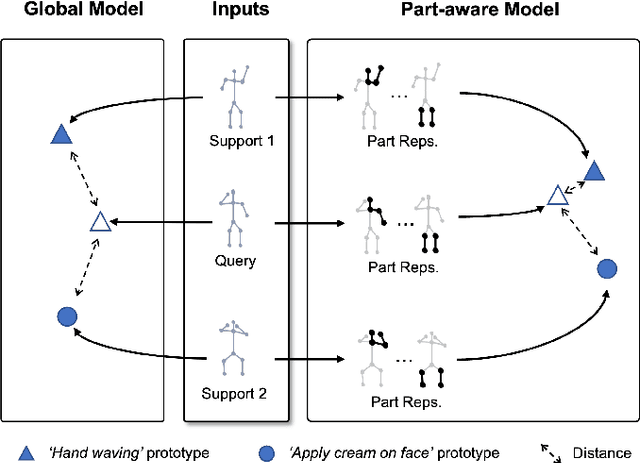
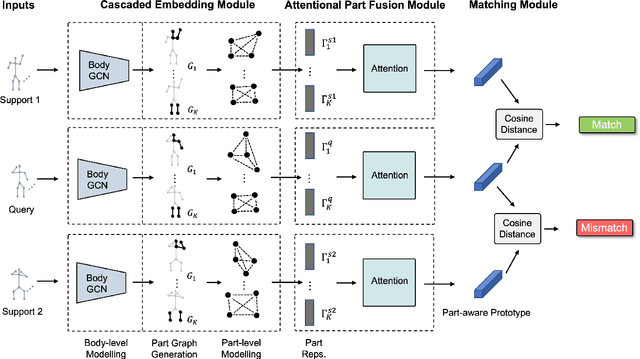
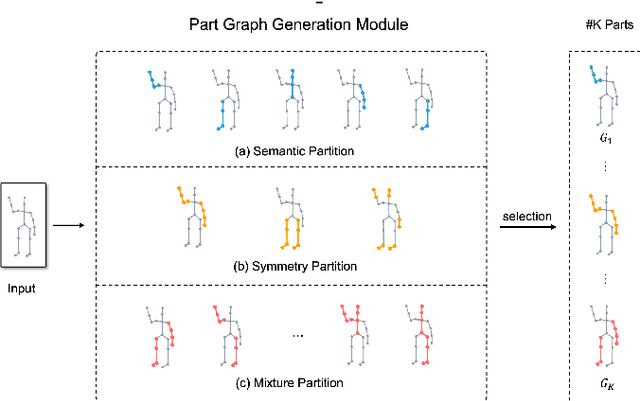
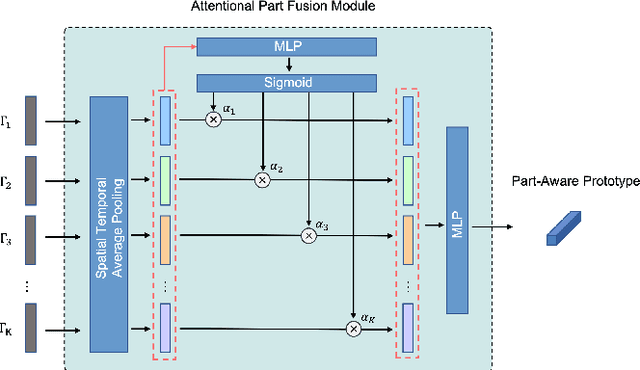
In this paper, we study the problem of one-shot skeleton-based action recognition, which poses unique challenges in learning transferable representation from base classes to novel classes, particularly for fine-grained actions. Existing meta-learning frameworks typically rely on the body-level representations in spatial dimension, which limits the generalisation to capture subtle visual differences in the fine-grained label space. To overcome the above limitation, we propose a part-aware prototypical representation for one-shot skeleton-based action recognition. Our method captures skeleton motion patterns at two distinctive spatial levels, one for global contexts among all body joints, referred to as body level, and the other attends to local spatial regions of body parts, referred to as the part level. We also devise a class-agnostic attention mechanism to highlight important parts for each action class. Specifically, we develop a part-aware prototypical graph network consisting of three modules: a cascaded embedding module for our dual-level modelling, an attention-based part fusion module to fuse parts and generate part-aware prototypes, and a matching module to perform classification with the part-aware representations. We demonstrate the effectiveness of our method on two public skeleton-based action recognition datasets: NTU RGB+D 120 and NW-UCLA.
Action Quality Assessment with Temporal Parsing Transformer
Jul 19, 2022
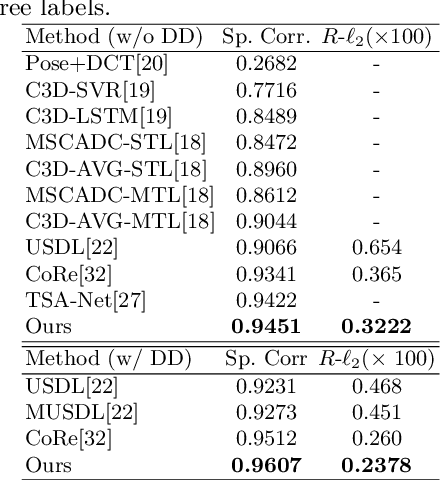
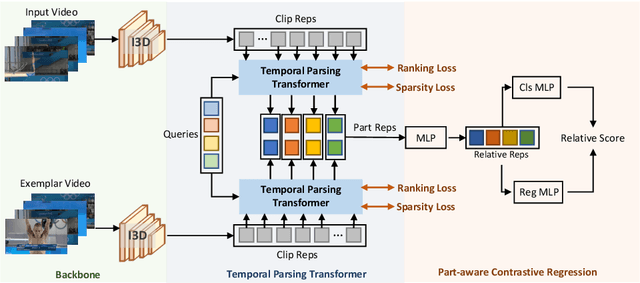
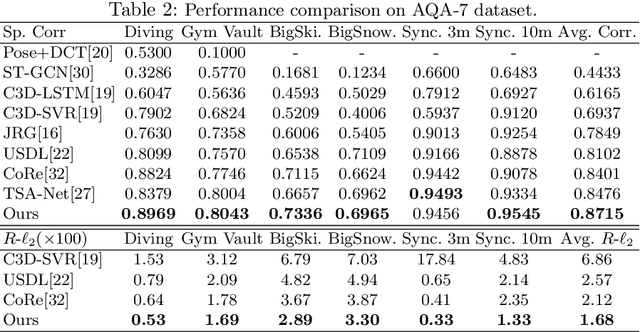
Action Quality Assessment(AQA) is important for action understanding and resolving the task poses unique challenges due to subtle visual differences. Existing state-of-the-art methods typically rely on the holistic video representations for score regression or ranking, which limits the generalization to capture fine-grained intra-class variation. To overcome the above limitation, we propose a temporal parsing transformer to decompose the holistic feature into temporal part-level representations. Specifically, we utilize a set of learnable queries to represent the atomic temporal patterns for a specific action. Our decoding process converts the frame representations to a fixed number of temporally ordered part representations. To obtain the quality score, we adopt the state-of-the-art contrastive regression based on the part representations. Since existing AQA datasets do not provide temporal part-level labels or partitions, we propose two novel loss functions on the cross attention responses of the decoder: a ranking loss to ensure the learnable queries to satisfy the temporal order in cross attention and a sparsity loss to encourage the part representations to be more discriminative. Extensive experiments show that our proposed method outperforms prior work on three public AQA benchmarks by a considerable margin.
On the development of a Bayesian optimisation framework for complex unknown systems
Jul 19, 2022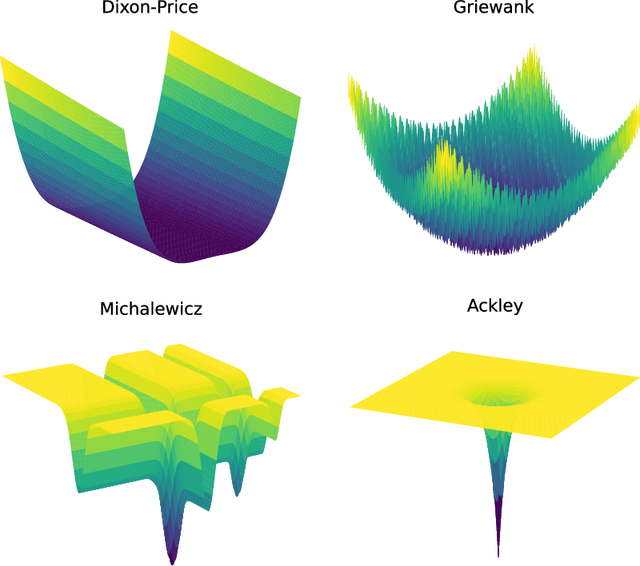
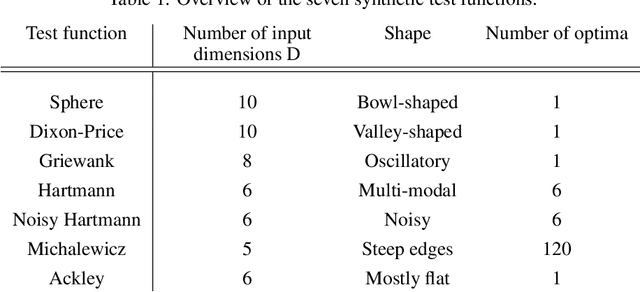
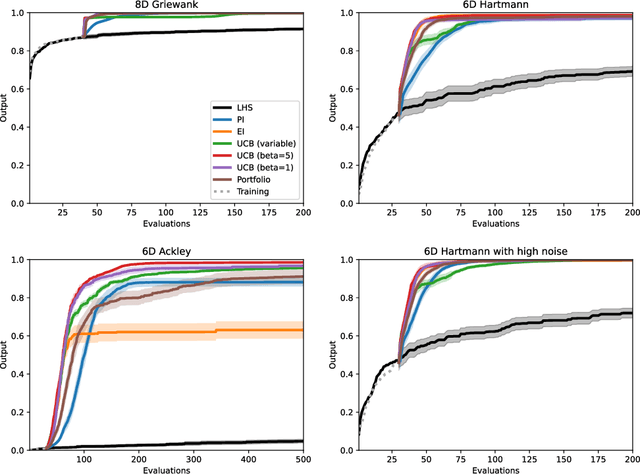
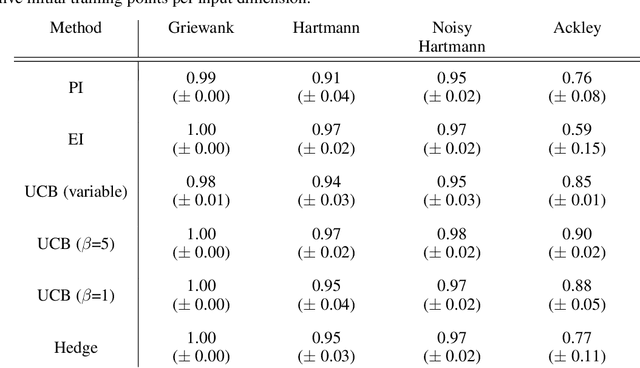
Bayesian optimisation provides an effective method to optimise expensive black box functions. It has recently been applied to problems in fluid dynamics. This paper studies and compares common Bayesian optimisation algorithms empirically on a range of synthetic test functions. It investigates the choice of acquisition function and number of training samples, exact calculation of acquisition functions and Monte Carlo based approaches and both single-point and multi-point optimisation. The test functions considered cover a wide selection of challenges and therefore serve as an ideal test bed to understand the performance of Bayesian optimisation and to identify general situations where Bayesian optimisation performs well and poorly. This knowledge can be utilised in applications, including those in fluid dynamics, where objective functions are unknown. The results of this investigation show that the choices to be made are less relevant for relatively simple functions, while optimistic acquisition functions such as Upper Confidence Bound should be preferred for more complex objective functions. Furthermore, results from the Monte Carlo approach are comparable to results from analytical acquisition functions. In instances where the objective function allows parallel evaluations, the multi-point approach offers a quicker alternative, yet it may potentially require more objective function evaluations.
K-space and Image Domain Collaborative Energy based Model for Parallel MRI Reconstruction
Mar 21, 2022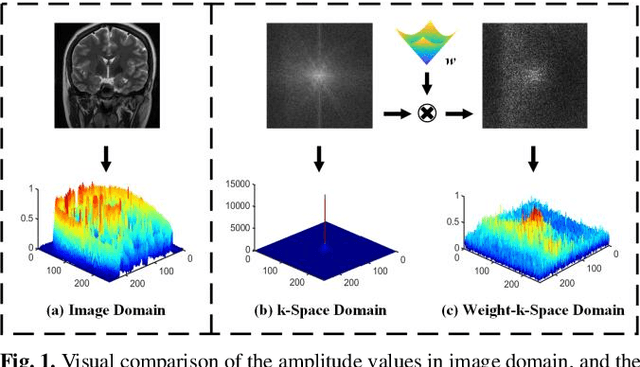
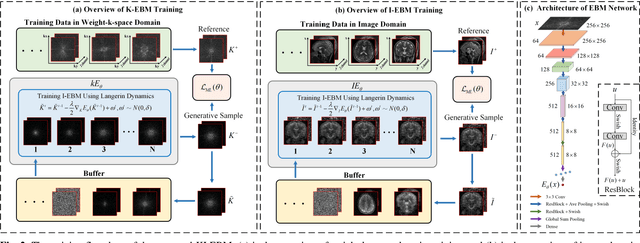
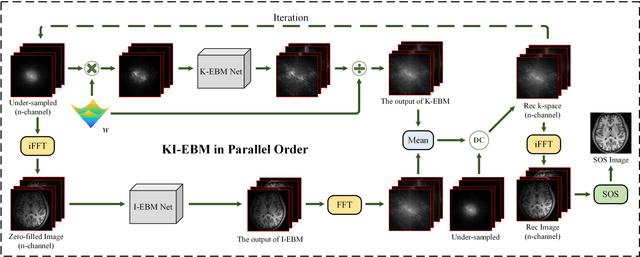
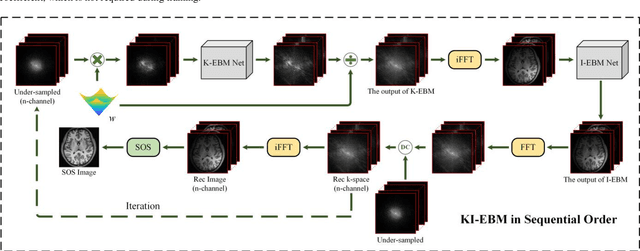
Decreasing magnetic resonance (MR) image acquisition times can potentially make MR examinations more accessible. Prior arts including the deep learning models have been devoted to solving the problem of long MRI imaging time. Recently, deep generative models have exhibited great potentials in algorithm robustness and usage flexibility. Nevertheless, no existing such schemes that can be learned or employed directly to the k-space measurement. Furthermore, how do the deep generative models work well in hybrid domain is also worth to be investigated. In this work, by taking advantage of the deep en-ergy-based models, we propose a k-space and image domain collaborative generative model to comprehensively estimate the MR data from under-sampled measurement. Experimental comparisons with the state-of-the-arts demonstrated that the proposed hybrid method has less error in reconstruction and is more stable under different acceleration factors.